提问:
-
nebula 版本:
-
部署方式:分布式 (3)
-
安装方式:Docker
-
是否为线上版本: N
-
硬件信息
- 磁盘( HDD)
- CPU Intel(R) Xeon(R) Silver 4210R CPU @ 2.40GHz
- 内存 188 G
-
问题的具体描述
创建 Tag player(name string,age int)导入100W条数据
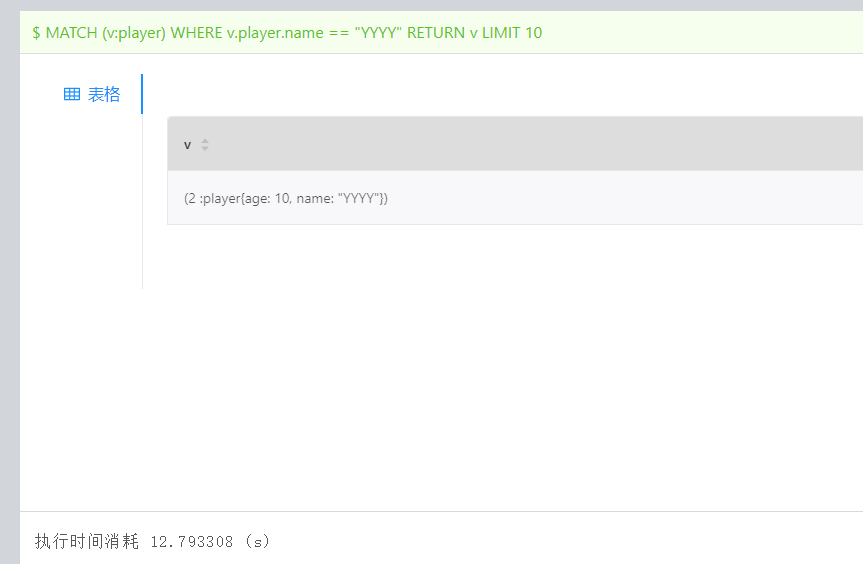
创建 player 的索引 index_player 并 rebuild进行以下查询

查询时间较长,需要10s多
图空间信息

提问:
nebula 版本:
![]()
部署方式:分布式 (3)
安装方式:Docker
是否为线上版本: N
硬件信息
问题的具体描述
创建 Tag player(name string,age int)导入100W条数据
创建 player 的索引 index_player 并 rebuild
进行以下查询
查询时间较长,需要10s多
图空间信息
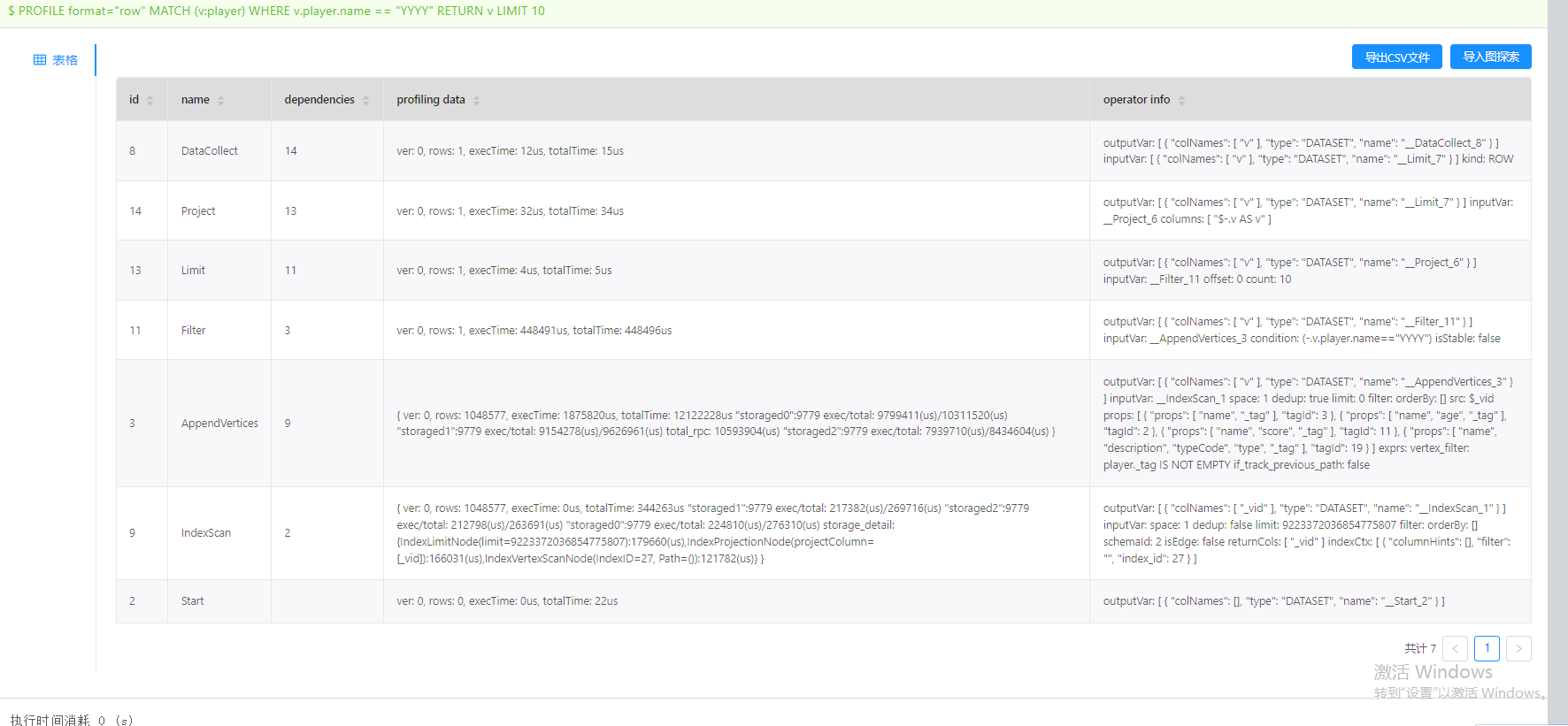
来,在你的 MATCH 语句前面加一个 PROFILE,看下执行计划
不好意思,match相关几个优化规则不在社区版中。你这种场景使用的话需要建立player.name的索引才能匹配到。