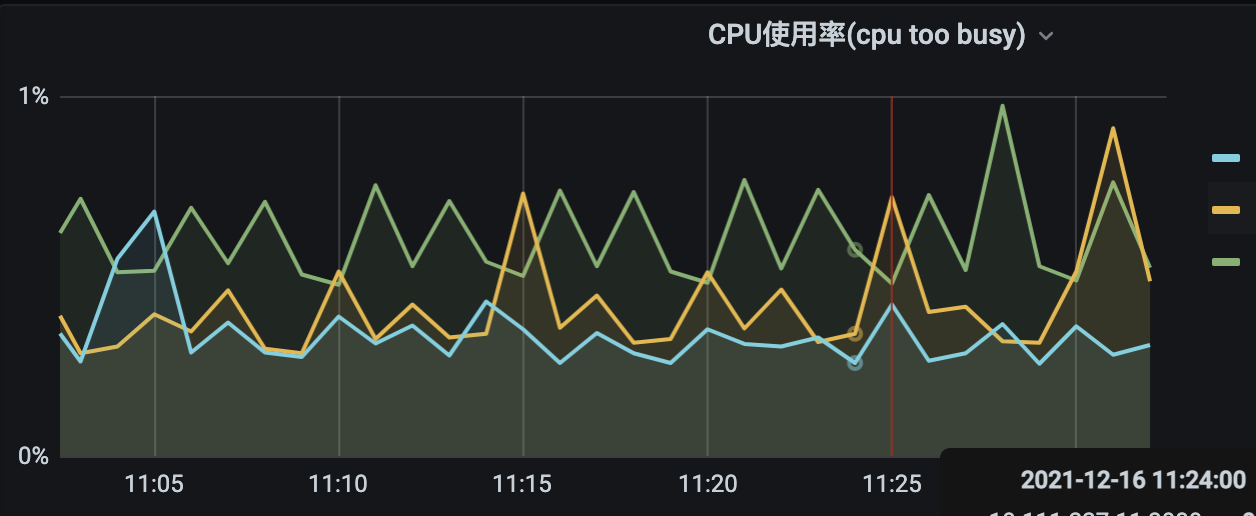
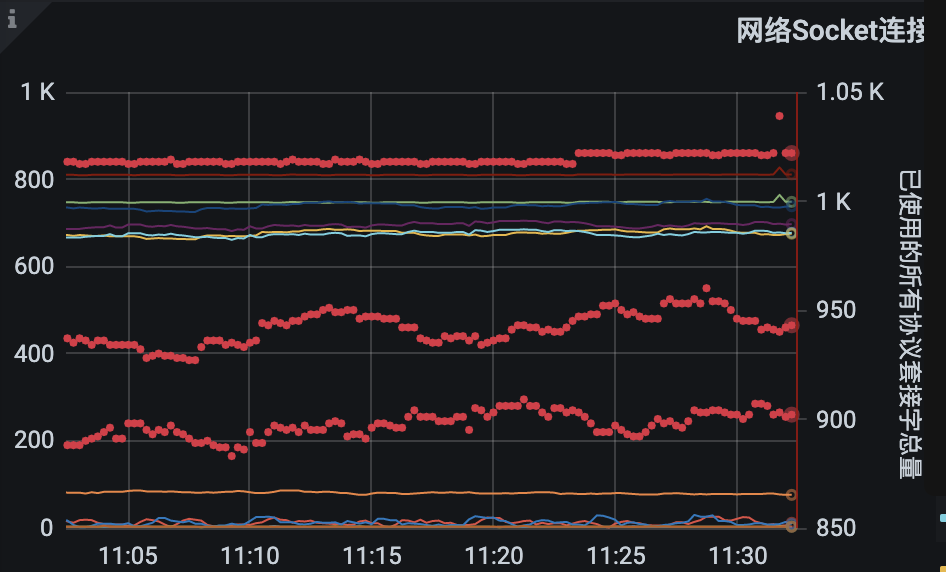
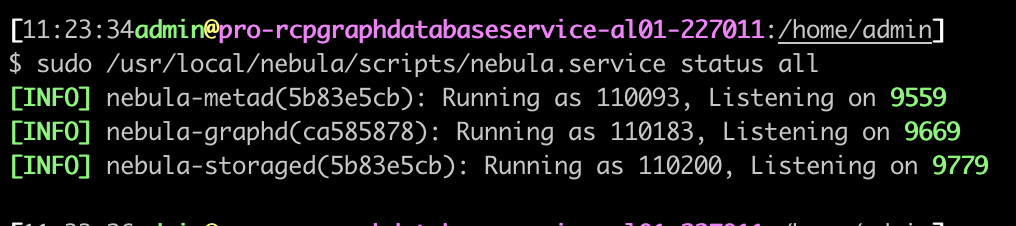
已经获取到边表的schema信息,
2021-12-15 11:27:12,908 INFO NebulaDataSourceEdgeReader: dataset's schema: StructType(StructField(_srcId,StringType,false), StructField(_dstId,StringType,false), StructField(_rank,LongType,false), StructField(eventcode,StringType,true), StructField(latest,StringType,true), StructField(Rank,StringType,true))
然后读取数据时报错,如下:
2021-12-15 11:27:13,416 INFO NebulaDataSource: create reader
2021-12-15 11:27:13,416 INFO NebulaDataSource: options {spacename=hitch, nocolumn=false, metaaddress=10.111.227.11:9559,10.111.227.12:9559,10.111.97.3:9559, label=relation, type=edge, connectionretry=3, timeout=300000, executionretry=2, paths=[], limit=1000, returncols=eventcode,latest,Rank, partitionnumber=50}
2021-12-15 11:27:13,420 INFO DataSourceV2Strategy:
Pushing operators to class com.vesoft.nebula.connector.NebulaDataSource
Pushed Filters:
Post-Scan Filters:
Output: _srcId#0, _dstId#1, _rank#2L, eventcode#3, latest#4, Rank#5
Exception in thread "main" com.facebook.thrift.transport.TTransportException: java.net.SocketTimeoutException: connect timed out
at com.facebook.thrift.transport.TSocket.open(TSocket.java:175)
at com.vesoft.nebula.client.meta.MetaClient.getClient(MetaClient.java:104)
at com.vesoft.nebula.client.meta.MetaClient.doConnect(MetaClient.java:99)
at com.vesoft.nebula.client.meta.MetaClient.connect(MetaClient.java:89)
at com.vesoft.nebula.connector.nebula.MetaProvider.<init>(MetaProvider.scala:22)
at com.vesoft.nebula.connector.reader.NebulaSourceReader.getSchema(NebulaSourceReader.scala:45)
at com.vesoft.nebula.connector.reader.NebulaSourceReader.getSchema(NebulaSourceReader.scala:36)
at com.vesoft.nebula.connector.reader.NebulaDataSourceEdgeReader$$anonfun$2.apply(NebulaSourceReader.scala:121)
at com.vesoft.nebula.connector.reader.NebulaDataSourceEdgeReader$$anonfun$2.apply(NebulaSourceReader.scala:120)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.immutable.Range.foreach(Range.scala:160)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at com.vesoft.nebula.connector.reader.NebulaDataSourceEdgeReader.planInputPartitions(NebulaSourceReader.scala:120)