提问参考模版:
- nebula 版本:2.5.0
- 部署方式:单机
- 安装方式: RPM
- 是否为线上版本:Y
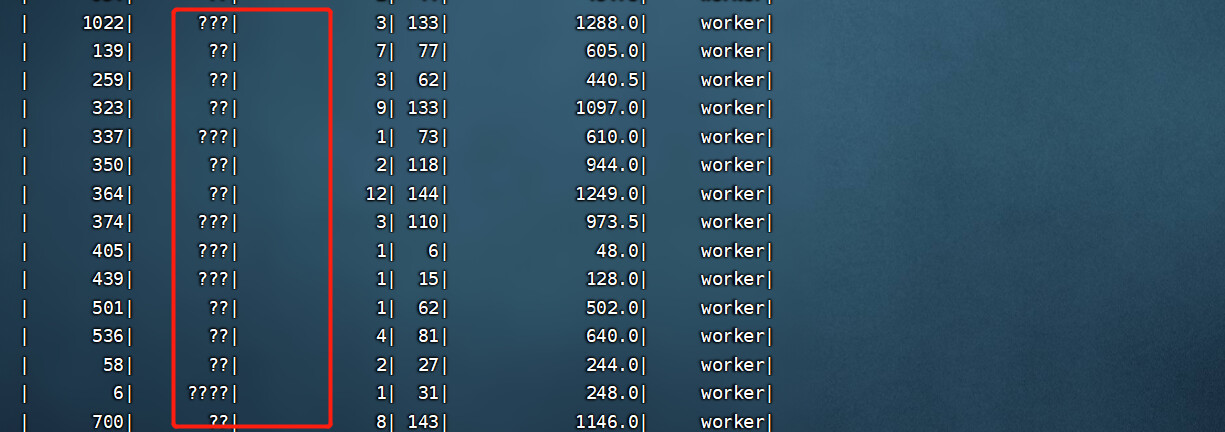
如图所示,使用spark yarn模式导入数据后,中文字符都变成了??,指定spark提交的编码为utf-8后还是没能解决,spark-submit --master yarn --class com.opensource.bigdata.spark.connector.nebulaAlgorithm --conf “spark.driver.extraJavaOptions=-Dfile.encoding=utf-8” ./bigdata-1.0-SNAPSHOT.jar 100有遇到这种问题的小伙伴吗
急求教~·,csv文件类型是UNIX, utf-8格式
找到问题了
–conf spark.driver.extraJavaOptions="-Dfile.encoding=utf-8" --conf spark.executor.extraJavaOptions="-Dfile.encoding=UTF-8"
1 个赞
nicole
4
你真的是太幸运了,我从系统,集群,代码都进行了设置,sparkExecutor运行的结果还是ANSI码,最后通过修改源码解决了。
system
关闭
6
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。