我们在实时插入 Nebula 的数据时, 遇到了性能问题, 数据库中有10亿级别的数据,按照官方建议配置了 3个节点, 180个partition,每天百万级的插入/更新操作, 希望数据能实时写入, Nebula。 但是实际操作时遇到了严重的瓶颈问题, 求助:
- 锁: 当插入Vertex的时候,是否有锁? 锁是什么级别? 锁的粒度是多大? 主要的性能瓶颈会卡在哪里?
- 有没有相关性能报告? 在这个规模级别上, 理论的插入速度能达到多少条/秒
- 有没有最佳实践方面的建议?
谢谢!
我们在实时插入 Nebula 的数据时, 遇到了性能问题, 数据库中有10亿级别的数据,按照官方建议配置了 3个节点, 180个partition,每天百万级的插入/更新操作, 希望数据能实时写入, Nebula。 但是实际操作时遇到了严重的瓶颈问题, 求助:
谢谢!
您好,感谢您的使用,请问是否创建了tag index?
用哪种方式插入的?spark writer 还是 go importer?
用哪个接口 insert vertex insert edge 还是upsert
一个请求写多少条记录?
有没有带属性索引
日志级别?
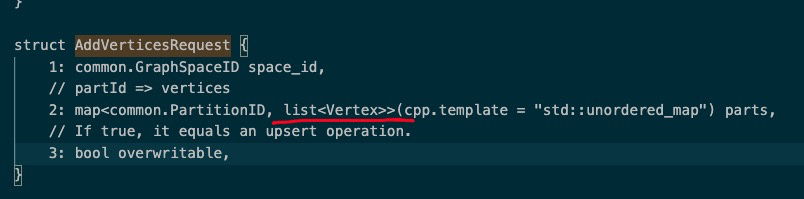
edge tag 是空的, vertex 的 tag 没有做index
python api 写入的, upsert vertex, tag 没有建索引
upsert 内部有一个相当于是 partition级的表.
什么意思? upsert 这个操作是锁partition 吗? ![]()
是滴… 所以你那个10亿分180个part, 用upsert的话, 相当于 500万级的串行. 建议用insert, 没有这个问题.
![]() 大吃一惊!
大吃一惊!
多谢! 我们先去试一下
如果用 insert 的话, 按照官方建议配置, 能达到多少条插入/秒?
一般是 30万-50万条
了解了, 多谢!
是的,1000个一组batch,会好很多。
不需要原子性的地方,就不要用upsert了。
可以考虑把属性作为 本节点近邻的节点: A(prop1, prop2) 改成A->prop1 和A->prop2 改变构图,这样可以直接用insert。
也不建议把partition数量变超大(10万),这样 raft 心跳上压力会很大
谢谢各位的回复!