- nebula 版本:2.5.0
- 部署方式:单机
- 安装方式:Docker
- 是否为线上版本:N
- 硬件信息
- 磁盘( 推荐使用 SSD) 1T
- CPU 8核
- 内存 32G
- 问题的具体描述
部署单机图库(graphd、storaged、metad服务各为一个),使用exchange导入亿级数据并发过高时会一直报插入失败;后续一直将batch、partition参数不断调小测试仍未解决;即使batch调为4, partition调为2,虽然报错率减少,但跑到后续触发reload job又会出现高并发插入导致报错的场景。请问在不增加机器资源和改变图库架构,有什么办法可以解决此问题? - 相关的 meta / storage / graph info 日志信息
graph log:
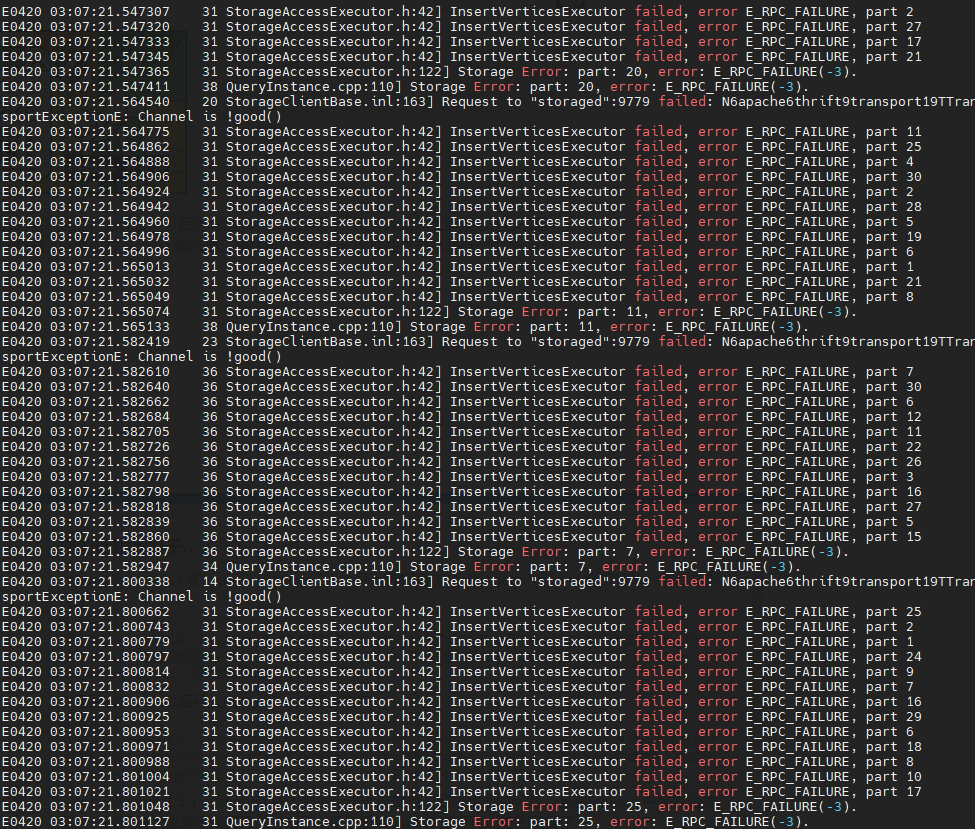
spark log:

代码 / 终端输出 / 日志…


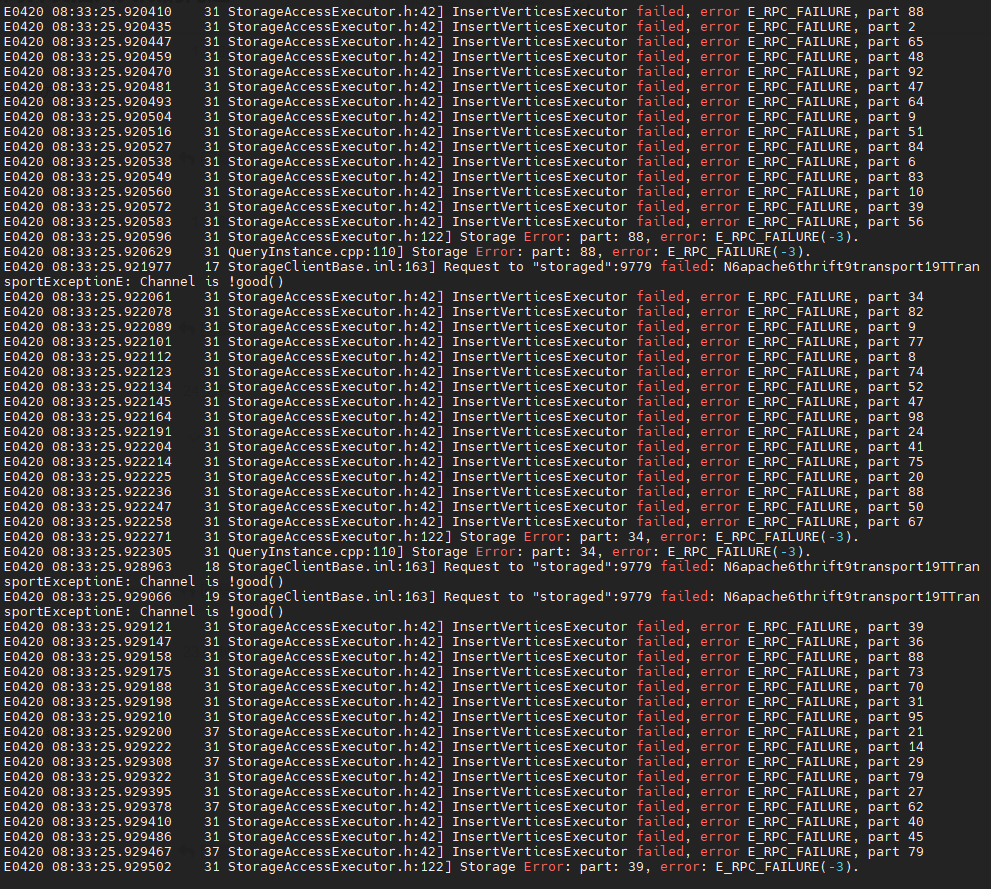

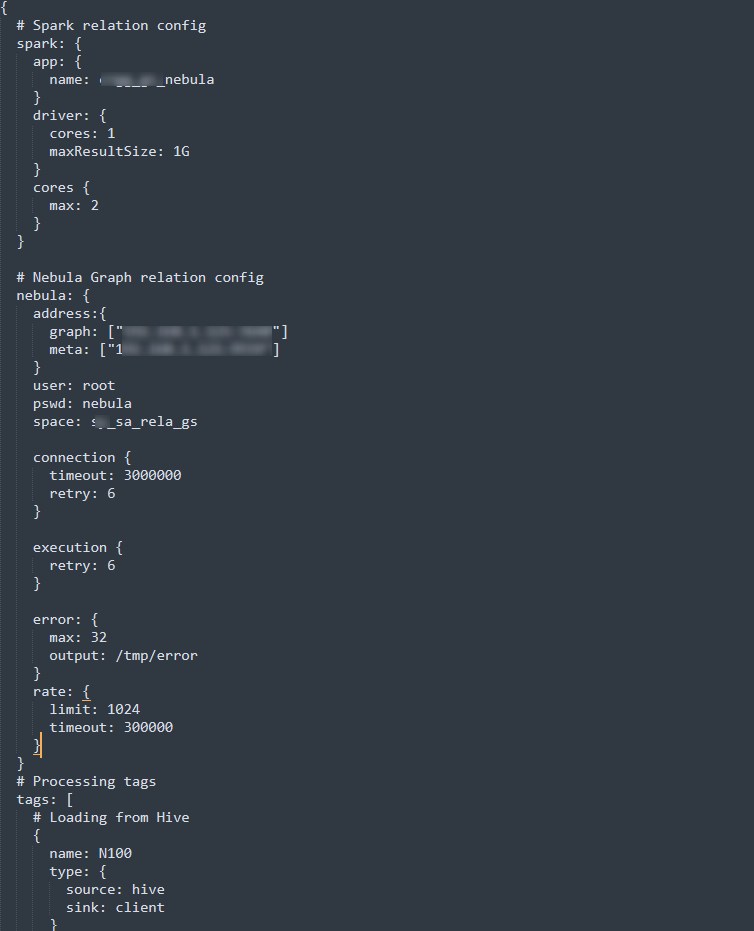
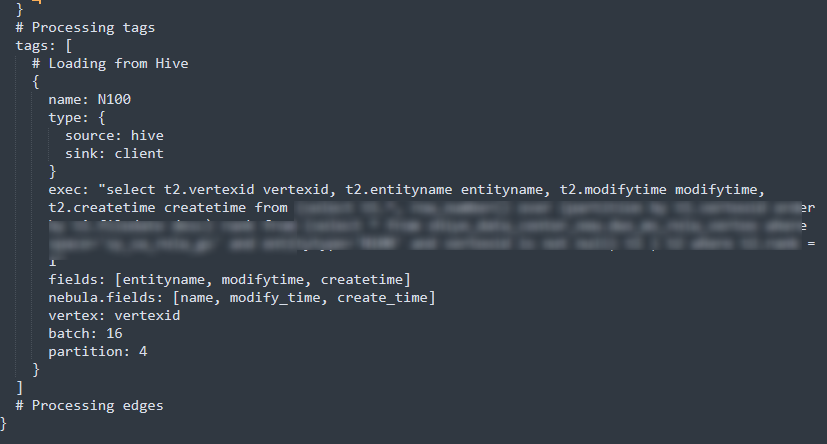


 我没设置到最详细日志等级,起码没有报错信息
我没设置到最详细日志等级,起码没有报错信息