试试 FETCH PROP ON serve 100->204@7
这种方法是有结果的,但是当我用复合查询的时候,将前面语句的结果作为FETCH PROP ON的查询对象,我怎么能获取每天边的rank值,例如用下面这种语句查询的情况:
GO FROM 100 OVER serve YIELD dst(edge) AS id |
GO FROM $-.id OVER serve YIELD src(edge) AS s, dst(edge) AS d |
FETCH PROP ON serve $-.s → $-.d YIELD properties(edge).start_year;
GO FROM 100 OVER serve YIELD dst(edge) AS id |
GO FROM $-.id OVER serve YIELD src(edge) AS s, dst(edge) AS d, rank(edge) as r |
FETCH PROP ON serve $-.s → $-.d@$-.r YIELD properties(edge).start_year;
这样可以了,非常感谢!
提到rank我又想到了使用中遇到的一个问题,就是当我有些边的起点和终点一致,有的时候边上的属性也会有一致的情况下,添加数据的时候,即使rank不一样,属性值相同的只能写入一条边,这个怎么解决,比如边上的属性值代表交易额,出现交易双方一样,交易额一样的情况,只能添加一次,添加多次也无效
1 个赞
<起点, 终点, 边类型, rank> 唯一确定一条边, 和属性没关系,所以只要确定 前面四元组唯一就行
现在的问题是如果跑louvain算法要带权计算的话,权值只能放在rank上才能作为权值带入计算,放到其它属性上无法作为权值带入计算,这个之前在这个帖子里提到过:跑louvain算法时hasweight参数选择true时(即边上有权值)计算结果有问题 - #7,来自 nicole
那么就不可避免会出现多条起始点一样,rank一样的边的情况了
边属性可以作为权重列,用于跑louvain算法,我用的2.6.1刚试了
2 个赞
我原来用的也是2.6.1,问题就在于hasweight参数设置为true时,用属性值作为权重跑louvain算法出来的结果两列是完全一模一样的,就是把所有点都单独划分为一个社区了,你这边出来的结果会吗?根据之前你们工作人员Nicole的反馈,把权值放在rank,出来的结果就正常了,可以参考我当时反馈问题的帖子:跑louvain算法时hasweight参数选择true时(即边上有权值)计算结果有问题 - #7,来自 nicole
1 个赞
你好,2.6.1带权跑louvain的结果两列会完全一致嘛?
我试着把权重放在边属性上了,这是一个最小的例子,不知道能不能给你参考到。
https://gist.github.com/wey-gu/64e213d882c4b036ba2be5bd61c7050d
1 个赞
我看你用的是2.6.2的jar包嘛?这个要到哪里下载,我目前只有2.6.1的
wget https://repo1.maven.org/maven2/com/vesoft/nebula-algorithm/2.6.2/nebula-algorithm-2.6.2.jar
这也是前几周的一个新的 release(github 里有),主要解决 meta 域名格式地址的问题
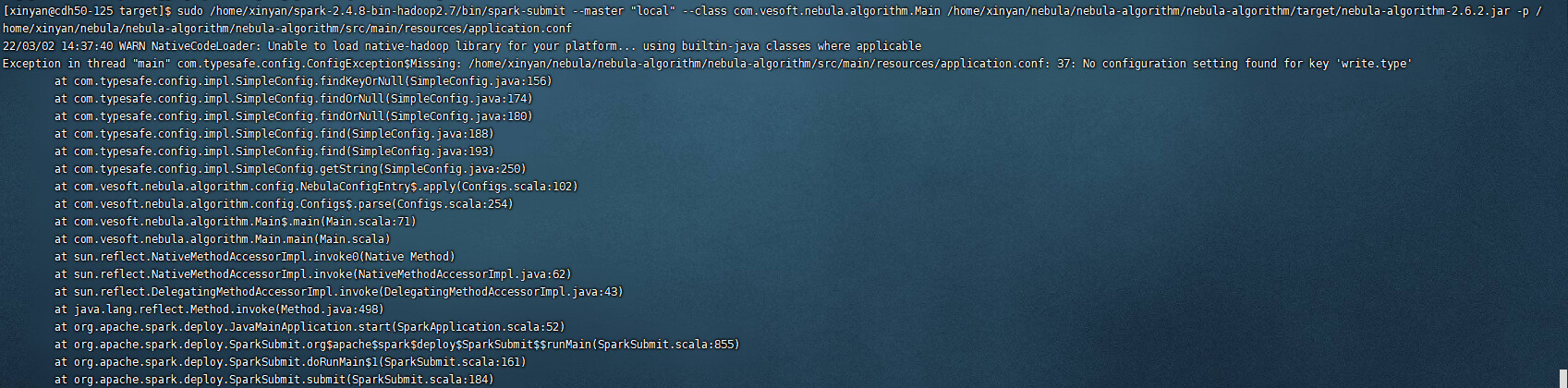
看报错,是writer.type 的配置要求的问题,这个jar就是二进制可以直接用的哈
那会是什么原因呢?我用你给的那个2.6.2.jar就报错,换成原来的算法包就可以正常提交任务了,其他东西都没动过 
会不会和我的nebula_graph版本为2.6.1有关?
看报错直接指向 nebula:write.type 您是不是没有这个配置?
# Nebula Graph relation config
nebula: {
#….
}
# algo result sink into Nebula. If data.sink is nebula, then this nebula.write config can be valid.
write:{
# …..
type:insert #<——————————这个选项是不是没写?
}
}
2.6 内部小版本之间彼此都是兼容的
我结果保存设置的是local的csv,和nebula里write的参数无关吧?
应该是 2.6.2 加进来的逻辑,非 nebula sink 也强制要求了 type,这里不太友好了。我提一个 issue 去,不过看报错你得先把 nebula write type 写到配置里让它开心 