还是不太明白“样本点”,我理解的“样本点”是指从测试用的 csv 文件读出的 “点”,不知道理解的对不对?
对的,就是这个意思,一共采用了多少点呢?是全部都取了出来么?
请问下 k6 压测的代码能否贴出来?
想问一下,我用16核 128G 7.5T机械跑的话,性能会差多少?
样本点一共 448626,全部取出
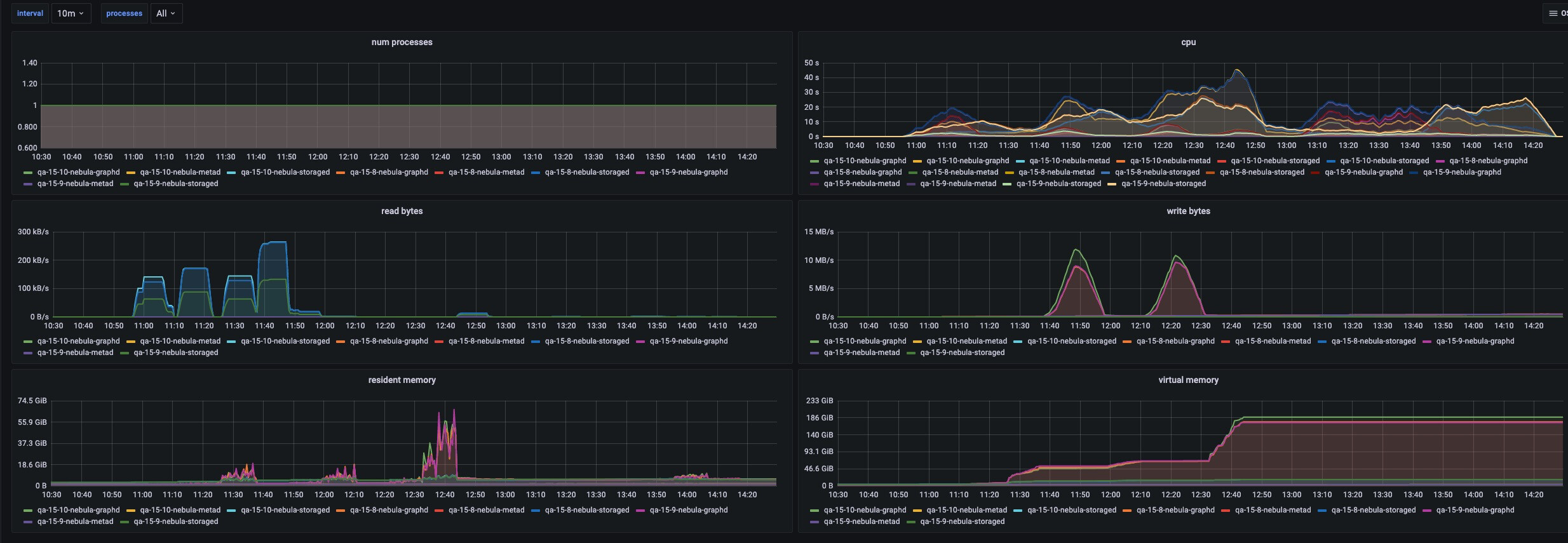
你好,你比较关注哪些用例的avg性能和机器负载?全部贴出太多了
最好能贴出来全部的,一共是9个进程的监控数据 应该不会很多吧,每类角色把数据做下聚合
另外这里面我看数据是24分区,集群部署我看是3行,是不是一个进程加载了24个分区的数据?
想请问一下,match 索引查询,索引是Tag 索引 还是 单属性索引?
单属性索引(Person的firstName属性)
1 个赞




请参考 GitHub - vesoft-inc/nebula-bench: Collection of benchmark services and tools for Nebula Graph 这个工程
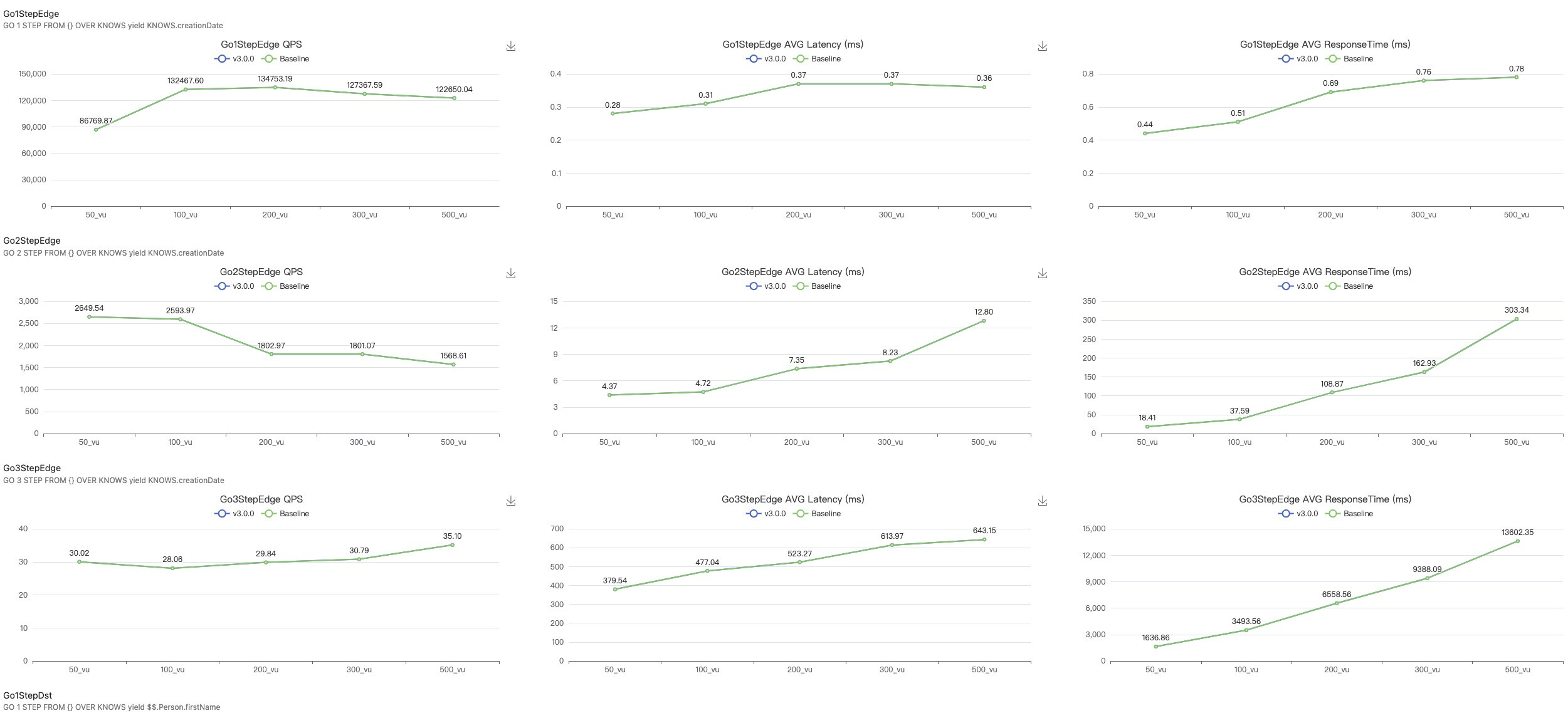
这些指标有没有解释?图表需要说明下
另外现在你们压测客户端的超时时间设置的是多大?
求一份3.0.0 升级到3.0.2的小版本升级文档
收到 谢谢
24个分区的leaders是均匀的分布在三个storage吗?即每个storage负责8个分区的leaders?
是的
1 个赞
高并发下,qps上不去,是因为cpu被打满吗?压测时的cpu指标有吗?