- nebula 版本:2.0.1
需求:要统计某个标签所有节点的关系之和。如 标签 tag_A 下有两个节点,节点1的关系数量是2,节点2的关系数量是3。要求的结果是返回 5
我使用的语句是 match p=(a:tag_A)–() return count(p)
发现 tag_A 标签节点数据量大的时候要跑很久。
有没有什么方案可以实现这个功能呢
需求:要统计某个标签所有节点的关系之和。如 标签 tag_A 下有两个节点,节点1的关系数量是2,节点2的关系数量是3。要求的结果是返回 5
我使用的语句是 match p=(a:tag_A)–() return count(p)
发现 tag_A 标签节点数据量大的时候要跑很久。
有没有什么方案可以实现这个功能呢
tag 是从属于 vertex 的,边是 vertex 之间的联系,![]() 你是不是混淆了两者的关系。其实你的需求是不是只要统计边的数据量就好了。
你是不是混淆了两者的关系。其实你的需求是不是只要统计边的数据量就好了。
举个例子,有一个tag是“运动员”,有“姚明”、“乔丹”两个 vertex。现在要返回的是这两个vertex关联的边的总量
其实就是想返回有“运动员”这个标签的所有节点关联的边的总和
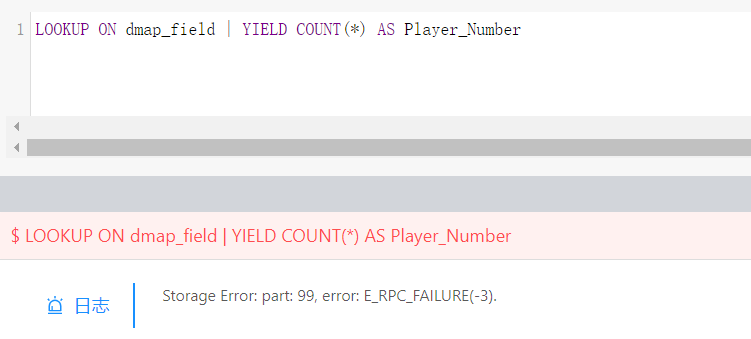
这个case我们并没有太多的优化,性能上比较友好一点的话可以尝试用lookup | go 去优化一下。
这个一开始尝试过了,一样很慢 
目前没有更好的方法了
如果这是个经常用到的需求,在storage lookup那里加个拿点关系数量的查询节点就好了 
这个看整个tag 统计的情况还是用 show stats,参考一下文档,需要配合 submit job stats 异步的统计任务
执行submit job stats 需要God角色。而运行程序中配置的账号不会给到这个权限。所以我们才通过lookup去统计。
应该提个需求,
把执行job的权限单独拿出来,可以grant。
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。