氪金
1 个赞
目前怀疑是 Cache 导致的 要想查看具体是那个对象占用的 估计需要把内存dump 出来 然后GDB 查看 还是很复杂
实在不行就重启这个Storage 节点吧
查一下这台机器上 storage 的配置,block_cache 是多少。
进入到 /storaged/nebula/5322/data 里面有 LOG 文件,看看有没有 compact 的信息。
1 个赞
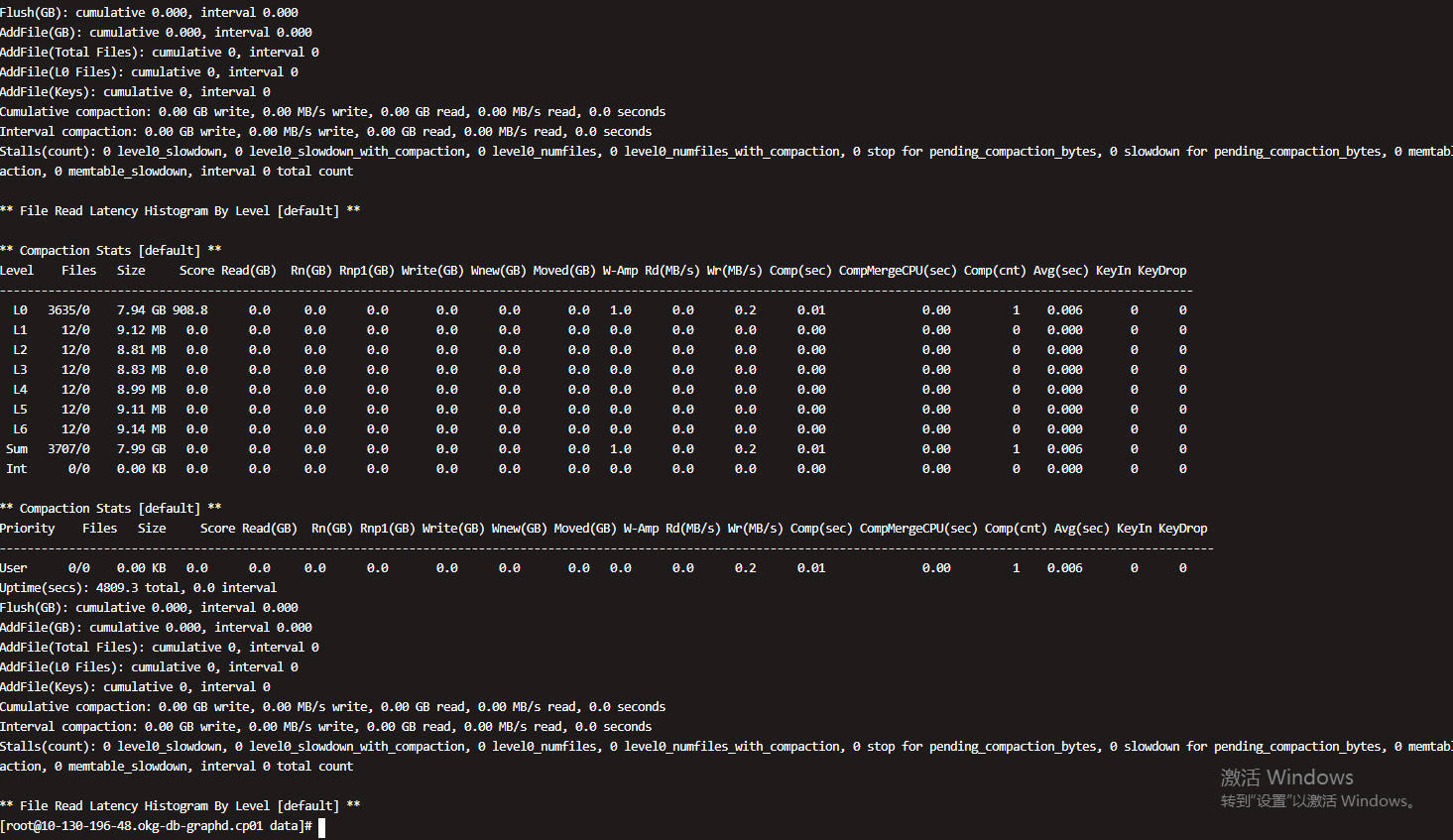
LOG 文件看上去没有compact
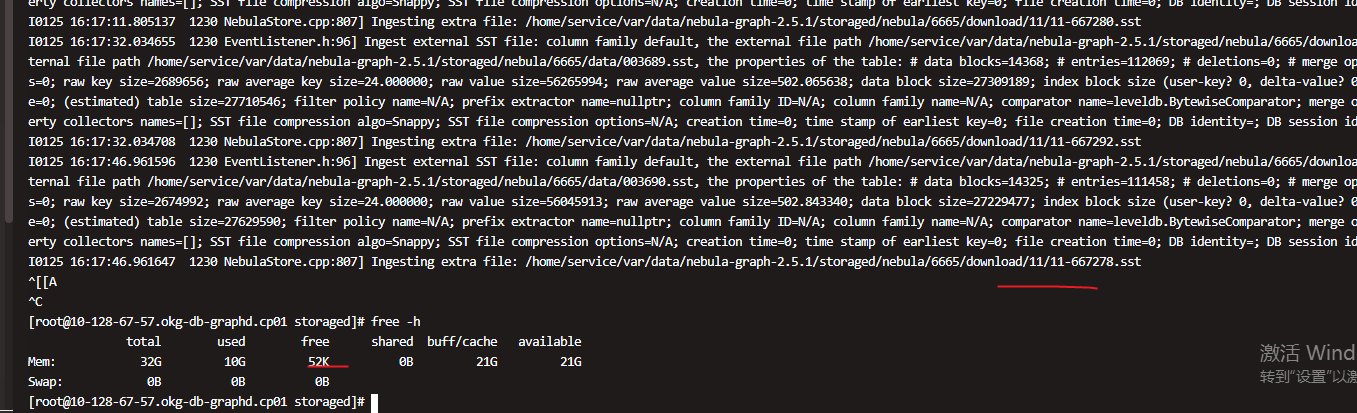
还有我导入重启了storaged ,再次导入内存一下又不足了,一个节点卡住了,还有你这个是每个storaged节点,异步同时ingest 吗,这边发现12 节点,有正常节点几分钟ingest 完了,如果一个节点内存不足就卡了,其他节点没有日志显示没有启动ingest ??,还是要排队???
这些到底什么问题啊,感觉很不稳定,帮忙看看
这个有12storaged节点,ingest 我看日志感觉不是12个同时异步启动导入,是只有部分同时,有几个是延迟启动的,这个内部是这个逻辑吗??
这边反复测试已经确定。只要内存不足sst ingest 就卡主了,我重启storage 释放内存,再重新ingest 速度又快了,但是导入一下内存又占满了卡住了。这个怎么处理啊
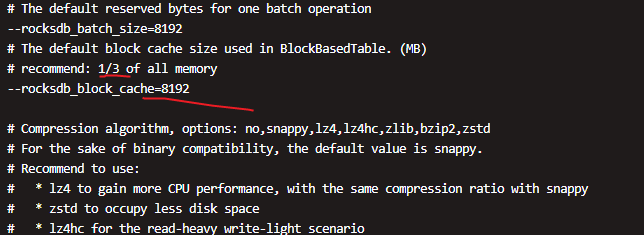
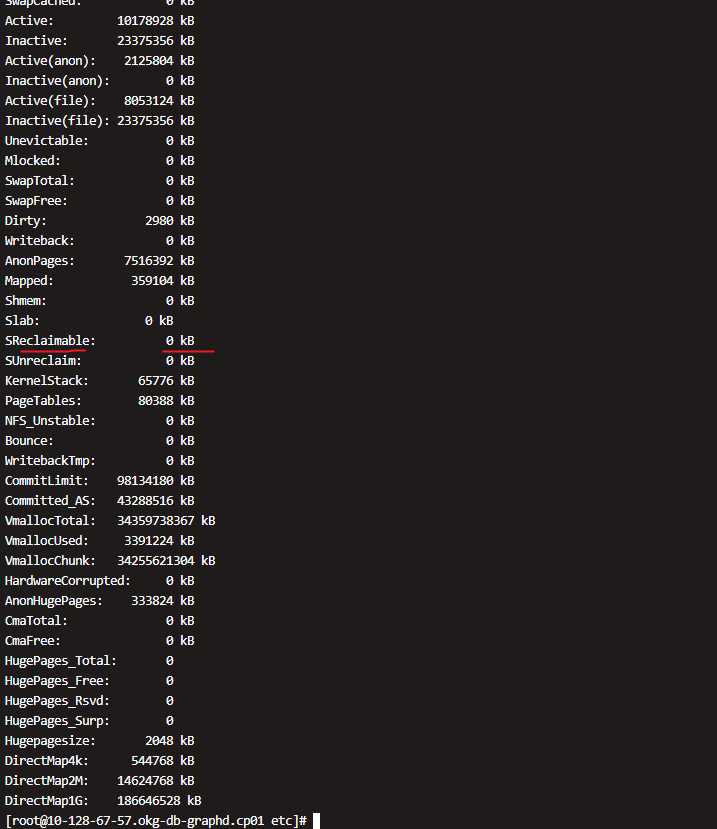
大神可留个电话吗,这边和你电话沟通一下,这边发帖说不清,这边生产环境使用比较急,麻烦了
盲猜的话,就是你生成 SST 的时候,spark 的 partition 数太多了。
然后同一个 part 的两个 sst 之间有 overlap,导致 sst 都在 L0 上。看日志有 30G 的数据,那 compact 就很慢的。
解决办法:
- 生成 SST 数目小一点,减少 overlap 的可能性,新版本有个repartitionWithNebula, support custom partitioner for nebula when generate sst files by Nicole00 · Pull Request #49 · vesoft-inc/nebula-exchange · GitHub
- 如果不方便用最新的 exchange,可以手动 ingest 一下。就是把 download 里的 sst 文件,先放一部分。然后 ingest 后,做一次 compact,然后等 compact 好了以后,再放一部分。。
目的就是让每次 compact 的数据少一点,不要有这么大的数据量。
日志是有compact 吗,我不是把compact 自动配置关掉了呀,怎么还会compact ??
我这边是2.5.1 的nebulaGraph ,可以使用最新的exchange兼容吗?
- 最新的 exchange 不兼容 2.5.1
- 可能就是因为你把自动 compact 给关了,然后不断重启尝试,导致 L0 数据太多。建议就还是先手动做一次 compact,把 L0 的数据先推到更底层的 level
还有缓存打满,内存不足,这个问题怎么处理??这个是sst 导入慢的原因吗??我这边测试每次不足sst ingest 就卡主了,这个是到底是compact 引起还是内存不足问题啊
这边是重新导入的一个新的图,只导入一次也是这种情况,有的节点快,有的节点没有同时异步启动等待好久才有日志显示启动。这个是什么问题
你说的这个一部分一部分sst 的到,我怎么分??,我看是根据分区数量生成的文件夹。我可以任意取几个文件夹,导入一次,再导入剩下的文件夹吗,这个需要什么规则和顺序吗? 还是任意取部分就行
取任意部分就行。
你后来试过先 compact 么?做完 compact,再看一下之前的 LOG 文件,看看 L0 的大小是不是小了。
1.我先compact 一次后第二次ingest 是快了,但是一次compact有个别storage 也卡主了要很久这个什么问题我要看那个日志??导致这个整体时间还是不快啊,
2.还有我重新开始导入一个新空的新图,也有出现卡主的情况,这是都没有数据怎么也卡主了??
repartitionWithNebula 每次生成一个有序的SST Ingest 确实不会引起Compact 但是下次Ingest 的时候肯定会出现overlap 且 SST文件会非常大
我现在是这样的,我先生成sst 文件,然后下载到download 目录 再ingest 导入,我就一次ingest 一个新的空图,但是数据有几千个sst 文件总共80G,按照上面的。我一部分一部分的导入,但是如果每导入一次就compact 一次,这样整体耗时也会不快,这个问题到底怎么解决啊,大神帮忙分析一下
那就每次都生成一个 每个分区一个SST文件 的数据 download下来在Ingest 这样没有overlap 也不需要 compact了