Yuwx
1
-
nebula 版本:
-
部署方式:单机
-
安装方式:tar包方式
-
是否为线上版本:N
-
硬件信息:
- 磁盘:2T SSD
- CPU、内存信息:32核、256G
-
问题的具体描述:
请问如何通过启动spark-shell读取nebula里的数据呢?看到帖子中有同学提供了如下的启动方式,但是似乎连不上终端
另外,Nebula官方文档很多操作写的也都非常简略,关键的操纵步骤都是一笔带过,对于初学者依然困惑满满。
对于不熟悉java操作的小白,如何通过在spark中完成上述的所有配置和算法调用?非常感谢各位大神赐教,谢谢 ~
~
wey
2
您截图的部分是 spark 上运行算法的 algorithm 哈(它依赖 spark connector)
如果只是想读写数据,请参考这里:nebula-spark-connector/README_CN.md at master · vesoft-inc/nebula-spark-connector · GitHub
读取 Nebula Graph 的点数据:
val config = NebulaConnectionConfig
.builder()
.withMetaAddress("127.0.0.1:9559")
.withConenctionRetry(2)
.build()
val nebulaReadVertexConfig = ReadNebulaConfig
.builder()
.withSpace("exchange")
.withLabel("person")
.withNoColumn(false)
.withReturnCols(List("birthday"))
.withLimit(10)
.withPartitionNum(10)
.build()
val vertex = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToDF()
读取 Nebula Graph 的点边数据构造 Graphx 的图:
val config = NebulaConnectionConfig
.builder()
.withMetaAddress("127.0.0.1:9559")
.withConenctionRetry(2)
.build()
val nebulaReadVertexConfig = ReadNebulaConfig
.builder()
.withSpace("exchange")
.withLabel("person")
.withNoColumn(false)
.withReturnCols(List("birthday"))
.withLimit(10)
.withPartitionNum(10)
.build()
val nebulaReadEdgeConfig = ReadNebulaConfig
.builder()
.withSpace("exchange")
.withLabel("knows1")
.withNoColumn(false)
.withReturnCols(List("timep"))
.withLimit(10)
.withPartitionNum(10)
.build()
val vertex = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToGraphx()
val edgeRDD = spark.read.nebula(config, nebulaReadEdgeConfig).loadEdgesToGraphx()
val graph = Graph(vertexRDD, edgeRDD)
Yuwx
3
非常感谢您的回复,其实我就是想了解如何在spark上运行algorithm,目前已经安装了spark connector,但是不知道如何如何操作,所有操作必须在maven中进行吗?我可以启动spark终端,在终端输入命令行进行操作吗?
wey
4
可以从 jar 包提交的哈(输出的可定制性不如代码里引用,如果结果刚好是你想要的,这样更方便,从shell就可以调用),就是如文档提到的 nebula-algorithm/README-CN.md at master · vesoft-inc/nebula-algorithm · GitHub
如果你想找一个更直观的,我之前做的一个互动教程里涉及了:
在最后一步,我手动启动了一个 spark 在容器里,然后shell 提交了 nebula-algorithm 的 jar 包,跑了 pagerank
Yuwx
5
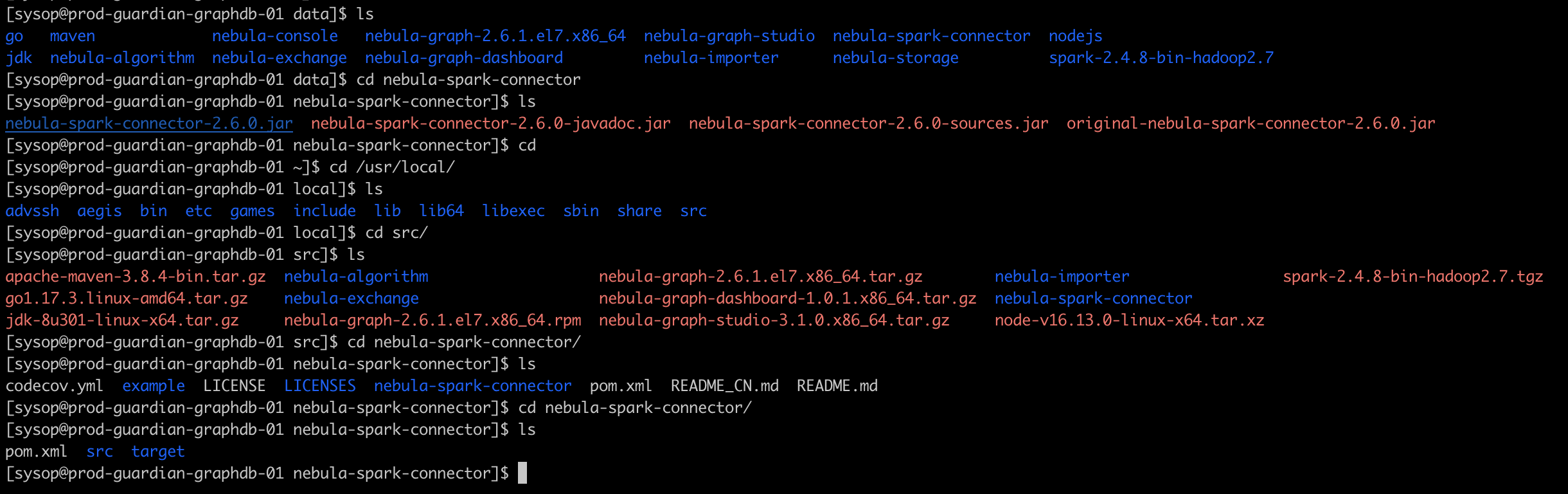
下面是我这边关于spark connector的安装情况,jar包存在/data/nebula-spark-connector/路径下,安装结果存在/usr/local/src/nebula-spark-connector/路径下,想知道我如何去操作spark connector?
wey
6
你需要的、直接操作的不是 spark connector 而是 nebula-algorithm ,nebula-algorithm 里边自带了 spark connector 哈。看我的例子,我只是 spark 里提交了 nebula-algorithm 的 jar 包
wget https://repo1.maven.org/maven2/com/vesoft/nebula-algorithm/2.0.0/nebula-algorithm-2.0.0.jar
/spark/bin/spark-submit --master "local" --conf spark.rpc.askTimeout=6000s \
--class com.vesoft.nebula.algorithm.Main \
--driver-memory 1g nebula-algorithm-2.0.0.jar \
-p pagerank.conf
提交 nebula algorithm jar 包不需要安装任何依赖的。
Yuwx
8
感谢您上面的示例分享,稍后我会仔细去学习一下。
您后面采用的是通过修改pagerank.conf配置文件,然后提交spark-submit任务的方式对吧?这种方式参考您们的官方文档,我大概了解,主要是另外还有一种方式是通过编辑脚步的方式,想了解这种方式我该如何操作?
wey
9
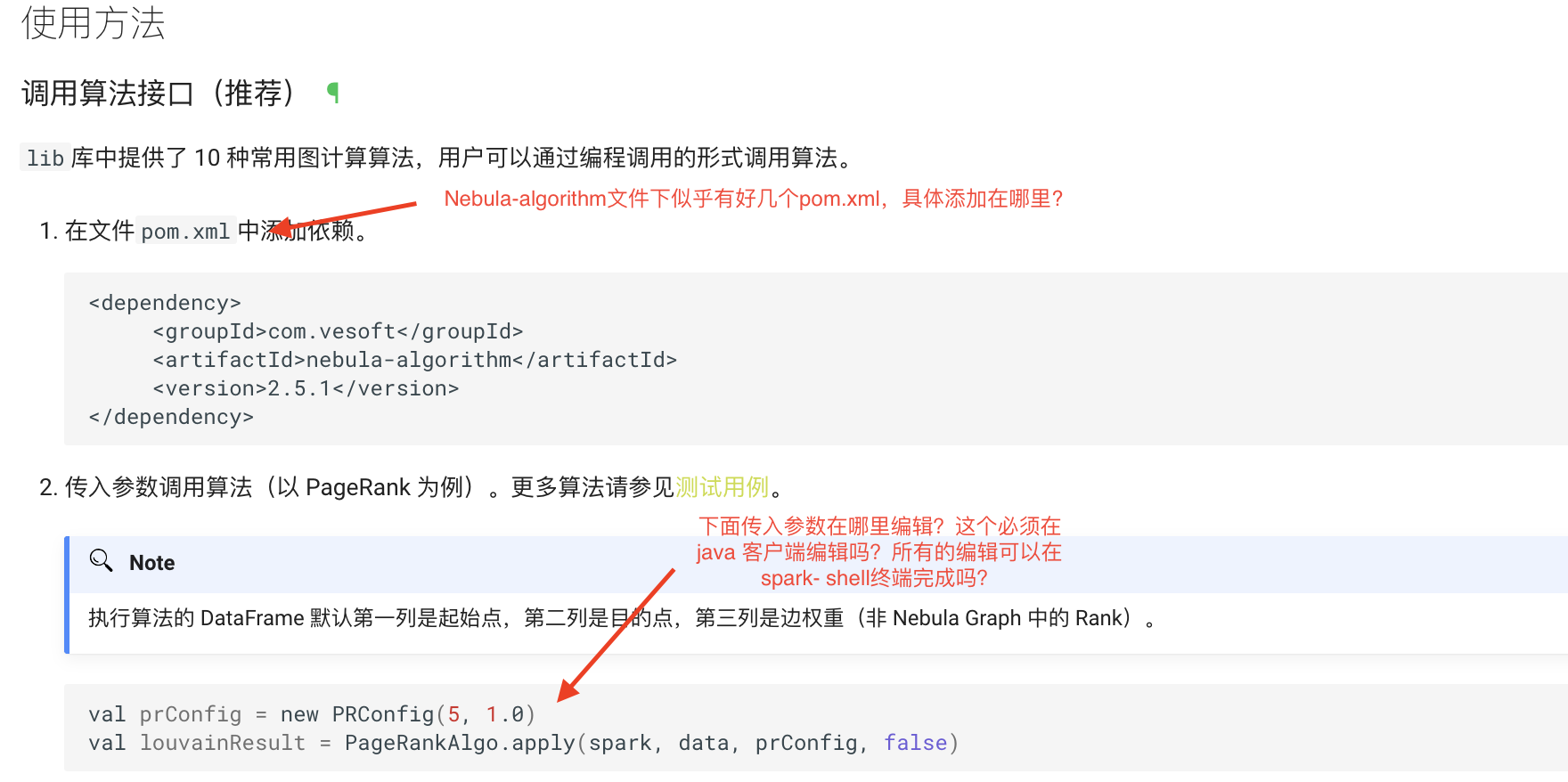
请参考测试代码 nebula-algorithm/nebula-algorithm/src/test/scala/com/vesoft/nebula/algorithm/lib at master · vesoft-inc/nebula-algorithm · GitHub
比如 pr,我 java 不熟哈,我理解你是要把依赖在 xml 里描述加上,再用 mvn 去拉取,代码里的例子如下
Yuwx
10
对这是这种,作为数据挖掘人员我平时更多基于pycharm进行python操作,对java和maven操作我也不熟,所以特别希望你们有一个小白操作示例,就其中的某一种算法调用操作的整个流程走一遍,这样我们也可以照葫芦画瓢,熟悉具体怎么去操作?
wey
11
Yuwx
13
可以的哈,非常感谢您耐心的解答,我先自己尝试操作,同时也非常期待您们的操作示例展示
1 个赞
Yuwx
14
您好,打扰您一下,想问一下单机版和分布式在性能方面差异有多大,目前我们自己部署了单机版:
配置情况:32核,256G内存,2T SSD磁盘
导入数据量:2亿+节点,3.2亿+边
我们在实际查询过程中,发现单机性能比较差,例如:
LOOKUP ON NIK WHERE NIK.nik_age > 50 YIELD properties(vertex).idcard, properties(vertex).nik_age | limit 10;
就这样一条语句,我们将响应时间设置为10分钟,都无法返回查询结果
1 个赞