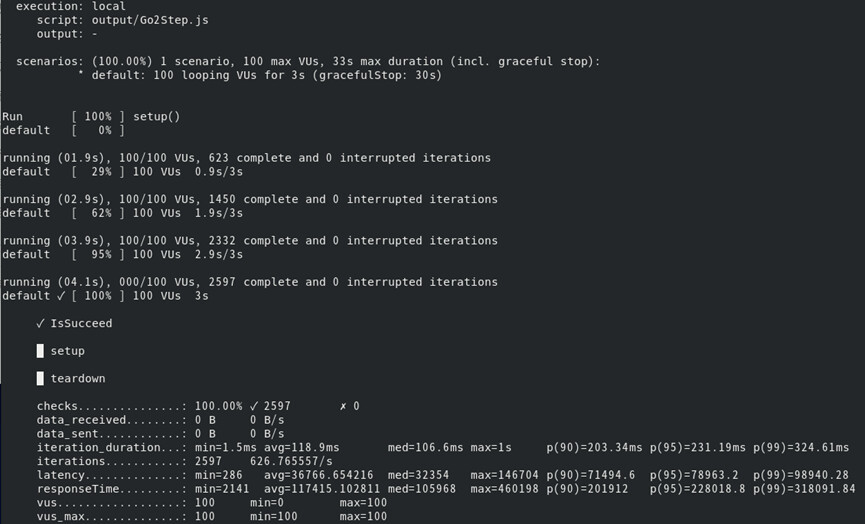
- nebula 版本:v3.0.0
- 部署方式:单机
- 安装方式: RPM
- 硬件信息
- 磁盘 :SSD
- CPU、内存信息
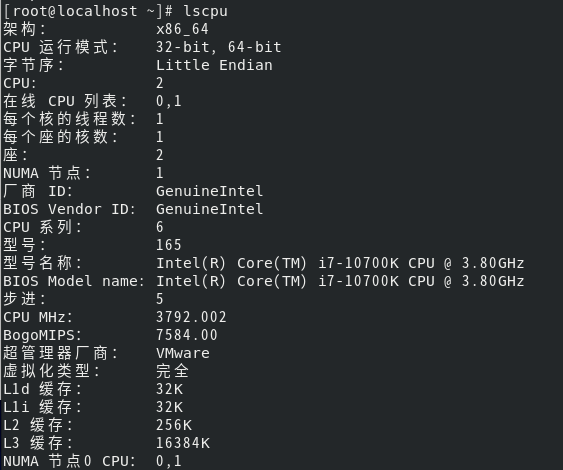
k6版本号:

主要问题:
首先当把nebula graph和k6安装好了以后,可以通过nebula-console连接nebulagragh成功

按照https://github.com/vesoft-inc/k6-plugin步骤去运用k6连接nebula,会出现一个GoError,具体信息以及js文件如下:
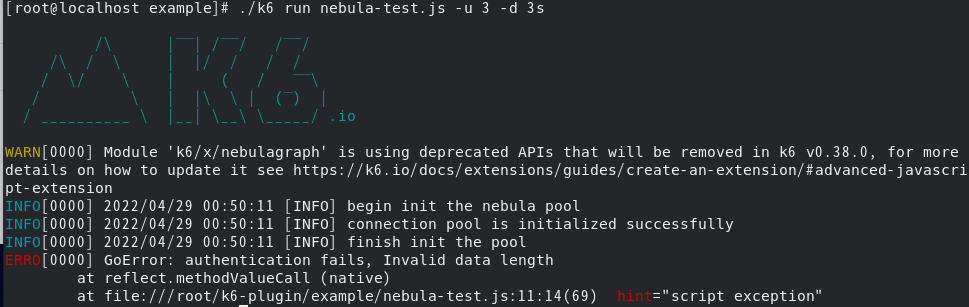
其中nebula-test.js的内容如下:
import nebulaPool from 'k6/x/nebulagraph';
import { check } from 'k6';
import { Trend } from 'k6/metrics';
import { sleep } from 'k6';
var lantencyTrend = new Trend('latency');
var responseTrend = new Trend('responseTime');
// initial nebula connect pool
var pool = nebulaPool.init("127.0.0.1:9669", 400);
// initial session for every vu
var session = pool.getSession("root", "nebula")
session.execute("USE ldbc")
export function setup() {
// config csv file
pool.configCSV("person.csv", "|", false)
// config output file, save every query information
pool.configOutput("output.csv")
sleep(1)
}
export default function (data) {
// get csv data from csv file
let d = session.getData()
// d[0] means the first column data in the csv file
let ngql = 'go 2 steps from ' + d[0] + ' over KNOWS '
let response = session.execute(ngql)
check(response, {
"IsSucceed": (r) => r.isSucceed() === true
});
// add trend
lantencyTrend.add(response.getLatency());
responseTrend.add(response.getResponseTime());
};
export function teardown() {
pool.close()
}
经过一行行验证,出错位置为:
var session = pool.getSession("root", "nebula")
随后尝试在nebula中开启身份验证

运行后依然报错,随后修改root密码再次运行
运行结果依然报错: