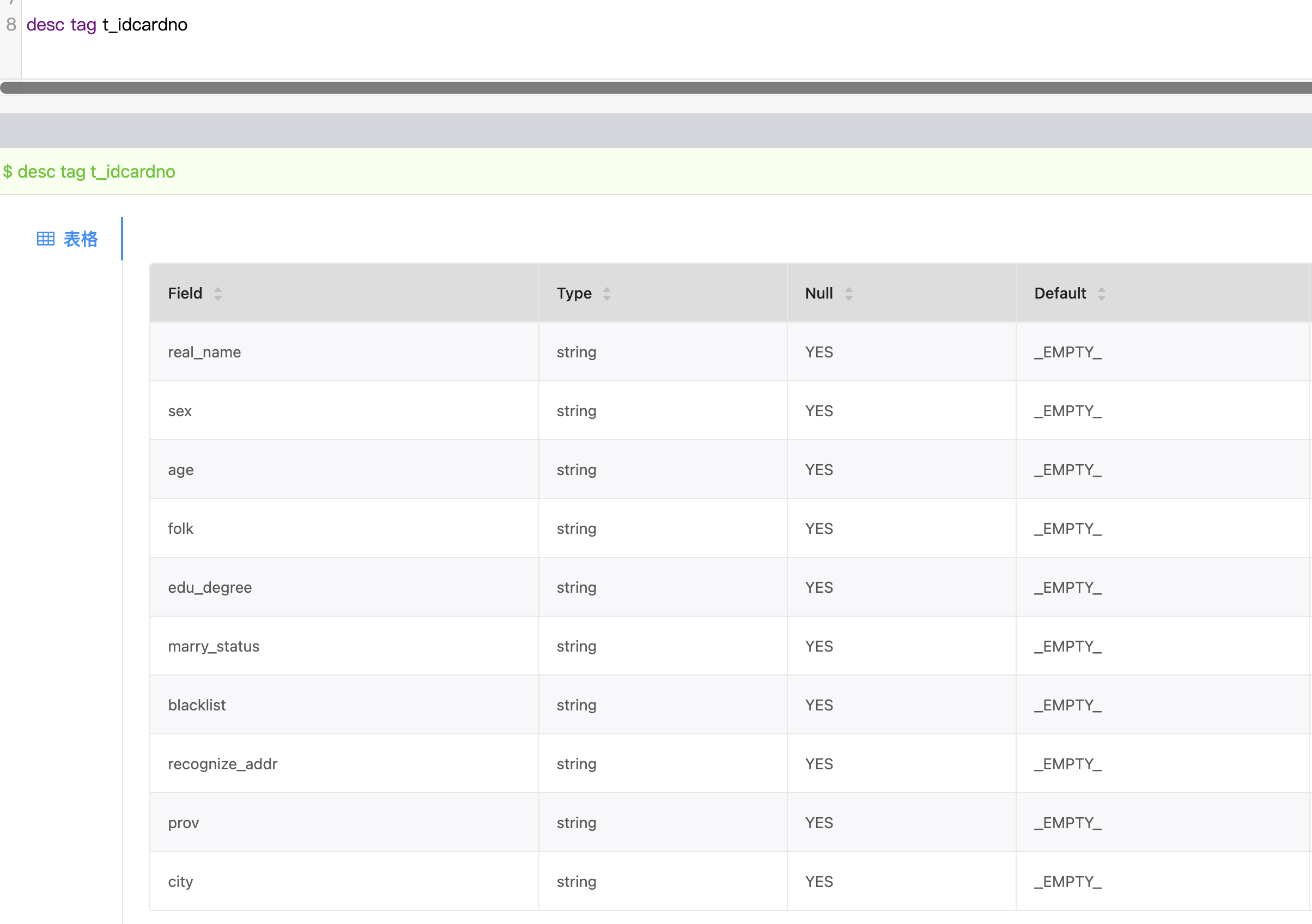
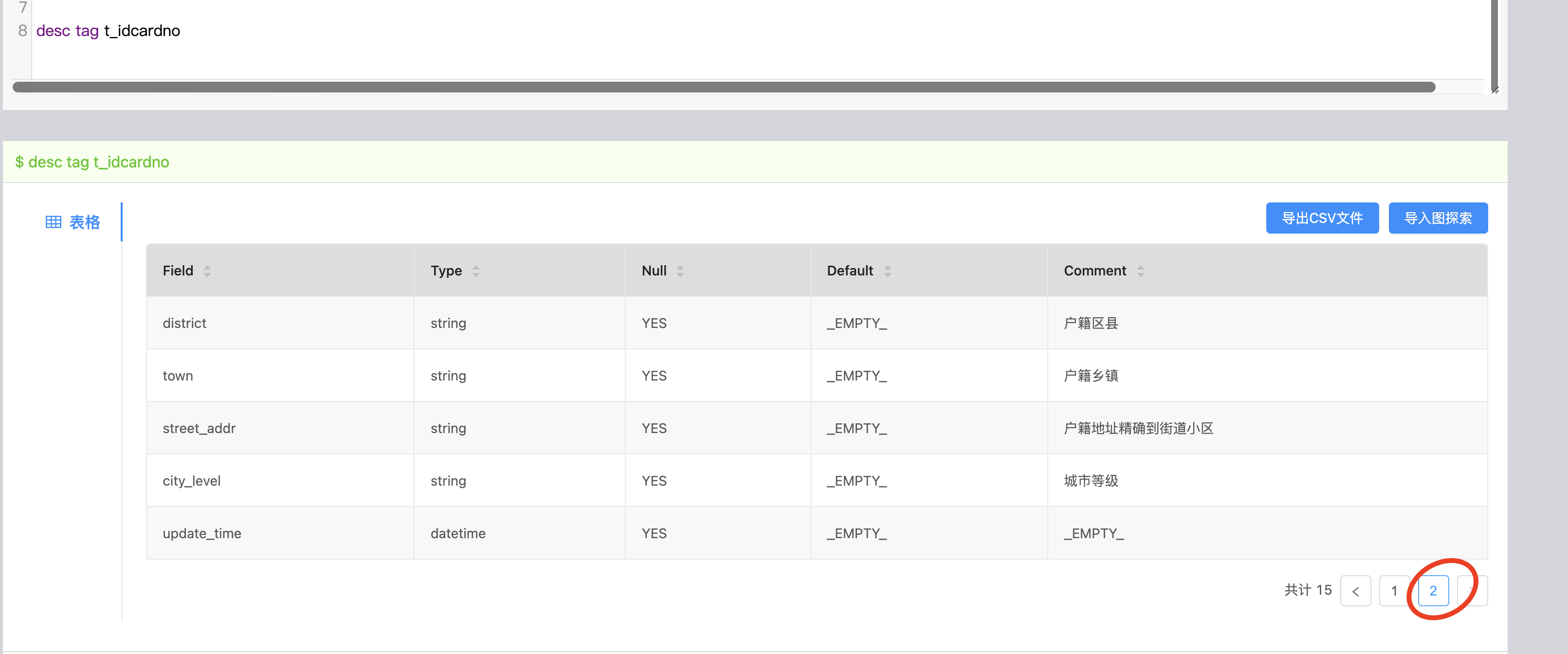
desc tag :
{
spark: {
app: {
name: Nebula Exchange 2.0
}
driver: {
cores: 2
maxResultSize: 5G
}
cores {
max: 16
}
}
nebula: {
address:{
graph:["10.xx:9669","10.xx:9669","10.xx:9669","10.xx:9669","10.xx:9669"]
meta:["10.xx:9559","10.xx:9559","10.xx:9559"]
}
user: root
pswd: "脱敏"
path : {
local:"/tmp/sst"
remote:"/tmp/sst"
hdfs.namenode: "hdfs://nameservice1:8020"
}
space: s_vcredit
connection {
timeout: 60000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/errors/t_idcardno
}
rate: {
limit: 1024
timeout: 10000
}
}
tags: [
{
name: t_idcardno
type: {
source: hive
sink: sst
}
exec: "select identity_no,real_name,sex,age,folk,edu_degree,marry_status,blacklist,recognize_addr,prov,city,district,town,street_addr,current_timestamp() as update_time from dwd.dwd_vcredit_graph_idcardno_node_df where dt='vardate'"
fields: [real_name,sex,age,folk,edu_degree,marry_status,blacklist,recognize_addr,prov,city,district,town,street_addr,update_time]
nebula.fields: [real_name,sex,age,folk,edu_degree,marry_status,blacklist,recognize_addr,prov,city,district,town,street_addr,update_time]
vertex:{
field:identity_no
}
batch: 256
partition: 32
}
]
}