nebula 版本:2.6.1
部署方式:单机
安装方式:RPM
是否为线上版本:Y
硬件信息:SSD
问题描述:有索引的情况下 查询语句为MATCH (n:tag{})-[r]-(m) where n.name==‘XXX’ return * limit 100 稀疏点响应时间为0.035s,稠密点为17.3s。是否limit操作是全量的查询然后再截取部分数据返回?如何优化能缩短查询时间?
麻烦帮忙打印 profile 加上您的 query看看哈,看看是没 limit 下推还是就是纯超级点慢,后者的话,考虑在storaged 的conf 里加上 max_edge_returned_per_vertex 配置一个适合的值,会有改善。
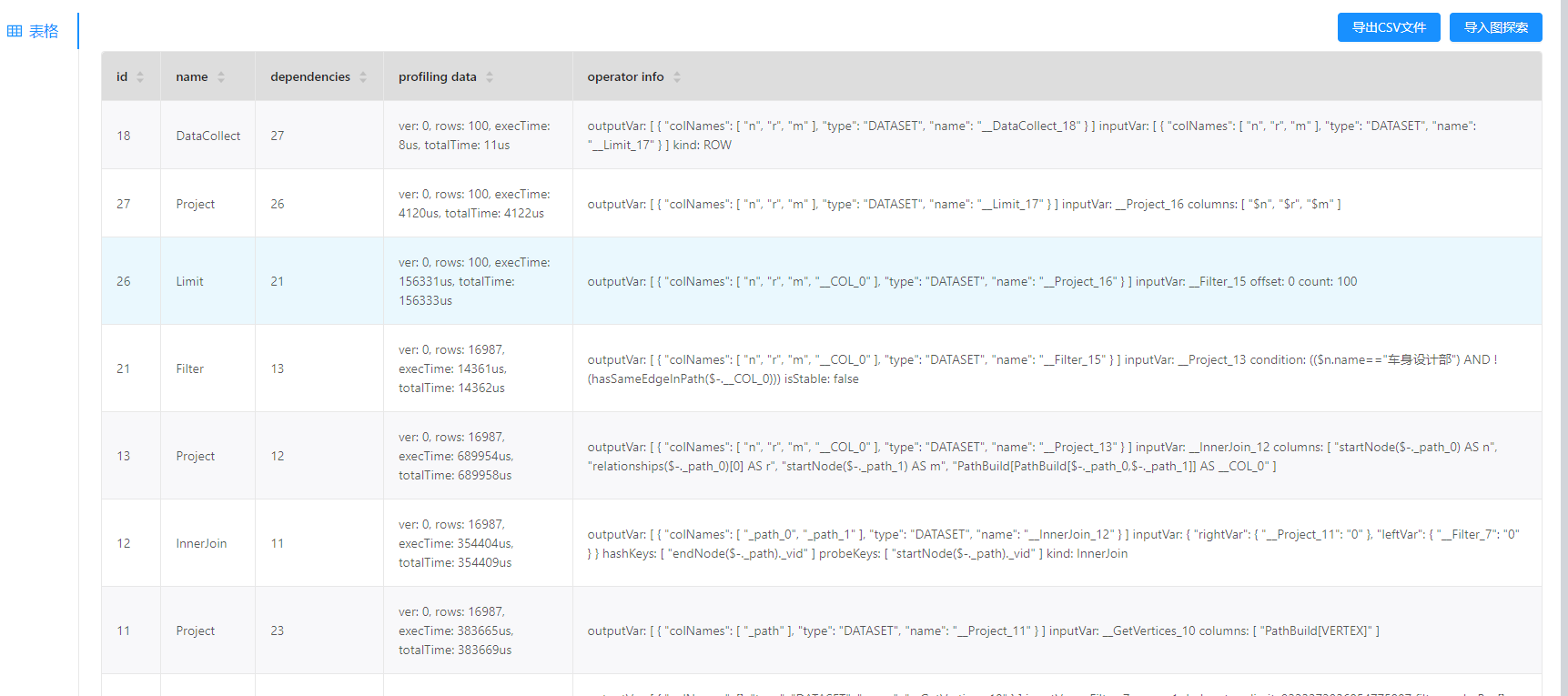
在storaged加了 max_edge_returned_per_vertex =1000的配置后查询时间由17s缩短到2s,还有别的优化的方法吗?理想时间是在1s以内
用 lookup 试试呢,它的limit 下推确定是有的
是nebula-graph2.6.1/etc/nebula-storaged.conf中加–max_edge_returned_per_vertex=1000吗?
是的
– 这个要加吗?
是的,这么加了之后扫描出边会丢弃超过这个数字的,对超级节点有采样的效果
可以仿造这个例子谢谢看哈?
LOOKUP ON player where player.name == "Tim Duncan" | LIMIT 1 | GO FROM $-.VertexID over * BIDIRECT YIELD properties($^).name AS src_name, properties($$).name AS dest_name, src(edge) as s, dst(edge) as d , properties(edge) | LIMIT 5
+-------------+---------------------+-------------+-------------+------------------+
| src_name | dest_name | s | d | properties(EDGE) |
+-------------+---------------------+-------------+-------------+------------------+
| "player100" | "Tony Parker" | "player101" | "player100" | {degree: 95} |
| "player100" | "LaMarcus Aldridge" | "player102" | "player100" | {degree: 75} |
| "player100" | "Marco Belinelli" | "player104" | "player100" | {degree: 55} |
| "player100" | "Danny Green" | "player105" | "player100" | {degree: 70} |
| "player100" | "Aron Baynes" | "player107" | "player100" | {degree: 80} |
+-------------+---------------------+-------------+-------------+------------------+
Got 5 rows (time spent 17872/28387 us)
Thu, 18 Nov 2021 09:29:53 UTC
感谢大佬语法改写,但是lookup和match的时间基本相同,都是2s左右
如微信聊到,加上lookup的 limit 之后剪枝下推了,时间缩短到1s了哈,另外可以再考虑结合 sample
https://docs.nebula-graph.io/2.6.1/3.ngql-guide/8.clauses-and-options/sample/
现在确实是这样的,我们应该会在近期优化 limit 下推,关注一下后续版本更新
1 个赞
这个没用的,上层的 limit 被 InnerJoin 阻塞并没有被下推,所以还是计算全部之后 limit 的。
 。
。这个配置项有可能导致查询结果错误,尤其是多步拓展,需要关注一下。
如果最终结果等于 limit 数,结果是正确的。如果小于,结果可能是错误的,原因是在拓展截断过程中满足 查询条件的点有可能未被采样。
1 个赞
这个可能是 lookup 和 match 实现差异,match 语句还有比较大的性能优化空间
1 个赞
好的
这个验证了下,基本缩短的1s是我采用了更小范围TAG的结果…在相同TAG范围lookup和match时间是一样的
1 个赞
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。