Dashboard相关介绍可以查看: 什么是 Nebula Dashboard - Nebula Graph Database 手册

这是昨天的图像 这个显示内存都集中到一台了 这个怎么回事
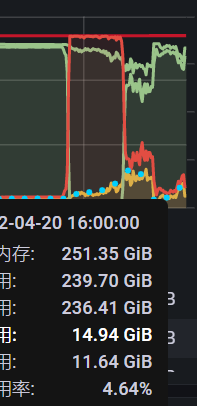
5月三号那个是三台服务器内存都打满了 ,这个需要更改什么配置
storaged对内存的使用基本都来源于rocksdb。对于读,rocksdb对内存的使用主要是block cache和page cache。对于写,对内存使用只有memtable和触发的compaction。你的操作是upsert,同时涉及读和写。
对读来说,block cache大小通过conf里rocksdb_block_cache调节,rocksdb可控。page cache就是OS的page cache,rocksdb无法控制。因此如果block cache size设置合理的话,对于读,问题很可能出在page cache上。对于写,如果存在大量的update,可能触发大量compaction,造成严重的写放大,造成mem使用率增高,磁盘I/O bandwidth使用率增高, 甚至不可用。
有以下可能的解决方法:
(1)conf里disable_page_cache设置成true以关闭page cache。我知道有些人会argue说利用操作系统的page cache在block cache不够的时候可以提高性能,但这个坏处以我的观点其实更大。因为第一mem不可控,第二完全可以通过增大block cache来解决。而且FB内部都是关闭page cache的。
(2)如果你不愿意关闭page cache,那么考虑其他优化的点。比如如果你的SST file size比较大,但是key-value又比较小,那么可能造成index数目太大。而index blocks默认不是在block cache里,会占用page cache。因此可以考虑在conf里添加一项: --enable_partitioned_index_filter = false 以打开cache_index_and_filter_blocks in block cache。或者,也可以在--rocksdb_db_options={}添加max_open_files=<some number>来限制index filter的数目,但这可能会影响性能。
(3)你可以检查dashboard里磁盘的性能指标,看看当时磁盘的IO情况。同时看看storaged的日志看看当时compaction情况。如果是compaction导致的内存占满的话,说明资源不够,建议添加磁盘,rebalance。
1 个赞

你重新提个问题,上面的是内核的开发。
感谢发现dashboard的问题。请重开一个帖子,会有相关人员处理的。
另外,虽然dashboard出错了,但是长远来看,使用dashboard查看各个指标的状况才是定位问题的正确方法。优先级甚至是高于日志的。请坚持使用。
您好 我想问下compaction 这个需要去定时单独执行吗?
不用,compaction 会在每天自己触发执行一次的,不需要定时去手动执行。
感谢两位的支持,通过服务器监控检查应该是写放大问题,已经标注解决方案,再次感谢
1 个赞
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。