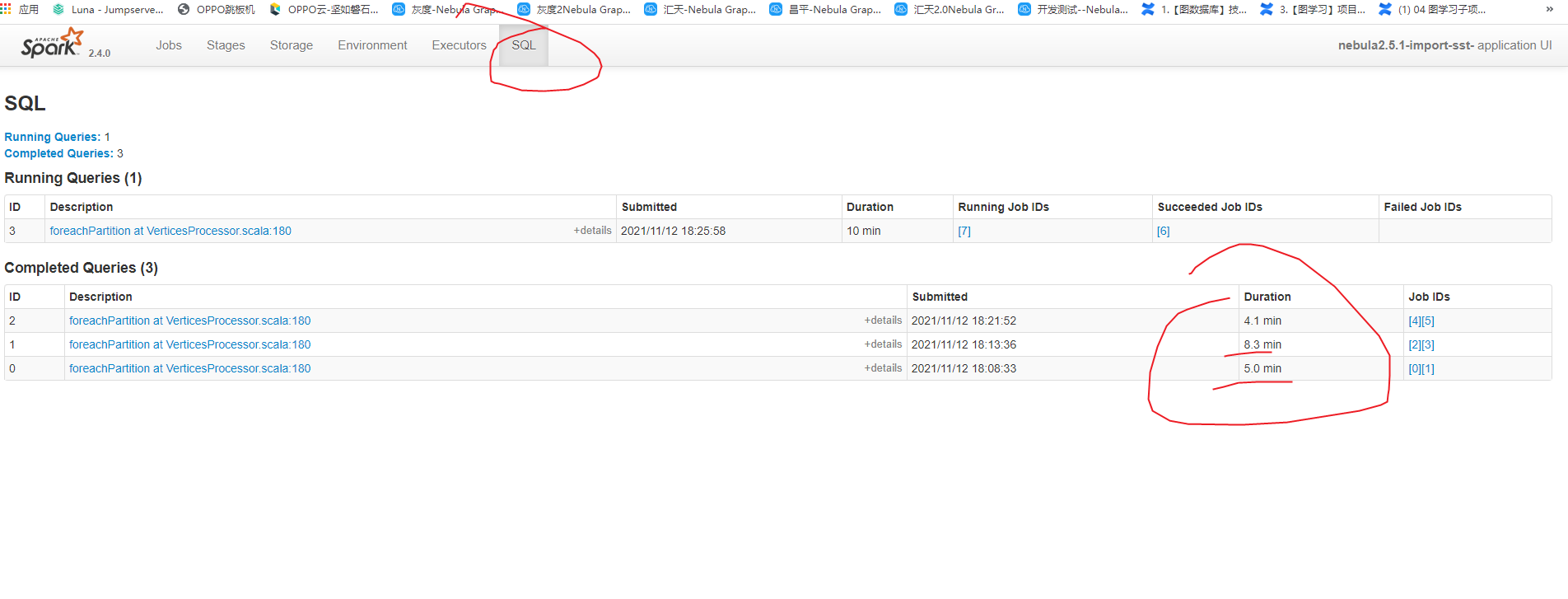
还是出现了之前的问题第一个sql 1.2亿数据,180 有作用,但是第二,第三个sql 数据就几百万,但是180 没起作用,导致数据少的节点反而慢??? 这个到底是什么原因啊??

你这个 180并发度生效的 配置是啥样的,贴一下出来吧。 --conf 的配置是对整个application都生效的,不是针对某个具体stage的。
还有你可以试下把 第二个sql 提到前面去,看下效率。
我把数据少的放第一个配置就没起作用,但是数据多的那个180 就起作用了,有点奇怪,难道spark 自动根据数据来分区的吗????
${SPARK_HOME}/bin/spark-submit
–queue root.ipd.daily
–name “nebula2.5.1-import-sst-$taskName”
–master yarn
–driver-cores 26
–driver-memory 32g
–executor-memory 32g
–deploy-mode cluster
–num-executors 96
–executor-cores 8
–conf spark.port.maxRetries=1
–conf spark.yarn.maxAppAttempts=1
–conf spark.executor.memoryOverhead=8g
–conf spark.driver.memoryOverhead=8g
–conf spark.hadoop.fs.defaultFS=“$ALG_HDFS”
–conf spark.executor.extraJavaOptions=“-XX:MaxDirectMemorySize=7372m”
–conf spark.default.parallelism=48
–conf spark.sql.shuffle.partitions=180
–files “$conf”
–class com.vesoft.nebula.exchange.Exchange
lib/nebula-exchange-2.5.2.jar -c $conf -h -d
在帮看看,我把数据少的放第一个配置就没起作用,但是数据多的那个180 就起作用了,有点奇怪,难道spark 自动根据数据来分区的吗????
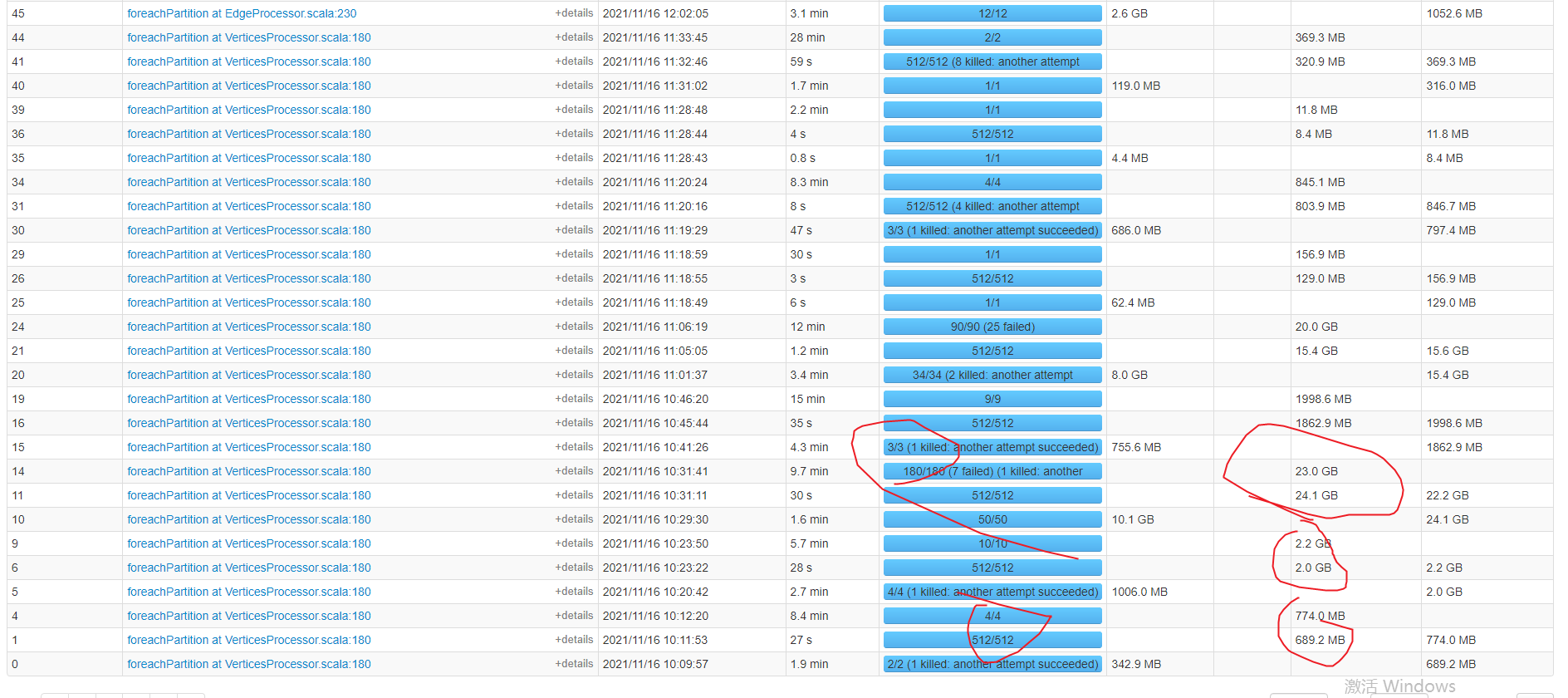
我把第二个放前面也是一样时间,我发现是不是字段多的原因第二个sql有120个字段,第一个sql只有20个字段
避免一个相似内容多处回复关注的人不知道最终结果,这个帖子关联了 nebulaGraph2.5.1 连接hive 生成sst 文件现在有500个节点和边。每个sql 一个一个执行要好几个小时,问下怎样优化让多个sql 并发执行加快生成文件速度 先行关闭了,有任何问题记得在新帖子里进行更新哈。