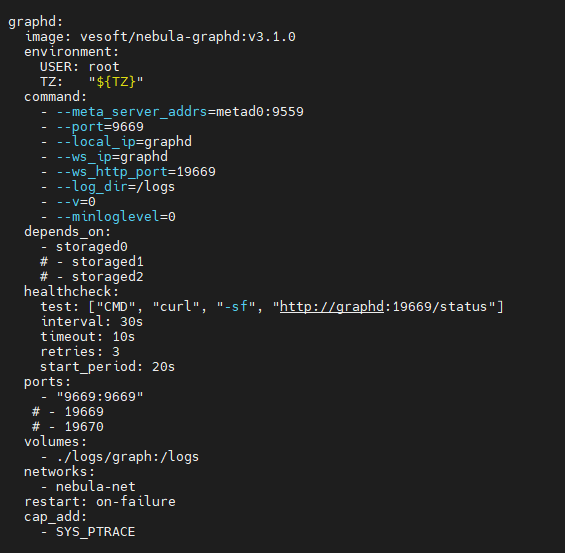
nebula 版本:v3.0.0https://github.com/vesoft-inc/nebula-bench/blob/release-1.2/README_cn.md
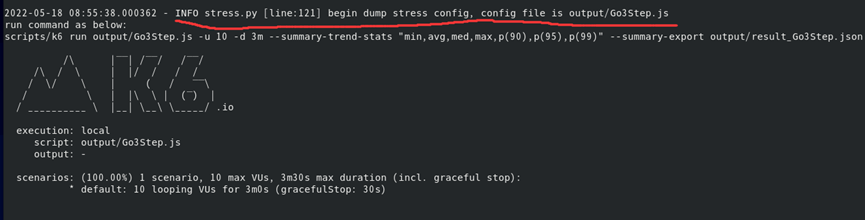
2.注意到运行的时候有一行这个
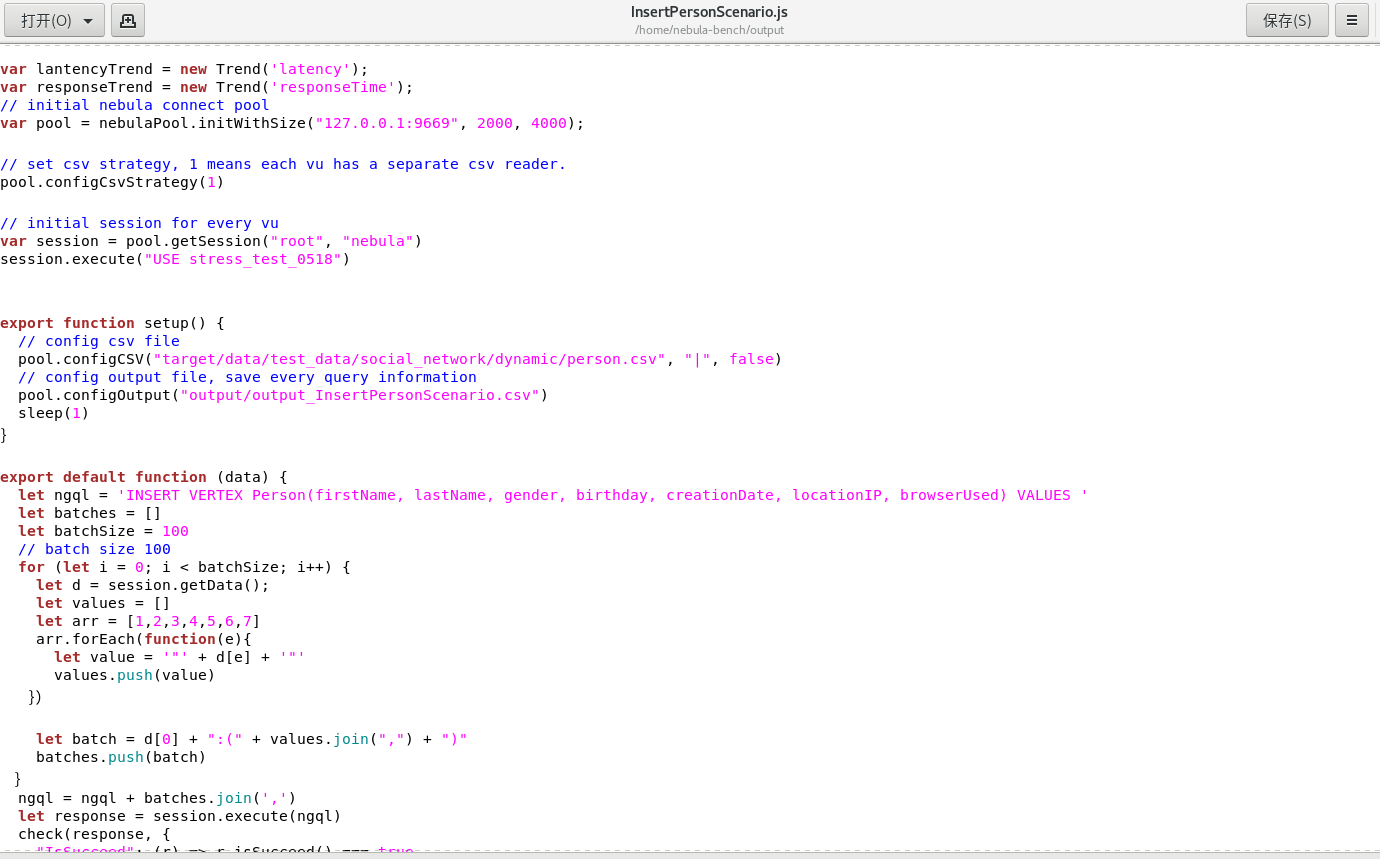
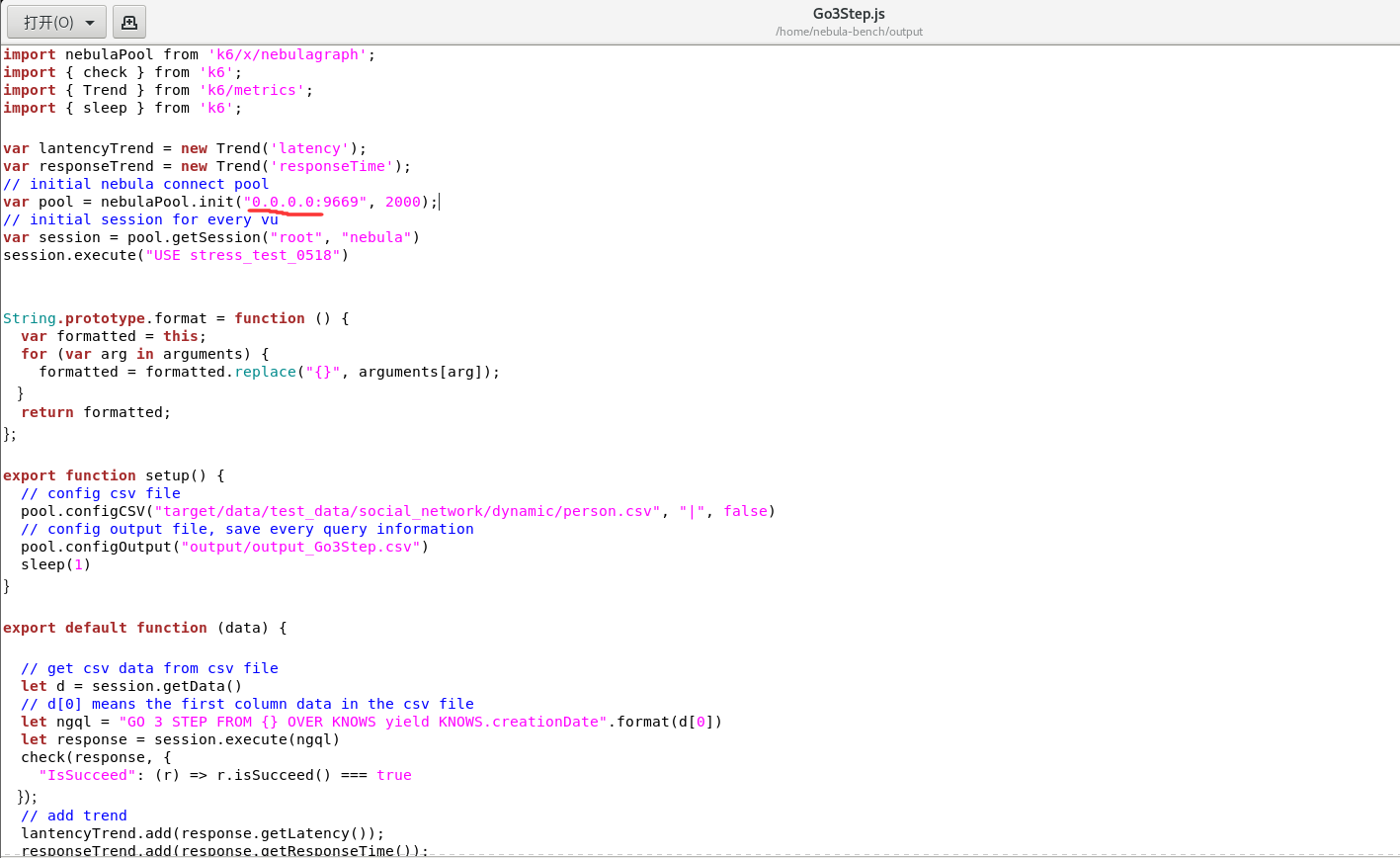
想知道这个生成js的config文件是在哪里
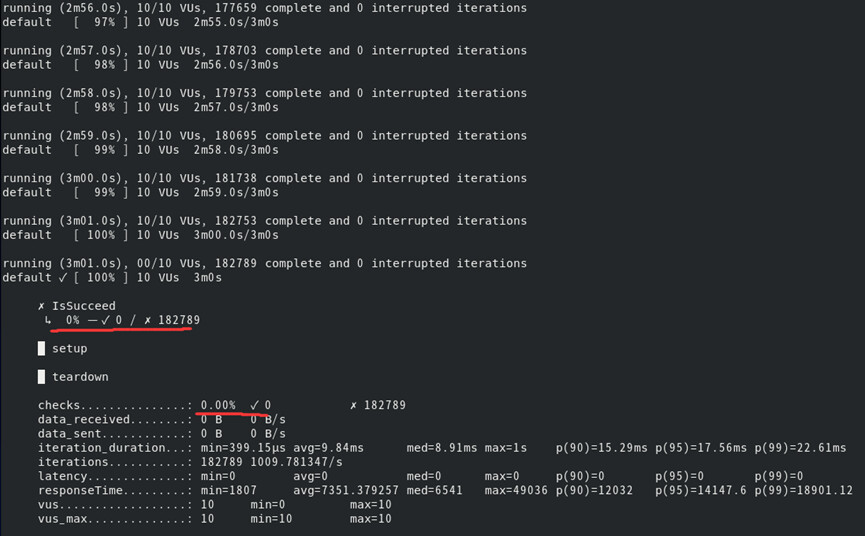
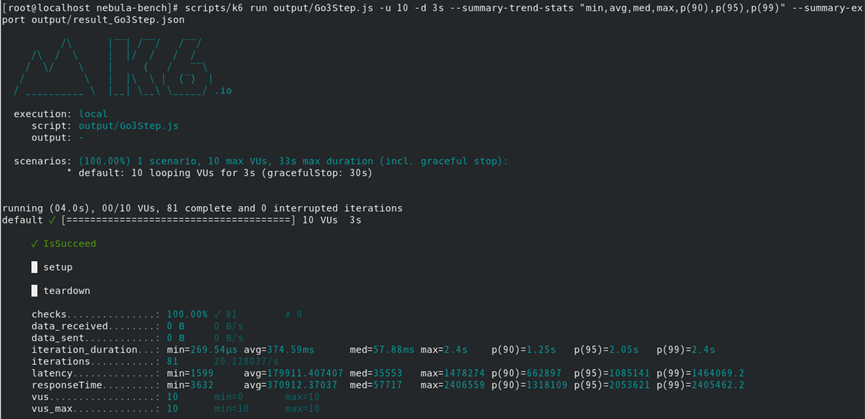
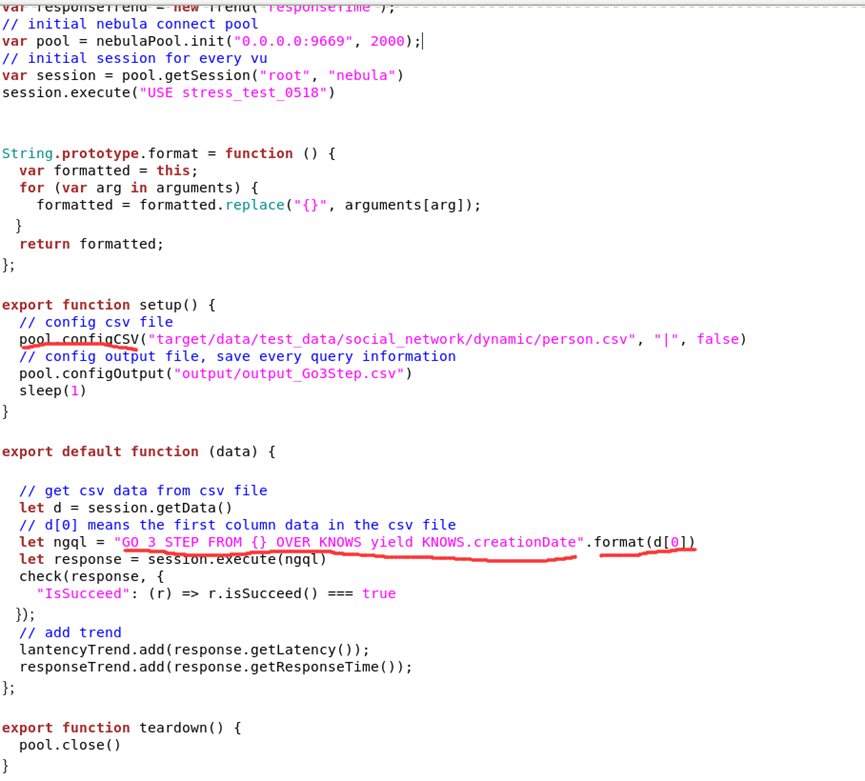
3.另外就是这里只自动生成了五个语句的js脚本,之后可能会测试其他语句,就想试试能不能像importer导入一样进行手动手动导入,就把上图中第三行单独拎出来进行了一下测试
想要了解一下这样测试的数据是不是跟直接用脚本测试的数据是一样的,会不会有区别
4.在测试过程中发现一个问题,在
这个ip地址不管怎么输入好像都可以进行测试并且都可以正常运用k6得到结果而且看起来没有什么错误,想知道是什么原因
5.如果我想测试别的语句比如fetch,match或者LOOKUP之类的查询语句,是不是只要修改对应的ngql语句然后具体VID的位置用大括号标起来就可以了
就比如修改成像3.0测试报告里的语句(例如:FETCH PROP ON Person {} YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed)然后执行相应的scripts/k6 run output/FETCH.js -u 10 -d 3s --summary-trend-stats “min,avg,med,max,p(90),p(95),p(99)” --summary-export output/result_FETCH.json其中json文件和相应的output.csv文件它可以自动生成的
这样对么
1.还是想知道这一步var pool = nebulaPool.init(“0.0.0.0:9669”,2000)为什么可以执行起来,是因为只是单节点的部署么,如果是多节点部署是不是会有不同的要求,那这个时候地址是不是就不能出错?
user22:
0.0.0.0:9669
多个 graph 是 192.168.1.1:9669,192.168.1.2:9669,192.168.1.3:9669
看一下 data 和 wal 分别的大小,刚导完数据 wal 也比较大,等 wal_ttl 过了就会自动清https://docs.nebula-graph.com.cn/3.1.0/5.configurations-and-logs/1.configurations/4.storage-config/#raft
那大概这个比率是多少呢,毕竟如果要执行导入肯定是要有足够的空间才能导入成功的,像这边30G都要三倍多了,是都按照这个比率算么,还是数据集越大这个比率可能也会越大,比如如果要导入100G的话,大概需要多少空间
还是说当硬盘空间满了以后他会先停止导入,等到wal_ttl它的Raft WAL 的有效时间过了以后,它会开始自动清理,完成了以后会继续执行导入,还是说必须得等数据导入完了之后,它才会开始计算Raft WAL 的有效时间,之后开始自动清理
wal 的大小依赖你导入的速度,和数据量没关系
当导入完成 4 小时后,就会去掉了。(还会保留 2 个 wal 文件,不过那个就很小了)
并行的,只要过了 4 小时候的 wal,就会被清理了。
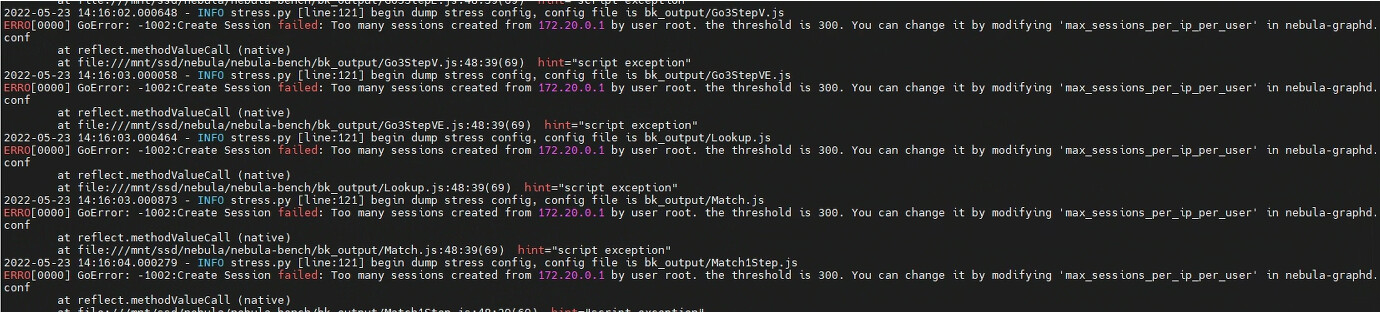
在用bench的测试过程中,当设置vu数量过多或者执行多次之后,会出现创建的sessions过多,好像需要修改一下这个阈值,这个应该在哪里修改
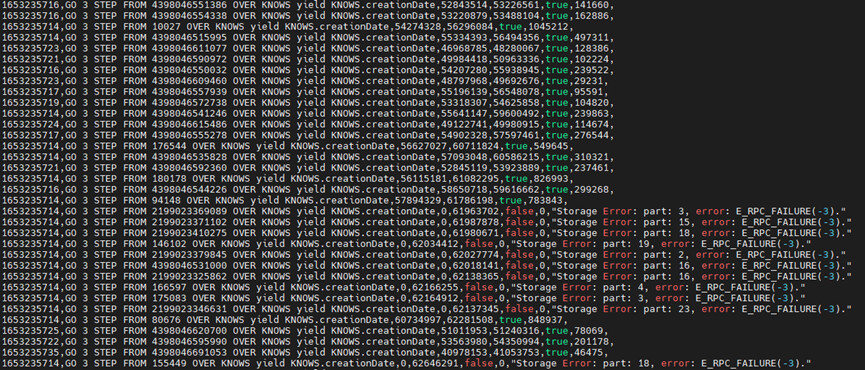
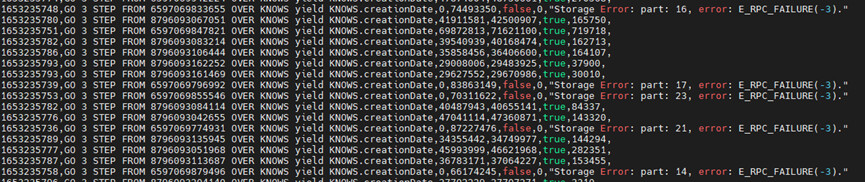
另外就是测试结果有个别会出现storage error的报错,这个是因为什么问题呢?
user22
2022 年5 月 23 日 07:31
10
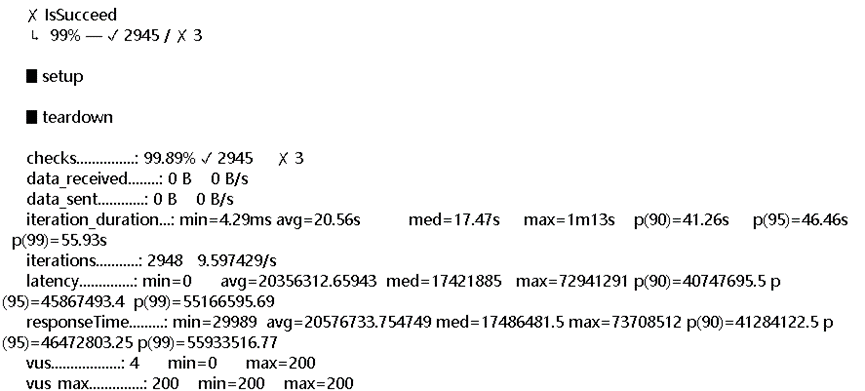
这边把相关的出现报错语句的测试报告和output返回的信息这边,基本上都是这个storage error的报错