- nebula 版本:2.5.1
- 部署方式:分布式
- 安装方式: RPM
- 是否为线上版本:Y
- 硬件信息
- 磁盘( 推荐使用 SSD)ssd
- CPU、内存信息 48C, 256G
6台服务器,3 meta,6 graph 6 storage
- 问题的具体描述
数据量级:10亿 点,30亿的边关系
进行最短路径的查询
FIND SHORTEST PATH WITH PROP FROM “e45c0ed51a12622300539630299cbb4a11e9558b” TO “003fef94eebfdd3b622be7366c6a2ce66d7feaca” OVER * BIDIRECT;
该点在一跳和两跳的数据量
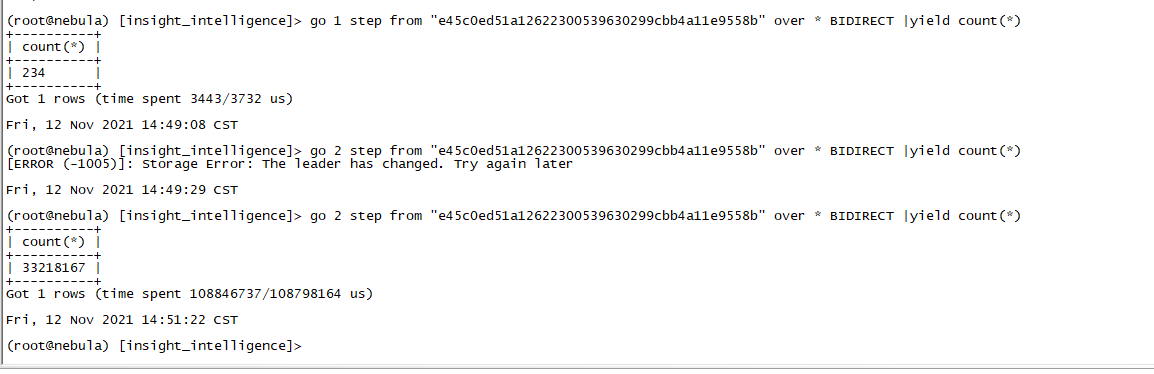
进行五跳的最短路径搜索会导致graph挂掉,应该事OOM
请问有什么优化方案,或者满足这个数据量级需要的服务器集群规模是怎么样?