- nebula 版本:2.6.1
- 部署方式:分布式
- 安装方式:RPM
- 是否为线上版本: N
- 硬件信息
- 磁盘( 推荐使用 SSD)
用nebula—algorithm跑算法时,结果落库选择nebula方式时报错INFO NebulaDataSourceVertexWriter: failed execs: List(),已经提前新建图空间和tag的属性与application.conf里的参数相对应,落库方式选择csv时是正常能够出结果的,换成写入nebula方式就不行了,求解决!
- 磁盘( 推荐使用 SSD)
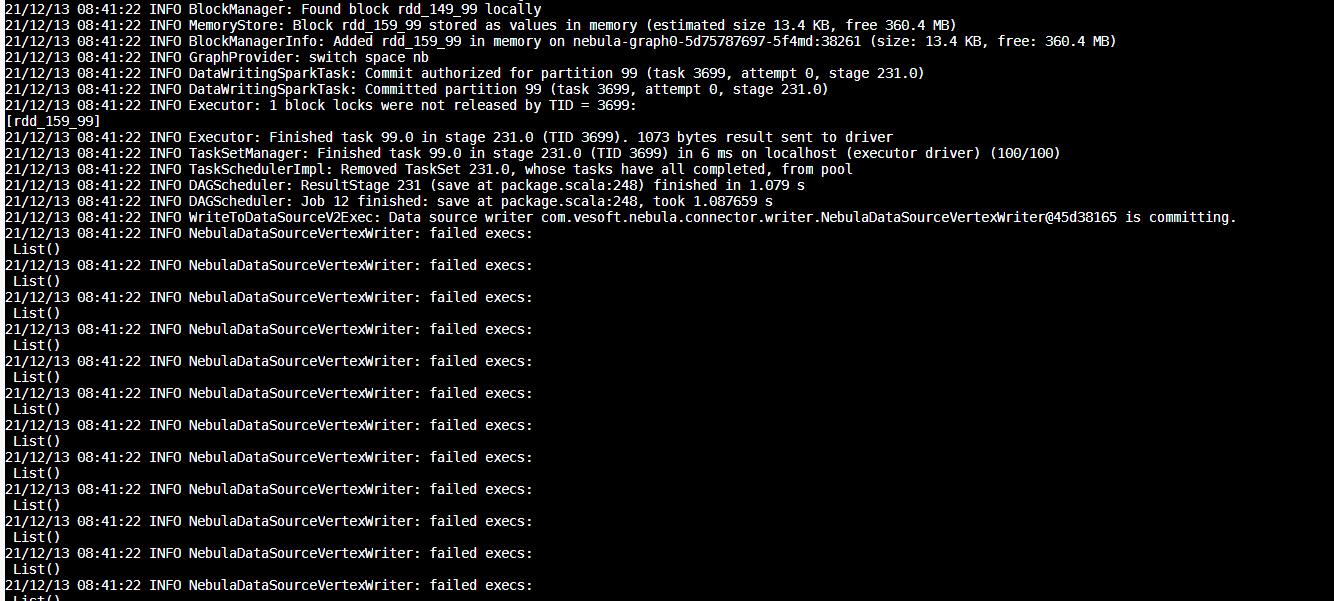
这不是报错啊,这是个日志啊。 日志提示你失败的数据为空,就是没有失败数据, 每个partition都会打印的。
我知道是日志呀,可是为什么用csv保存结果有数据,用nebula保存却没有数据,图空间和tag属性都提前创建好了,跑的是PageRank算法,求大佬解答
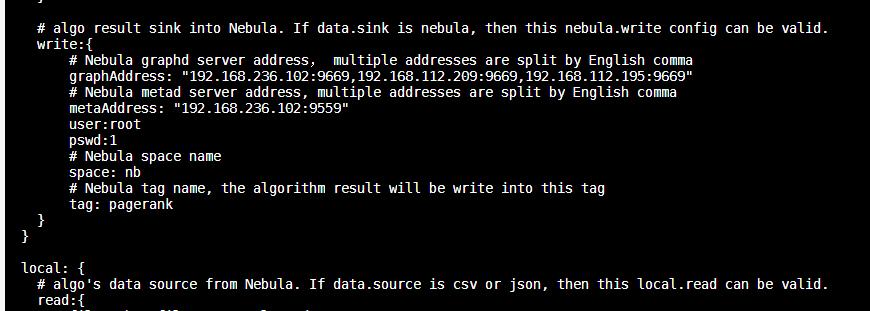
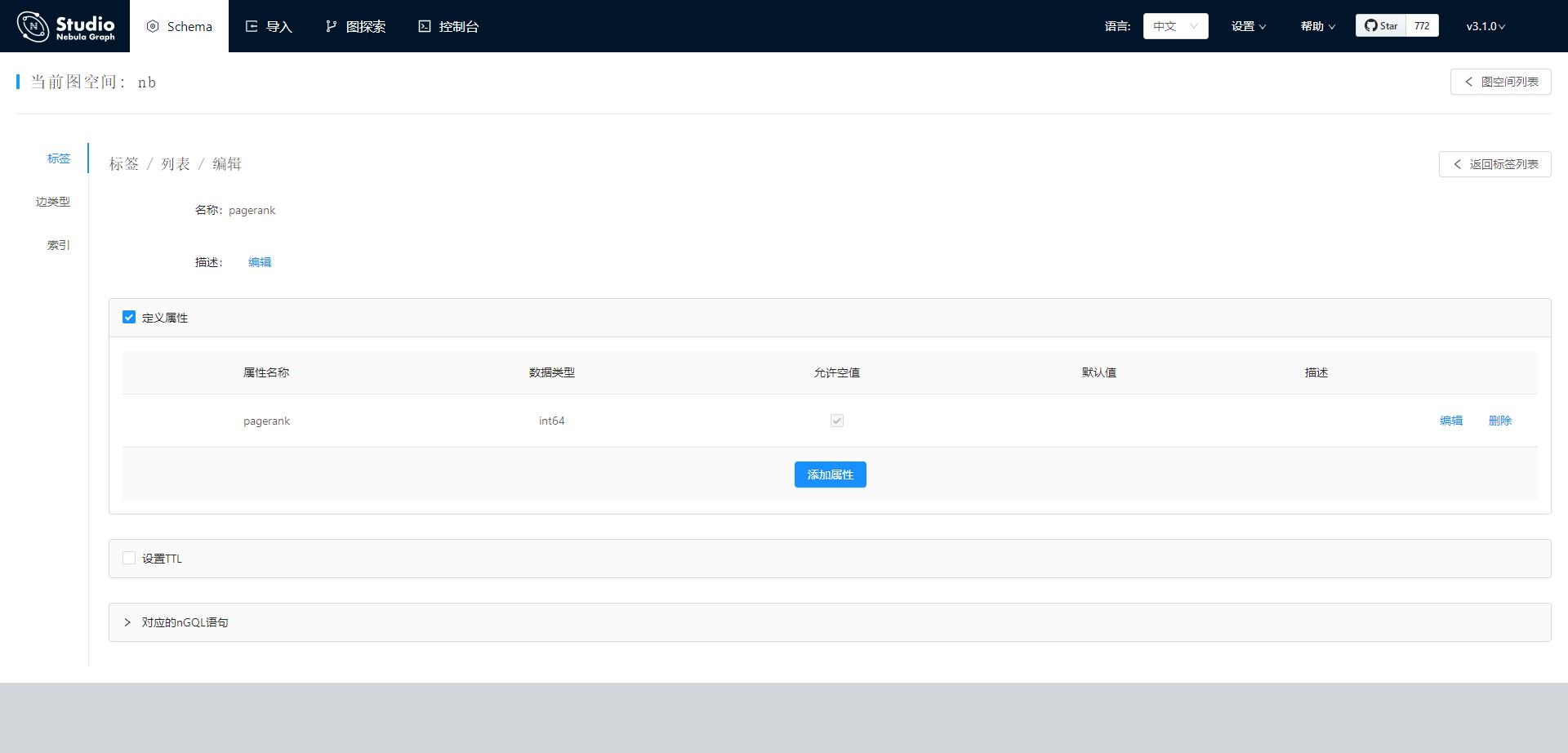
属性类型是int时 这个 NebulaDataSourceVertexWriter: failed execs: List() 日志里面 list就不是空了,应该会有失败的insert语句删除。
algorithm你用的哪个版本?
帖子里截图的NebulaDataSourceVertexWriter: failed execs: List() 日志就是我用属性类型为int时出现的,设为float、string、double等其他属性时也是这样的日志,预计是和属性类型无关
algorithm你用的是2.5.1版本
版本ok的。
如果属性类型是int,那肯定会有错误的,因为pagerank算法的结果是double类型的,写不到nebula里面去。 你在studio中show hosts graph 和show hosts meta看下, 配置的确定是一个环境吧
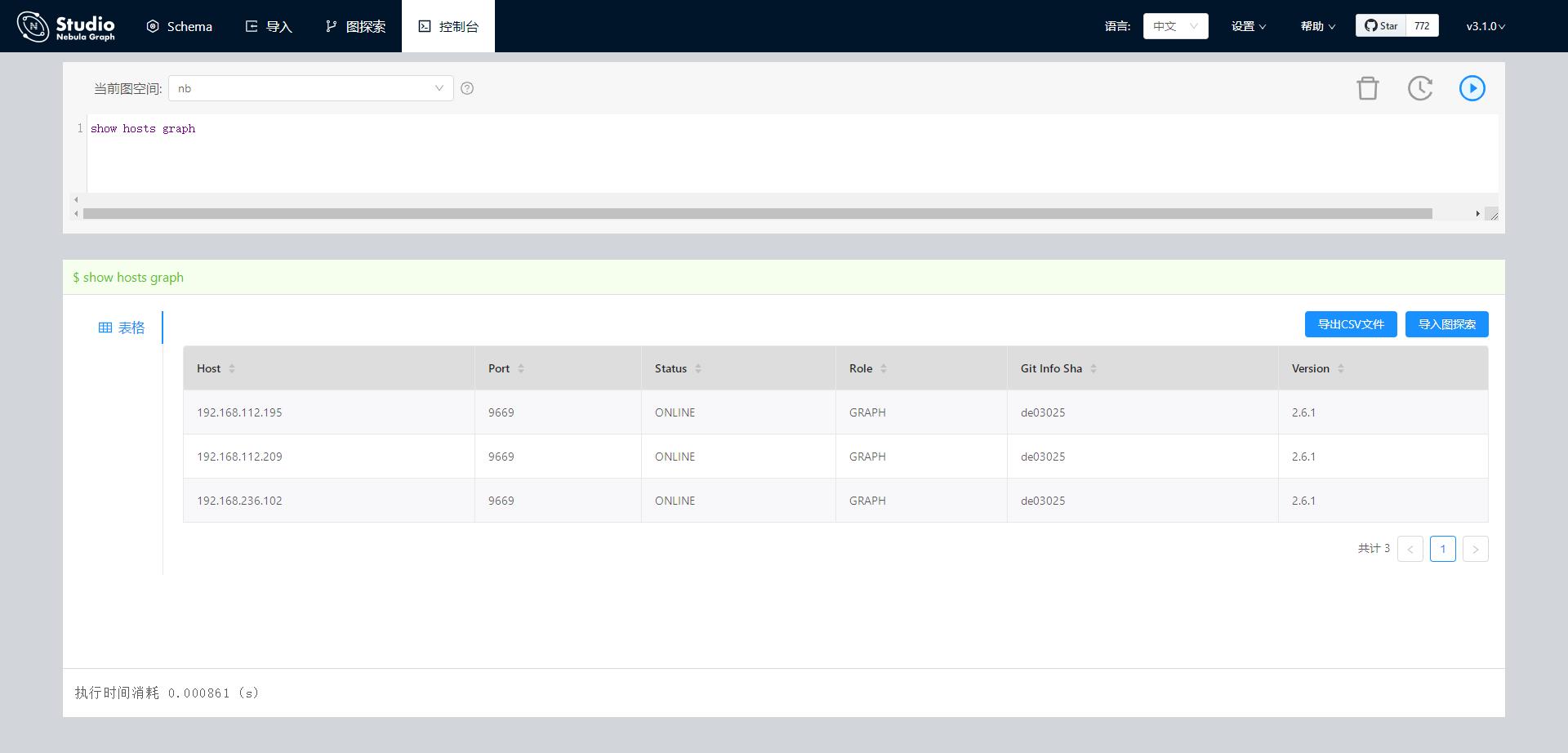
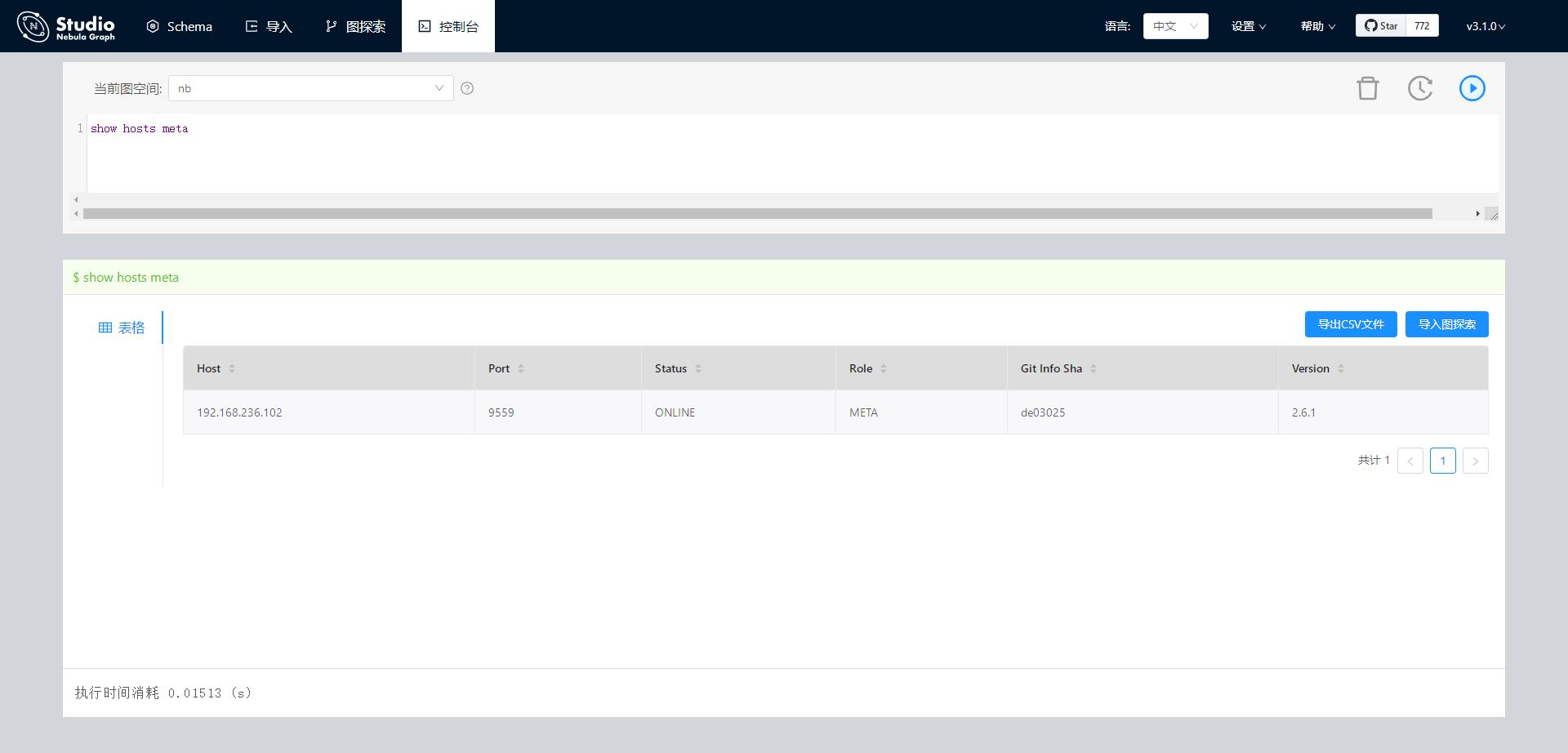

写入Nebula时的日志都贴出来看下吧,写入失败时failed execs: List()这里面会有值的。

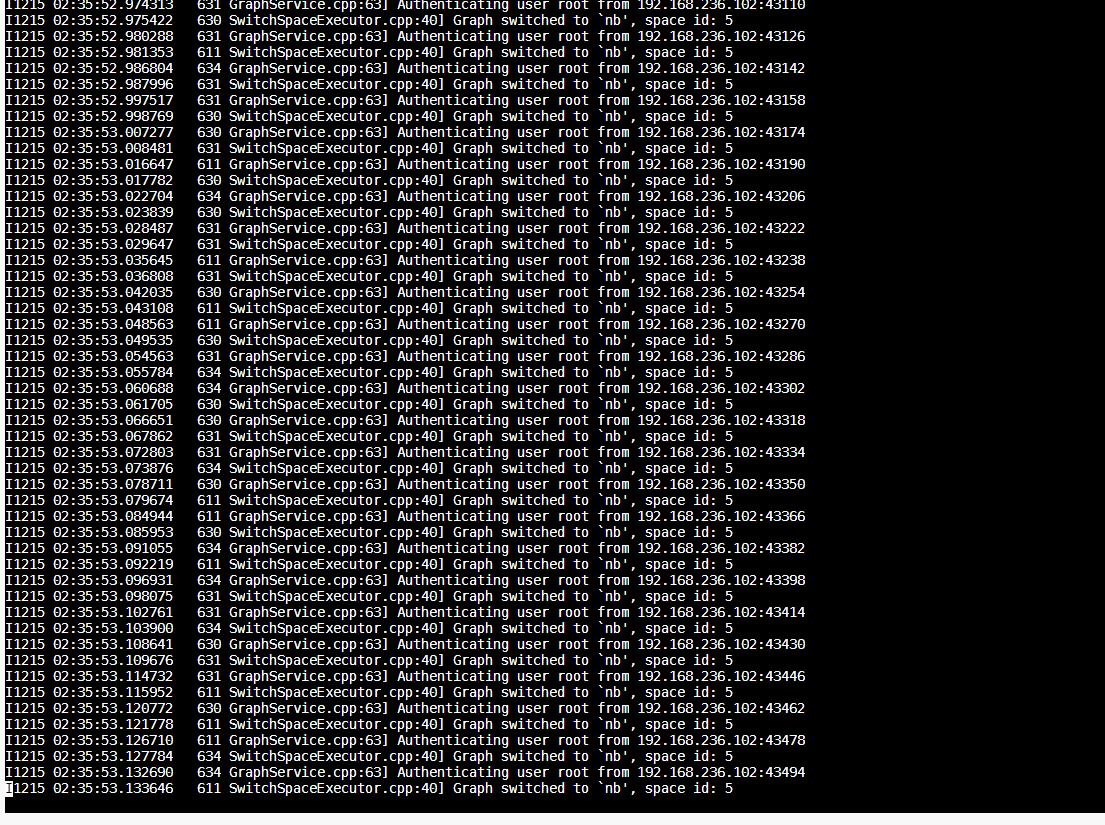
看日志并没有写入失败,而是无数据写入。
你的源数据方便发一下么,我这边走一下,有数据的话int类型的pagerank属性肯定会报错的,你日志里都没有报错信息。
我用的是你们提供的basketballplayer数据集,做了点改动,就是把ID都里的player和team去掉了,只保留整数,然后在serve和follow类型的边最后一列随机加了权值
edge_follow.csv (1.9 KB)
edge_serve.csv (4.6 KB)
vertex_player.csv (1.1 KB)
vertex_team.csv (382 字节)
我用你的edge_follow边数据去跑pagerank,结果存入nebula是可以的啊。
(root@nebula) [test]> desc tag pagerank
±-----------±---------±------±--------±--------+
| Field | Type | Null | Default | Comment |
±-----------±---------±------±--------±--------+
| “pagerank” | “double” | “YES” | | |
±-----------±---------±------±--------±--------+
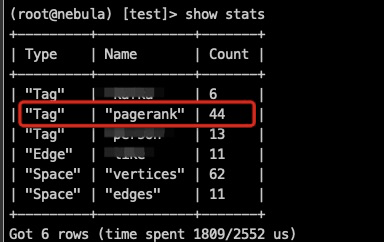
那么数据应该是没有问题的,方便将您提交任务时的application.conf文件发我看看嘛?会不会是我里面哪个参数没有设置对
{
# Spark relation config
spark: {
app: {
name: PageRank
# spark.app.partitionNum
partitionNum:100
}
master:local
}
data: {
# data source. optional of nebula,csv,json
source: csv
# data sink, means the algorithm result will be write into this sink. optional of nebula,csv,text
sink: nebula
# if your algorithm needs weight
hasWeight: false
}
# Nebula Graph relation config
nebula: {
# algo's data source from Nebula. If data.source is nebula, then this nebula.read config can be valid.
read: {
# Nebula metad server address, multiple addresses are split by English comma
metaAddress: "127.0.0.1:9559"
# Nebula space
space: nb
# Nebula edge types, multiple labels means that data from multiple edges will union together
labels: ["serve"]
# Nebula edge property name for each edge type, this property will be as weight col for algorithm.
# Make sure the weightCols are corresponding to labels.
weightCols: ["start_year"]
}
# algo result sink into Nebula. If data.sink is nebula, then this nebula.write config can be valid.
write:{
# Nebula graphd server address, multiple addresses are split by English comma
graphAddress: "192.168.8.170:9669"
# Nebula metad server address, multiple addresses are split by English comma
metaAddress: "192.168.8.170:9559"
user:root
pswd:nebula
# Nebula space name
space:test
# Nebula tag name, the algorithm result will be write into this tag
tag:pagerank
}
}
local: {
# algo's data source from Nebula. If data.source is csv or json, then this local.read can be valid.
read:{
filePath: "file:///tmp/edge_follow.csv"
# srcId column
srcId:"_c0"
# dstId column
dstId:"_c1"
# weight column
#weight: "col3"
# if csv file has header
header: false
# csv file's delimiter
delimiter:","
}
# algo result sink into local file. If data.sink is csv or text, then this local.write can be valid.
write:{
resultPath:/tmp/count
}
}
algorithm: {
# the algorithm that you are going to execute,pick one from [pagerank, louvain, connectedcomponent,
# labelpropagation, shortestpaths, degreestatic, kcore, stronglyconnectedcomponent, trianglecount,
# betweenness, graphtriangleCount]
executeAlgo: pagerank
# PageRank parameter
pagerank: {
maxIter: 10
resetProb: 0.15 # default 0.15
}
}
}
还有 关于上面我说的将double类型的pagerank值写入int类型的属性时会报错,我试了下nebula2.6.0上没有报错,针对这个问题我提了个issue https://github.com/vesoft-inc/nebula/issues/3473

我把double,string,int等格式都试了一遍,结果都一样,应该和格式无关吧
你可以在本地用debug模式执行algorithm中的main, 看看提交给nebula的insert语句是啥。
断点可以加在 com.vesoft.nebula.algorithm.writer.AlgoWriter 的41行, 对data执行下data.show()
可以详细一点嘛?小白一枚不太理解 