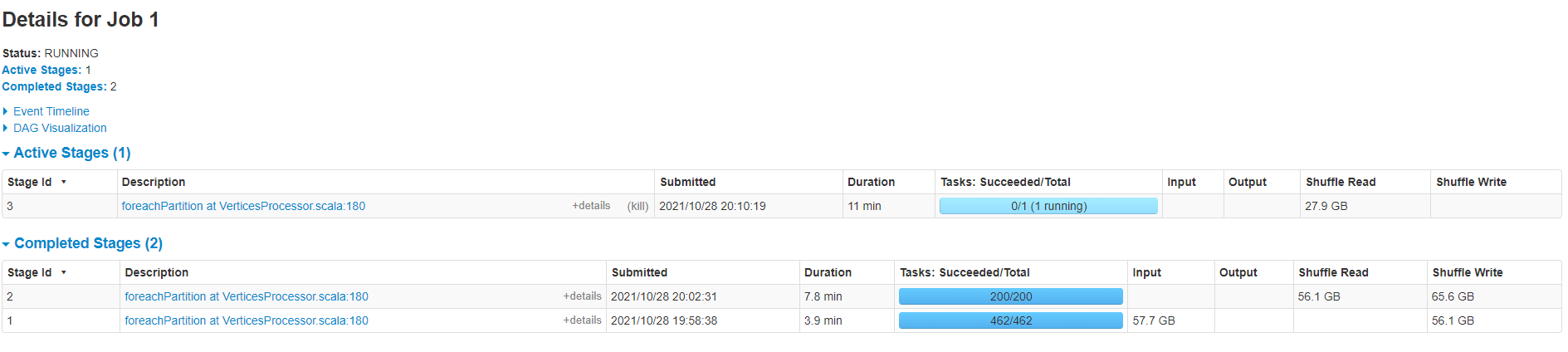
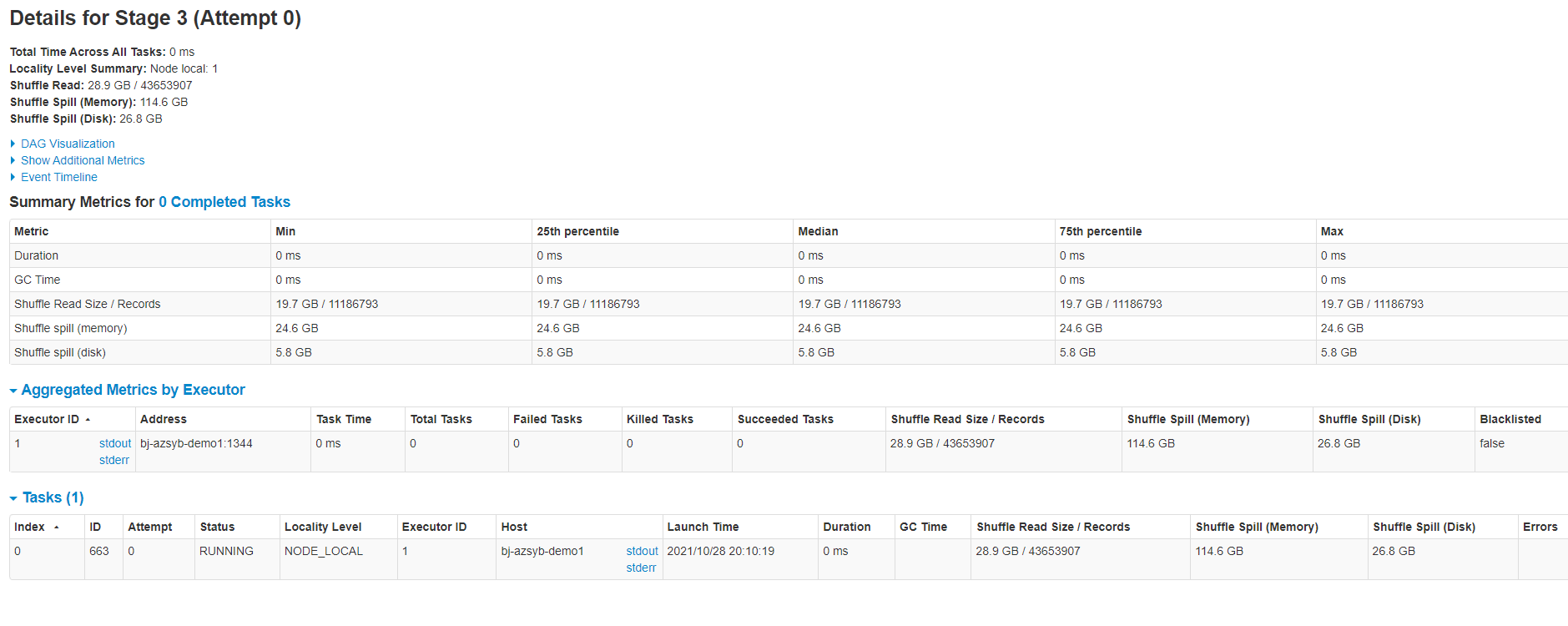
已使用2.5.2版本。大部分时间都在执行这个排序阶段,且貌似仅有一个线程排序。
执行方式如下:
/bin/spark-submit --master yarn --deploy-mode cluster --class com.vesoft.nebula.exchange.Exchange --files export_sst.applications --conf "spark.executor.extraJavaOptions=-XX:MaxPermSize=1024M" --driver-java-options -XX:MaxPermSize=2048m --driver-memory 4g --executor-memory 6G --executor-cores 8 --num-executors 16 --conf spark.driver.extraClassPath=/opt/cloudera/parcels/CDH/lib/spark/jars/guava-14.0.1.jar --conf spark.executor.extraClassPath=/opt/cloudera/parcels/CDH/lib/spark/jars/guava-14.0.1.jar nebula-exchange-2.5.2.jar -c export_sst.applications
配置文件如下:
{
# Spark相关配置
spark: {
app: {
name: Nebula Exchange 2.0
}
master:yarn
driver: {
cores: 4
maxResultSize: 4G
}
executor: {
memory:8G
}
cores:{
max: 16
}
}
# Nebula Graph相关配置
nebula: {
address:{
graph:["192.168.7.192:8069","192.168.7.187:8069","192.168.7.185:8069"]
meta:["192.168.7.178:9559"]
}
user: ***
pswd: ***
space: gan_test14
# SST文件相关配置
path:{
# 本地临时存放生成的SST文件的目录
local:"/tmp"
# SST文件在HDFS的存储路径
remote:"/sst"
# HDFS的NameNode地址
hdfs.namenode: "hdfs://jb-syb-demo2.cloud.onecloud.io:8020"
}
# 客户端连接参数
connection {
# socket连接、执行的超时时间,单位:毫秒。
timeout: 120000
}
error: {
# 最大失败数,超过后会退出应用程序。
max: 32
# 失败的导入作业将记录在输出路径中。
output: /tmp/errors
}
# 使用谷歌的RateLimiter来限制发送到NebulaGraph的请求。
rate: {
# RateLimiter的稳定吞吐量。
limit: 2024
# 从RateLimiter获取允许的超时时间,单位:毫秒
timeout: 120000
}
}
# 处理点
tags: [
# 设置Tag player相关信息。
{
# 指定Nebula Graph中定义的Tag名称。
name: person2
type: {
# 指定数据源,使用CSV。
source: csv
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: sst
}
# 指定CSV文件的路径。
# 文件存储在HDFS上,用双引号括起路径,以hdfs://开头,例如"hdfs://ip:port/xx/xx"。
path: "hdfs://jb-syb-demo2.cloud.onecloud.io:8020/user/hive/warehouse/person/person_complex_1y.csv"
# 如果CSV文件没有表头,使用[_c0, _c1, _c2, ..., _cn]表示其表头,并将列指示为属性值的源。
# 如果CSV文件有表头,则使用实际的列名。
fields: [_c0, _c1, _c2, _c3, _c4, _c5, _c6, _c7, _c8, _c9, _c10, _c11, _c12, _c13, _c14, _c15, _c16, _c17, _c18, _c19, _c20, _c21, _c22, _c23, _c24, _c25, _c26, _c27, _c28, _c29, _c30, _c31, _c32, _c33, _c34, _c35, _c36, _c37, _c38, _c39, _c40, _c41, _c42, _c43, _c44, _c45, _c46, _c47, _c48, _c49, _c50, _c51, _c52, _c53, _c54, _c55, _c56, _c57, _c58, _c59, _c60, _c61, _c62, _c63, _c64, _c65, _c66, _c67, _c68, _c69, _c70, _c71, _c72, _c73, _c74, _c75, _c76, _c77, _c78, _c79, _c80, _c81, _c82, _c83, _c84, _c85, _c86, _c87, _c88, _c89, _c90, _c91, _c92, _c93, _c94, _c95, _c96, _c97, _c98, _c99, _c100, _c101, _c102, _c103, _c104, _c105, _c106, _c107, _c108, _c109, _c110, _c111, _c112, _c113, _c114, _c115, _c116, _c117, _c118, _c119, _c120, _c121, _c122, _c123, _c124, _c125, _c126, _c127, _c128, _c129, _c130, _c131, _c132, _c133, _c134, _c135, _c136, _c137, _c138, _c139, _c140, _c141, _c142, _c143, _c144, _c145, _c146, _c147, _c148, _c149, _c150, _c151]
nebula.fields: [xxzjbh,rybh,yy_hklbdm,gllbdm,ryzzbdbh,xm,xmhypy,cym,cympy,xbdm,csrq,gmsfhm,xxdm,mzdm,zjxydm,xldm,hyzkdm,zzmmdm,byzkdm,tsrqdm,zylbdm,zy,zw,zcdm,fwcs,fwcdzmc,lxdh,hkszdlxdm,hjdz_jyqk,hjdz_xzqhdm,hjdz_dzmc,hjdpcs_gajgjgdm,zzbh,xzz_jyqk,xzz_xzqhdm,xzz_dzmc,xzzpcs_gajgjgdm,xzzzazrr_xm,jzzbh,dzxx,qq_fwbzh,sfjy_pdbz,jy_jyqk,gzdw_dwmc,gzdw_dzmc,gzdw_lxdh,cblxdm,htlxdm,sbkh,sfblylbx_pdbz,ylbxbl_kssj,sfblgsbx_pdbz,gsbxbl_kssj,sfblsybx_pdbz,sybxbl_kssj,sfghhy_pdbz,sffqtx_pdbz,xxry_rs,xxzn_rs,sfcj_pdbz,cjlxdm,cj_jyqk,ywsxcl_pdbz,sxcl_cllxdm,sxcl_jdchphm,sfsy_pdbz,hyzmbh,hyzm_fzjg_dwmc,hyzm_fzrq,synh_rs,synvh_rs,sfcqjycs_pdbz,jycs_jyqk,jysj,wbyyy_jyqk,ywjhsyzm_pdbz,sftbjsbm_pdbz,jqsfjzym_pdbz,qrlrrq,lzd_jyqk,lzd_gjhdqdm,lzd_xzqhdm,lzd_dzmc,jzsydm,jzfsdm,jzcsdm,njzsjdm,yhzgx_jyqk,sfzyfw_pdbz,yfzgx_rygxdm,fz_xm,fz_gmsfhm,fzlldm,bfdxdm,hdqkdm,jzzblqkdm,jzz_qfrq,jzzyxqxdm,jzz_yxqqsrq,jzz_yxqjzrq,jzzyq_qsrq,jzzyq_jzrq,fq_xm,fq_gmsfhm,mq_xm,mq_gmsfhm,po_xm,po_gmsfhm,jhr_jhgxdm,jhr_xm,jhr_xmhypy,jhr_gmsfhm,gzdzazrr_xm,gzdzazrr_yddh,gzdzazrr_gddh,qwd_jyqk,qwd_gjhdqdm,qwd_xzqhdm,qwd_dzmc,hc_pdbz,syqkdm,hfrq,wfxydj_jyqk,elrkwfxydj_jyqk,zdqs_pdbz,sssq_jyqk,bz,zx_pdbz,zxrq,zxyydm,zxlbdm,zxdw_gajgjgdm,zxdw_gajgmc,zxr_xm,zxr_gmsfhm,zxr_lxdh,djsj,djdw_gajgjgdm,djdw_gajgmc,djr_xm,djr_gmsfhm,djr_lxdh,czbs,czsj,czdw_gajgjgdm,czdw_gajgmc,czr_xm,czr_gmsfhm,czr_lxdh,xxly_xzqhdm,sc_xxrksj,xxrksj]
# 指定一个列作为VID的源。
# vertex的值必须与上述fields或者csv.fields中的列名保持一致。
# 目前,Nebula Graph 2.5.1仅支持字符串或整数类型的VID。
vertex: {
field: _c11
}
# 指定的分隔符。默认值为英文逗号(,)。
separator: "\t"
# 如果CSV文件有表头,请将header设置为true。
# 如果CSV文件没有表头,请将header设置为false。默认值为false。
header: false
# 指定单批次写入Nebula Graph的最大点数量。
batch: 2560
# 指定Spark分片数量。
partition: 64
}
]
}
sparkJob任务:

spark 相关日志:
21/10/27 17:03:05 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (0 time so far)
21/10/27 17:03:14 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (1 time so far)
21/10/27 17:03:23 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (2 times so far)
21/10/27 17:03:33 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (3 times so far)
21/10/27 17:03:42 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (4 times so far)
21/10/27 17:03:52 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (5 times so far)
21/10/27 17:04:02 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (6 times so far)
21/10/27 17:04:11 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (7 times so far)
21/10/27 17:04:21 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (8 times so far)
21/10/27 17:04:30 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (9 times so far)
21/10/27 17:04:40 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (10 times so far)
21/10/27 17:04:50 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (11 times so far)
21/10/27 17:04:59 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (12 times so far)
21/10/27 17:05:08 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (13 times so far)
21/10/27 17:05:18 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (14 times so far)
21/10/27 17:05:27 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (15 times so far)
21/10/27 17:05:37 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (16 times so far)
21/10/27 17:05:46 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (17 times so far)
21/10/27 17:05:55 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (18 times so far)
21/10/27 17:06:04 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (19 times so far)
21/10/27 17:06:14 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (20 times so far)
21/10/27 17:06:24 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (21 times so far)
21/10/27 17:06:33 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (22 times so far)
21/10/27 17:06:43 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (23 times so far)
21/10/27 17:06:52 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (24 times so far)
21/10/27 17:07:02 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (25 times so far)
21/10/27 17:07:12 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (26 times so far)
21/10/27 17:07:21 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (27 times so far)
21/10/27 17:07:31 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (28 times so far)
21/10/27 17:07:40 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (29 times so far)
21/10/27 17:07:50 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (30 times so far)
21/10/27 17:08:00 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (31 times so far)
21/10/27 17:08:09 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (32 times so far)
21/10/27 17:08:19 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (33 times so far)
21/10/27 17:08:28 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (34 times so far)
21/10/27 17:08:37 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (35 times so far)
21/10/27 17:08:47 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (36 times so far)
21/10/27 17:08:57 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (37 times so far)
21/10/27 17:09:06 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (38 times so far)
21/10/27 17:09:15 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (39 times so far)
21/10/27 17:09:25 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (40 times so far)
21/10/27 17:09:35 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (41 times so far)
21/10/27 17:09:45 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (42 times so far)
21/10/27 17:09:54 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (43 times so far)
21/10/27 17:10:03 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (44 times so far)
21/10/27 17:10:13 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (45 times so far)
21/10/27 17:10:22 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (46 times so far)
21/10/27 17:10:32 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (47 times so far)
21/10/27 17:10:42 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (48 times so far)
21/10/27 17:10:51 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (49 times so far)
21/10/27 17:11:01 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (50 times so far)
21/10/27 17:11:11 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (51 times so far)
21/10/27 17:11:20 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (52 times so far)
21/10/27 17:11:29 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (53 times so far)
21/10/27 17:11:39 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (54 times so far)
21/10/27 17:11:48 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (55 times so far)
21/10/27 17:11:58 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (56 times so far)
21/10/27 17:12:08 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (57 times so far)
21/10/27 17:12:17 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (58 times so far)
21/10/27 17:12:26 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (59 times so far)
21/10/27 17:12:36 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (60 times so far)
21/10/27 17:12:46 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (61 times so far)
21/10/27 17:12:55 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (62 times so far)
21/10/27 17:13:04 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (63 times so far)
21/10/27 17:13:14 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (64 times so far)
21/10/27 17:13:24 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (65 times so far)
21/10/27 17:13:33 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (66 times so far)
21/10/27 17:13:42 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (67 times so far)
21/10/27 17:13:52 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (68 times so far)
21/10/27 17:14:02 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (69 times so far)
21/10/27 17:14:12 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (70 times so far)
21/10/27 17:14:21 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (71 times so far)
21/10/27 17:14:32 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (72 times so far)
21/10/27 17:14:42 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (73 times so far)
21/10/27 17:14:52 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (74 times so far)
21/10/27 17:15:01 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (75 times so far)
21/10/27 17:15:12 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (76 times so far)
21/10/27 17:15:21 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (77 times so far)
21/10/27 17:15:32 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (78 times so far)
21/10/27 17:15:42 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (79 times so far)
21/10/27 17:15:52 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (80 times so far)
21/10/27 17:16:02 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (81 times so far)
21/10/27 17:16:12 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (82 times so far)
21/10/27 17:16:22 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (83 times so far)
21/10/27 17:16:31 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (84 times so far)
21/10/27 17:16:41 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (85 times so far)
21/10/27 17:16:50 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (86 times so far)
21/10/27 17:17:00 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (87 times so far)
21/10/27 17:17:09 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (88 times so far)
21/10/27 17:17:19 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (89 times so far)
21/10/27 17:17:28 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (90 times so far)
21/10/27 17:17:38 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (91 times so far)
21/10/27 17:17:47 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (92 times so far)
21/10/27 17:17:57 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (93 times so far)
21/10/27 17:18:06 INFO codegen.CodeGenerator: Code generated in 259.878936 ms
21/10/27 17:18:06 INFO codegen.CodeGenerator: Code generated in 25.581536 ms
21/10/27 17:18:06 INFO codegen.CodeGenerator: Code generated in 18.628487 ms
21/10/27 17:18:07 INFO codegen.CodeGenerator: Code generated in 29.902498 ms
21/10/27 17:18:07 INFO codegen.CodeGenerator: Code generated in 10.443196 ms
21/10/27 17:18:07 INFO codegen.CodeGenerator: Code generated in 7.787191 ms
21/10/27 17:18:07 INFO codegen.CodeGenerator: Code generated in 7.552131 ms
21/10/27 17:18:07 INFO codegen.CodeGenerator: Code generated in 4.385206 ms
21/10/27 17:24:30 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (0 time so far)
21/10/27 17:30:57 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (1 time so far)
21/10/27 17:37:25 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (2 times so far)
21/10/27 17:43:54 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (3 times so far)
21/10/27 17:50:16 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (4 times so far)
21/10/27 17:56:47 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (5 times so far)
21/10/27 18:03:20 INFO sort.UnsafeExternalSorter: Thread 59 spilling sort data of 3.0 GB to disk (6 times so far)