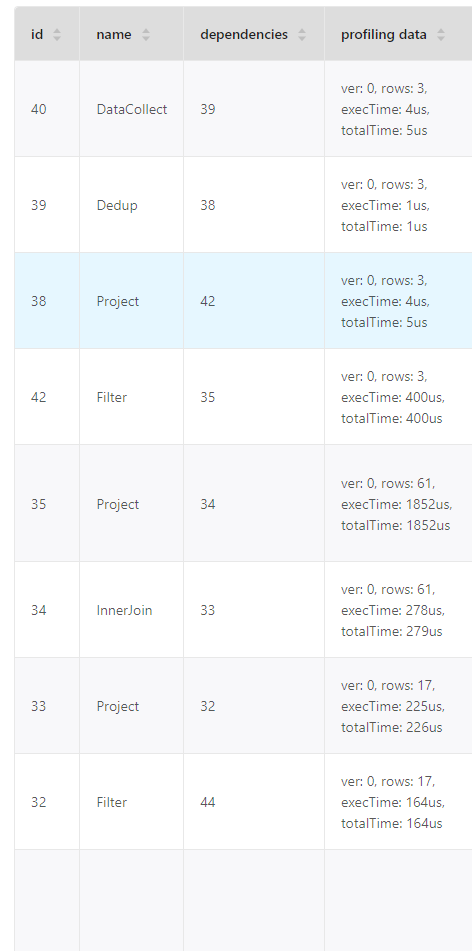
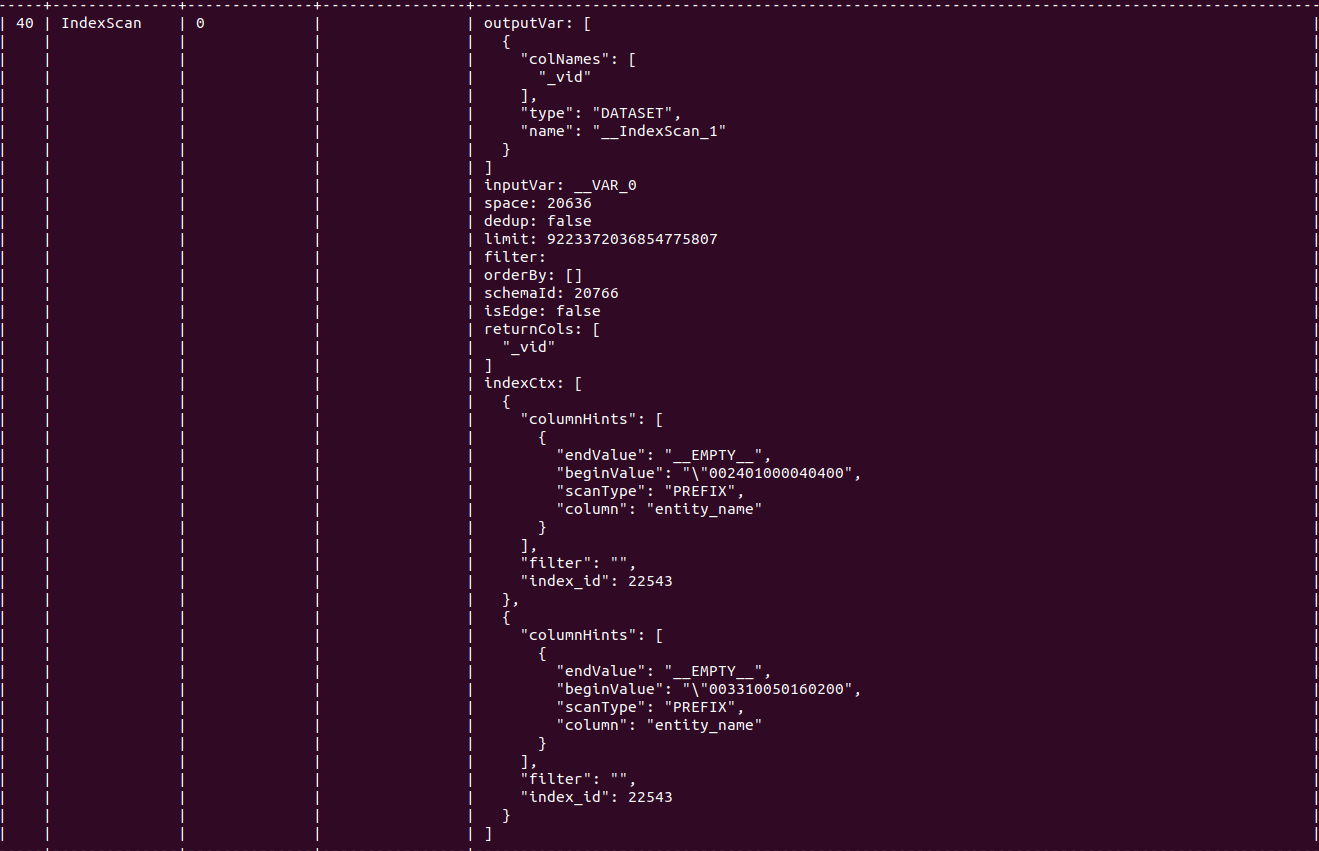
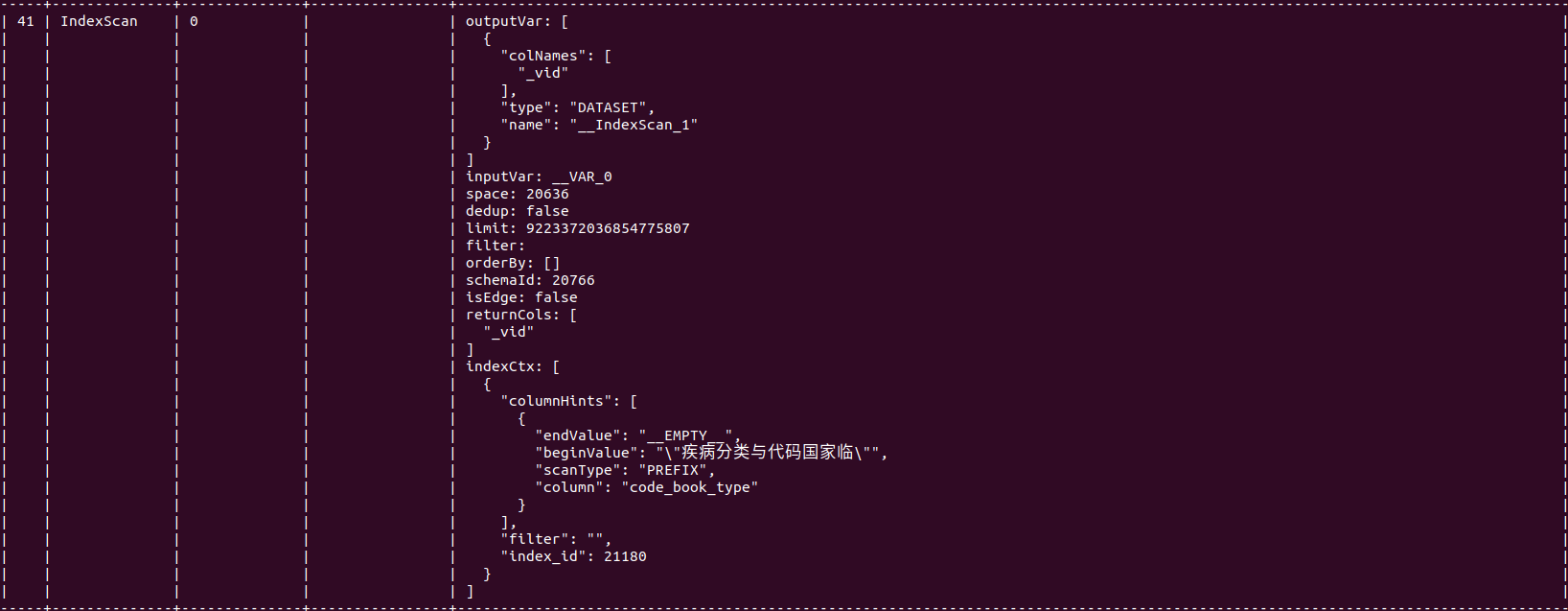
我渲染了那个图,但是看不太懂,而且比较小,不好截图,我把原始查询和console内容发出来吧。
请问你们有关于执行计划方面的文档吗,执行计划的输出都不太能看的明白。
索引:entity_name和code_book_type有分别的索引和联合索引。
查询语句:
profile format=“dot” match (v:tag1)<-[e:edge1]-(v1:tag2)<-[e1:edge2]-(v2:tag2)<-[e2:edge3]-(v3:tag3)-[e3:edge4]->(v4:tag1) where v.entity_name == “A” or v.entity_name == “B” return distinct v3.entity_name, v4.entity_name, v4.code_book_type;
执行耗时:90ms
执行计划:digraph exec_plan {
rankdir=BT;
“DataCollect_39”[label="{DataCollect_39|outputVar: [{“colNames”:[“v3.entity_name”,“v4.entity_name”,“v4.code_book_type”],“type”:“DATASET”,“name”:"__DataCollect_39"}]|inputVar: [{“colNames”:[“v3.entity_name”,“v4.entity_name”,“v4.code_book_type”],“type”:“DATASET”,“name”:"__Dedup_38"}]}", shape=Mrecord];
“Dedup_38”->“DataCollect_39”;
“Dedup_38”[label="{Dedup_38|outputVar: [{“colNames”:[“v3.entity_name”,“v4.entity_name”,“v4.code_book_type”],“type”:“DATASET”,“name”:"__Dedup_38"}]|inputVar: __Project_37}", shape=Mrecord];
“Project_37”->“Dedup_38”;
“Project_37”[label="{Project_37|outputVar: [{“colNames”:[“v3.entity_name”,“v4.entity_name”,“v4.code_book_type”],“type”:“DATASET”,“name”:"__Project_37"}]|inputVar: __Filter_36}", shape=Mrecord];
“Filter_36”->“Project_37”;
“Filter_36”[label="{Filter_36|outputVar: [{“colNames”:[“v”,“e”,“v1”,“e1”,“v2”,“e2”,“v3”,“e3”,“v4”,"__COL_0"],“type”:“DATASET”,“name”:"__Filter_36"}]|inputVar: __Project_35}", shape=Mrecord];
“Project_35”->“Filter_36”;
“Project_35”[label="{Project_35|outputVar: [{“colNames”:[“v”,“e”,“v1”,“e1”,“v2”,“e2”,“v3”,“e3”,“v4”,"__COL_0"],“type”:“DATASET”,“name”:"__Project_35"}]|inputVar: __InnerJoin_34}", shape=Mrecord];
“InnerJoin_34”->“Project_35”;
“InnerJoin_34”[label="{InnerJoin_34|outputVar: [{“colNames”:["_path_0","_path_1","_path_2","_path_3","_path_4"],“type”:“DATASET”,“name”:"__InnerJoin_34"}]|inputVar: {“rightVar”:{"__Project_33":“0”},“leftVar”:{"__InnerJoin_28":“0”}}}", shape=Mrecord];
“Project_33”->“InnerJoin_34”;
“Project_33”[label="{Project_33|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Project_33"}]|inputVar: __Filter_32}", shape=Mrecord];
“Filter_32”->“Project_33”;
“Filter_32”[label="{Filter_32|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Filter_32"}]|inputVar: __GetVertices_31}", shape=Mrecord];
“GetVertices_42”->“Filter_32”;
“GetVertices_42”[label="{GetVertices_42|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__GetVertices_31"}]|inputVar: __InnerJoin_28}", shape=Mrecord];
“InnerJoin_28”->“GetVertices_42”;
“InnerJoin_28”[label="{InnerJoin_28|outputVar: [{“colNames”:["_path_0","_path_1","_path_2","_path_3"],“type”:“DATASET”,“name”:"__InnerJoin_28"}]|inputVar: {“rightVar”:{"__Filter_27":“0”},“leftVar”:{"__InnerJoin_21":“0”}}}", shape=Mrecord];
“Filter_27”->“InnerJoin_28”;
“Filter_27”[label="{Filter_27|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Filter_27"}]|inputVar: __Project_26}", shape=Mrecord];
“Project_26”->“Filter_27”;
“Project_26”[label="{Project_26|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Project_26"}]|inputVar: __Filter_25}", shape=Mrecord];
“Filter_25”->“Project_26”;
“Filter_25”[label="{Filter_25|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Filter_25"}]|inputVar: __GetNeighbors_24}", shape=Mrecord];
“GetNeighbors_50”->“Filter_25”;
“GetNeighbors_50”[label="{GetNeighbors_50|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__GetNeighbors_24"}]|inputVar: __InnerJoin_21}", shape=Mrecord];
“InnerJoin_21”->“GetNeighbors_50”;
“InnerJoin_21”[label="{InnerJoin_21|outputVar: [{“colNames”:["_path_0","_path_1","_path_2"],“type”:“DATASET”,“name”:"__InnerJoin_21"}]|inputVar: {“rightVar”:{"__Filter_20":“0”},“leftVar”:{"__InnerJoin_14":“0”}}}", shape=Mrecord];
“Filter_20”->“InnerJoin_21”;
“Filter_20”[label="{Filter_20|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Filter_20"}]|inputVar: __Project_19}", shape=Mrecord];
“Project_19”->“Filter_20”;
“Project_19”[label="{Project_19|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Project_19"}]|inputVar: __Filter_18}", shape=Mrecord];
“Filter_18”->“Project_19”;
“Filter_18”[label="{Filter_18|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Filter_18"}]|inputVar: __GetNeighbors_17}", shape=Mrecord];
“GetNeighbors_49”->“Filter_18”;
“GetNeighbors_49”[label="{GetNeighbors_49|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__GetNeighbors_17"}]|inputVar: __InnerJoin_14}", shape=Mrecord];
“InnerJoin_14”->“GetNeighbors_49”;
“InnerJoin_14”[label="{InnerJoin_14|outputVar: [{“colNames”:["_path_0","_path_1"],“type”:“DATASET”,“name”:"__InnerJoin_14"}]|inputVar: {“rightVar”:{"__Filter_13":“0”},“leftVar”:{"__Filter_7":“0”}}}", shape=Mrecord];
“Filter_13”->“InnerJoin_14”;
“Filter_13”[label="{Filter_13|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Filter_13"}]|inputVar: __Project_12}", shape=Mrecord];
“Project_12”->“Filter_13”;
“Project_12”[label="{Project_12|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Project_12"}]|inputVar: __Filter_11}", shape=Mrecord];
“Filter_11”->“Project_12”;
“Filter_11”[label="{Filter_11|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Filter_11"}]|inputVar: __GetNeighbors_10}", shape=Mrecord];
“GetNeighbors_48”->“Filter_11”;
“GetNeighbors_48”[label="{GetNeighbors_48|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__GetNeighbors_10"}]|inputVar: __Filter_7}", shape=Mrecord];
“Filter_7”->“GetNeighbors_48”;
“Filter_7”[label="{Filter_7|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Filter_7"}]|inputVar: __Project_6}", shape=Mrecord];
“Project_6”->“Filter_7”;
“Project_6”[label="{Project_6|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Project_6"}]|inputVar: __Filter_5}", shape=Mrecord];
“Filter_5”->“Project_6”;
“Filter_5”[label="{Filter_5|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Filter_5"}]|inputVar: __GetNeighbors_4}", shape=Mrecord];
“GetNeighbors_47”->“Filter_5”;
“GetNeighbors_47”[label="{GetNeighbors_47|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__GetNeighbors_4"}]|inputVar: __IndexScan_1}", shape=Mrecord];
“IndexScan_40”->“GetNeighbors_47”;
“IndexScan_40”[label="{IndexScan_40|outputVar: [{“colNames”:["_vid"],“type”:“DATASET”,“name”:"__IndexScan_1"}]|inputVar: __VAR_0}", shape=Mrecord];
“Start_0”->“IndexScan_40”;
“Start_0”[label="{Start_0|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Start_0"}]|inputVar: }", shape=Mrecord];
}
执行语句:(相比上个,在v4上增加了一个筛选)
profile format=“dot” match (v:tag1)<-[e:edge1]-(v1:tag2)<-[e1:edge2]-(v2:tag2)<-[e2:edge3]-(v3:tag3)-[e3:edge4]->(v4:tag1{code_book_type: “C”}) where v.entity_name == “A” or v.entity_name == “B” return distinct v3.entity_name, v4.entity_name, v4.code_book_type;
执行耗时:11000ms
执行计划:
digraph exec_plan {
rankdir=BT;
“DataCollect_40”[label="{DataCollect_40|outputVar: [{“colNames”:[“v3.entity_name”,“v4.entity_name”,“v4.code_book_type”],“type”:“DATASET”,“name”:"__DataCollect_40"}]|inputVar: [{“colNames”:[“v3.entity_name”,“v4.entity_name”,“v4.code_book_type”],“type”:“DATASET”,“name”:"__Dedup_39"}]}", shape=Mrecord];
“Dedup_39”->“DataCollect_40”;
“Dedup_39”[label="{Dedup_39|outputVar: [{“colNames”:[“v3.entity_name”,“v4.entity_name”,“v4.code_book_type”],“type”:“DATASET”,“name”:"__Dedup_39"}]|inputVar: __Project_38}", shape=Mrecord];
“Project_38”->“Dedup_39”;
“Project_38”[label="{Project_38|outputVar: [{“colNames”:[“v3.entity_name”,“v4.entity_name”,“v4.code_book_type”],“type”:“DATASET”,“name”:"__Project_38"}]|inputVar: __Filter_37}", shape=Mrecord];
“Filter_42”->“Project_38”;
“Filter_42”[label="{Filter_42|outputVar: [{“colNames”:[“v”,“e”,“v1”,“e1”,“v2”,“e2”,“v3”,“e3”,“v4”,"__COL_0"],“type”:“DATASET”,“name”:"__Filter_37"}]|inputVar: __Project_35}", shape=Mrecord];
“Project_35”->“Filter_42”;
“Project_35”[label="{Project_35|outputVar: [{“colNames”:[“v”,“e”,“v1”,“e1”,“v2”,“e2”,“v3”,“e3”,“v4”,"__COL_0"],“type”:“DATASET”,“name”:"__Project_35"}]|inputVar: __InnerJoin_34}", shape=Mrecord];
“InnerJoin_34”->“Project_35”;
“InnerJoin_34”[label="{InnerJoin_34|outputVar: [{“colNames”:["_path_5","_path_8","_path_7","_path_6","_path_9"],“type”:“DATASET”,“name”:"__InnerJoin_34"}]|inputVar: {“rightVar”:{"__Project_33":“0”},“leftVar”:{"__InnerJoin_28":“0”}}}", shape=Mrecord];
“Project_33”->“InnerJoin_34”;
“Project_33”[label="{Project_33|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Project_33"}]|inputVar: __Filter_32}", shape=Mrecord];
“Filter_32”->“Project_33”;
“Filter_32”[label="{Filter_32|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Filter_32"}]|inputVar: __GetVertices_31}", shape=Mrecord];
“GetVertices_44”->“Filter_32”;
“GetVertices_44”[label="{GetVertices_44|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__GetVertices_31"}]|inputVar: __InnerJoin_28}", shape=Mrecord];
“InnerJoin_28”->“GetVertices_44”;
“InnerJoin_28”[label="{InnerJoin_28|outputVar: [{“colNames”:["_path_5","_path_8","_path_7","_path_6"],“type”:“DATASET”,“name”:"__InnerJoin_28"}]|inputVar: {“rightVar”:{"__Filter_27":“0”},“leftVar”:{"__InnerJoin_21":“0”}}}", shape=Mrecord];
“Filter_27”->“InnerJoin_28”;
“Filter_27”[label="{Filter_27|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Filter_27"}]|inputVar: __Project_26}", shape=Mrecord];
“Project_26”->“Filter_27”;
“Project_26”[label="{Project_26|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Project_26"}]|inputVar: __Filter_25}", shape=Mrecord];
“Filter_25”->“Project_26”;
“Filter_25”[label="{Filter_25|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Filter_25"}]|inputVar: __GetNeighbors_24}", shape=Mrecord];
“GetNeighbors_52”->“Filter_25”;
“GetNeighbors_52”[label="{GetNeighbors_52|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__GetNeighbors_24"}]|inputVar: __InnerJoin_21}", shape=Mrecord];
“InnerJoin_21”->“GetNeighbors_52”;
“InnerJoin_21”[label="{InnerJoin_21|outputVar: [{“colNames”:["_path_5","_path_8","_path_7"],“type”:“DATASET”,“name”:"__InnerJoin_21"}]|inputVar: {“rightVar”:{"__Filter_20":“0”},“leftVar”:{"__InnerJoin_14":“0”}}}", shape=Mrecord];
“Filter_20”->“InnerJoin_21”;
“Filter_20”[label="{Filter_20|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Filter_20"}]|inputVar: __Project_19}", shape=Mrecord];
“Project_19”->“Filter_20”;
“Project_19”[label="{Project_19|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Project_19"}]|inputVar: __Filter_18}", shape=Mrecord];
“Filter_18”->“Project_19”;
“Filter_18”[label="{Filter_18|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Filter_18"}]|inputVar: __GetNeighbors_17}", shape=Mrecord];
“GetNeighbors_51”->“Filter_18”;
“GetNeighbors_51”[label="{GetNeighbors_51|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__GetNeighbors_17"}]|inputVar: __InnerJoin_14}", shape=Mrecord];
“InnerJoin_14”->“GetNeighbors_51”;
“InnerJoin_14”[label="{InnerJoin_14|outputVar: [{“colNames”:["_path_5","_path_8"],“type”:“DATASET”,“name”:"__InnerJoin_14"}]|inputVar: {“rightVar”:{"__Filter_13":“0”},“leftVar”:{"__Filter_7":“0”}}}", shape=Mrecord];
“Filter_13”->“InnerJoin_14”;
“Filter_13”[label="{Filter_13|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Filter_13"}]|inputVar: __Project_12}", shape=Mrecord];
“Project_12”->“Filter_13”;
“Project_12”[label="{Project_12|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Project_12"}]|inputVar: __Filter_11}", shape=Mrecord];
“Filter_11”->“Project_12”;
“Filter_11”[label="{Filter_11|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Filter_11"}]|inputVar: __GetNeighbors_10}", shape=Mrecord];
“GetNeighbors_50”->“Filter_11”;
“GetNeighbors_50”[label="{GetNeighbors_50|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__GetNeighbors_10"}]|inputVar: __Filter_7}", shape=Mrecord];
“Filter_7”->“GetNeighbors_50”;
“Filter_7”[label="{Filter_7|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Filter_7"}]|inputVar: __Project_6}", shape=Mrecord];
“Project_6”->“Filter_7”;
“Project_6”[label="{Project_6|outputVar: [{“colNames”:["_path"],“type”:“DATASET”,“name”:"__Project_6"}]|inputVar: __Filter_5}", shape=Mrecord];
“Filter_5”->“Project_6”;
“Filter_5”[label="{Filter_5|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Filter_5"}]|inputVar: __GetNeighbors_4}", shape=Mrecord];
“GetNeighbors_49”->“Filter_5”;
“GetNeighbors_49”[label="{GetNeighbors_49|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__GetNeighbors_4"}]|inputVar: __IndexScan_1}", shape=Mrecord];
“IndexScan_41”->“GetNeighbors_49”;
“IndexScan_41”[label="{IndexScan_41|outputVar: [{“colNames”:["_vid"],“type”:“DATASET”,“name”:"__IndexScan_1"}]|inputVar: __VAR_0}", shape=Mrecord];
“Start_0”->“IndexScan_41”;
“Start_0”[label="{Start_0|outputVar: [{“colNames”:[],“type”:“DATASET”,“name”:"__Start_0"}]|inputVar: }", shape=Mrecord];
}