- nebula 版本:2.5.0
- 部署方式(分布式 / 单机 / Docker / DBaaS):Docker
- 是否为线上版本:Y
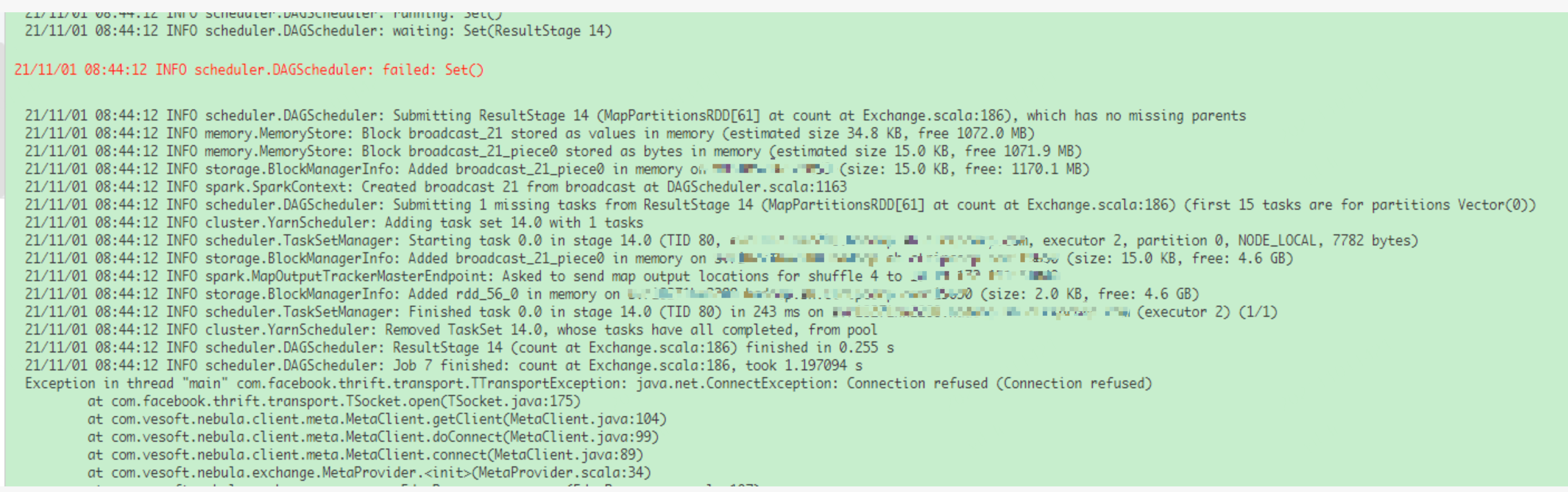
spark日志:
graphd日志:

metad日志:
Exchange 用的是什么版本的?
exchange是2.5.0版本
…日志呢。没有日志咋定位问题呢。
你导数据的时候,在做其他的查询之类的操作吗? 也许是因为资源竞争导致部分数据导入失败,报错信息有吗
也许是因为资源竞争导致部分数据导入失败,报错信息有吗
现在有了  应该只是在导数据,没有做别的查询
应该只是在导数据,没有做别的查询
报错好像是超时了,你看下 session_idle_timeout_secs 你设置多少了
–client_idle_timeout_secs 和 --session_idle_timeout_secs都是0
我让研发同学看看
你把Exchange的配置文件, 导入命令 和docker-compose ps的结果贴出来。
看你贴的Spark错误日志显示metaClient连接不上,但你贴的nebula日志是graph的,这俩不对应的, 因为Exchange连接Nebula Metad的时候还没与Nebula Graphd 连接。
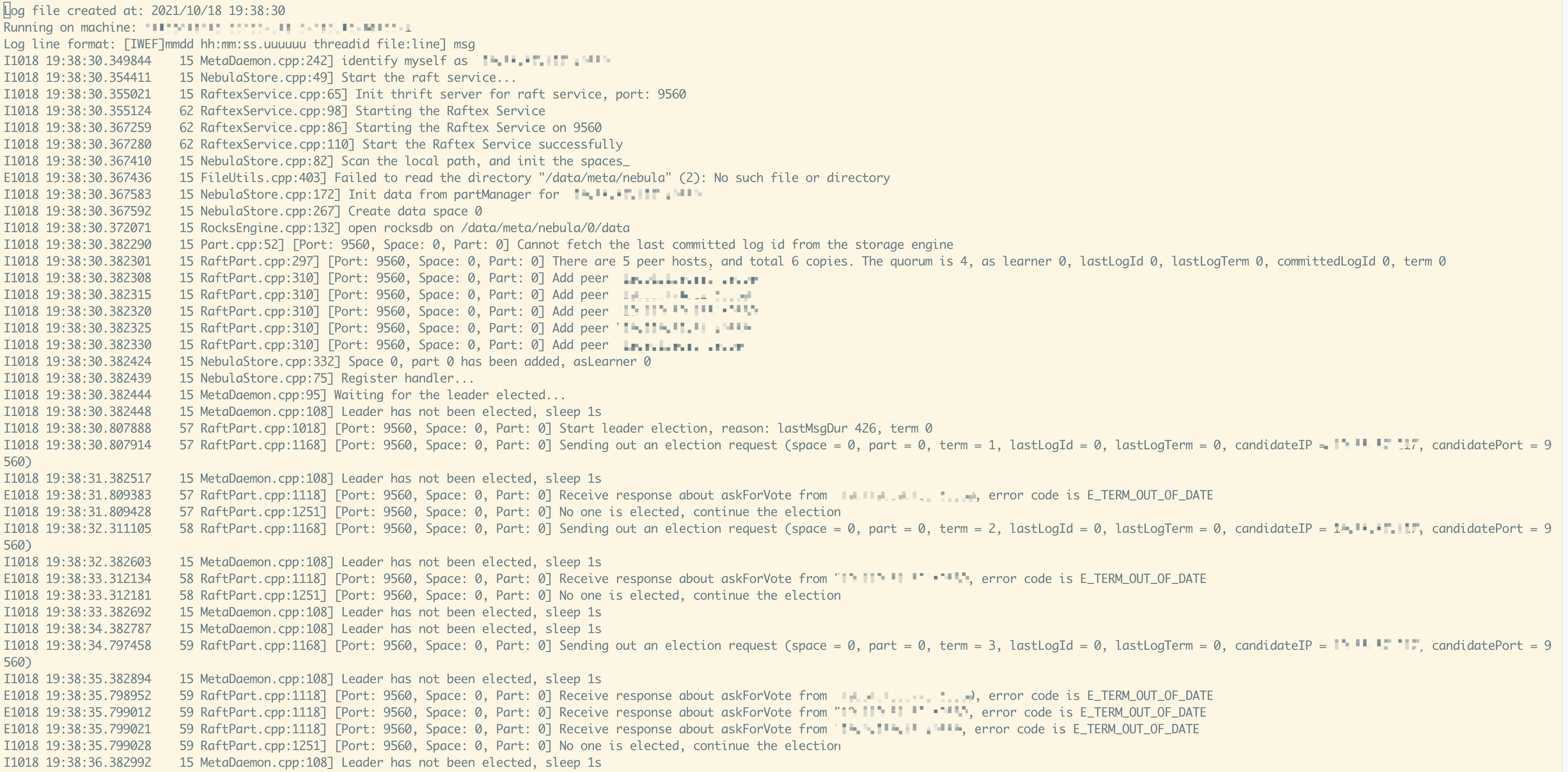
我们这边是配了5个meta,supervisor管理的,刚贴的图是正常的meta,应该是其中一个meta挂了,exchange导的时候刚好连到了这个meta上,这个是挂掉的meta的日志,为啥会挂咧
meta fail:
前面贴的exchange的日志中的报错是因为正好 meta服务挂了。 你标题中提到经常会出现前几次报错,是你们的meta 服务经常会挂么。
不是,之前没发现这个meta挂了 定时导的时候就连到这个meta了吧,可是这个meta为啥会挂呢
您好,麻烦您把挂掉meta的Info日志发下。多谢哈
这个log,只能看出meta没有选出leader来,但是没有看到metad挂掉啊?
可是curl这个meta的话是
curl: (7) Failed connect to x.x.x.x:19559; Connection refused
如果metad挂掉的话,你要去对应的metad机器上看看进程在不在?
然后看看防火墙 或者端口号放开了没?你用telnet 命令试下
Trying x.x.x.x…
telnet: connect to address x.x.x.x: Connection refused
我们是用supervisor管理的meta进程,supervisorctl status看是好的
metad RUNNING pid 15, uptime 14 days, 0:20:07
用nebula.service status all查看也是好的:
[INFO] nebula-metad(5b83e5cb): Running as 15, Listening on 9559
这台机器上的graph和storage都是好的,应该不是防火墙和端口号的问题,还有就是这个meta的日志从10月26号之后就突然没有了
还有就是5个meta,为啥日志里是There are 5 peer hosts, and total 6 copies. The quorum is 4?
正常的meta是,There are 4 peer hosts, and total 5 copies. The quorum is 3 
5 个 meta 是怎么部署的?
部署在 5 个机器,每个机器用 supervisor 来管理进程么?
supervisor 里,metad 的配置是啥样的?
每个meta都在不同机器上,都是用supervisor管理,2 2 1这样子分布在不同机房
跟这个meta在同一个机房的meta是正常的
supervisor配置
[program:metad]
user=nebula
command=/opt/app/nebula/bin/nebula-metad --flagfile=/opt/app/nebula/etc/nebula-metad.conf
autostart=true
autorestart=false
priority=100
stopasgroup=true
nebula-metad.conf应该没改过什么
吐血,已经知道问题了,我们用operator部署的,不知道哪里拉了一个错误的IP来,这个meta的meta_server_address跟local_ip对不上
多谢!