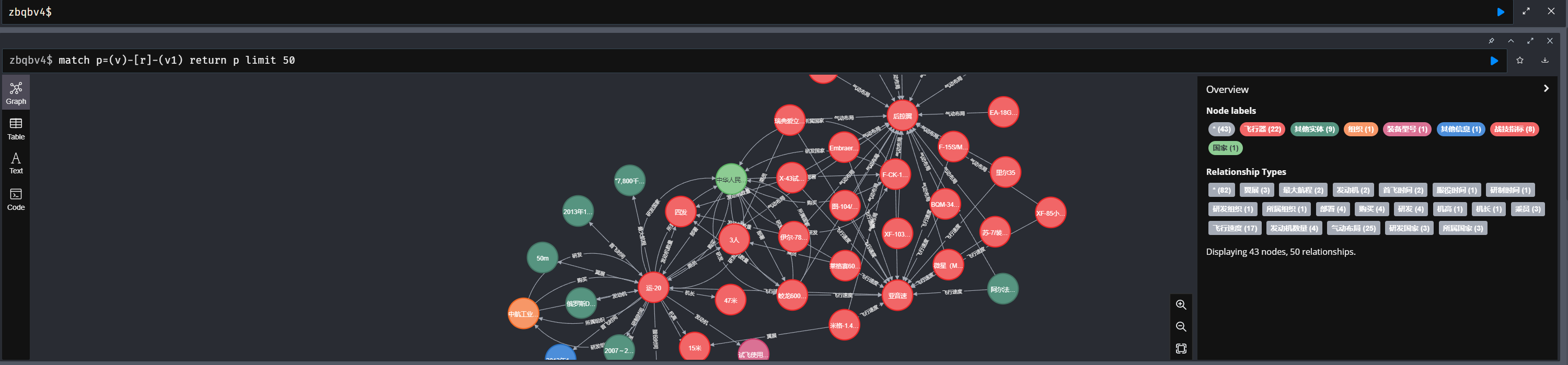
同一个space下面查询速度差别好大,300万数据节点无关系
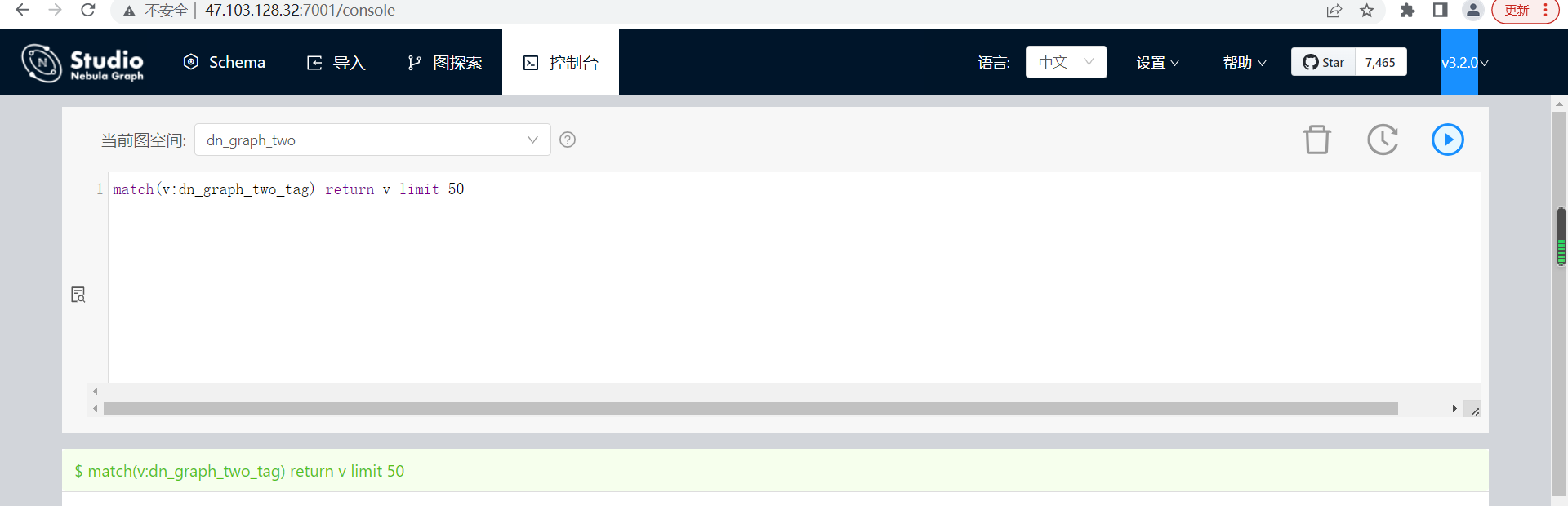
match(v:dn_graph_two_tag) return v limit 50 语句查询耗时10秒
match(v) return v limit 50 语句查询几百毫秒
nebula graph 目前的版本是3.0.0
服务器配置
gpu处理器 16G内存,500G数据盘docker-compose部署
同一个space下面查询速度差别好大,300万数据节点无关系
match(v:dn_graph_two_tag) return v limit 50 语句查询耗时10秒
match(v) return v limit 50 语句查询几百毫秒
nebula graph 目前的版本是3.0.0
服务器配置
gpu处理器 16G内存,500G数据盘docker-compose部署
我把你的问题从放置文章的博客捞出来放到【使用问题】下了,正如我说的那样,你试试用 console 来执行下这两个语句,看下速率差。
一模一样的query对比下呢?。。。
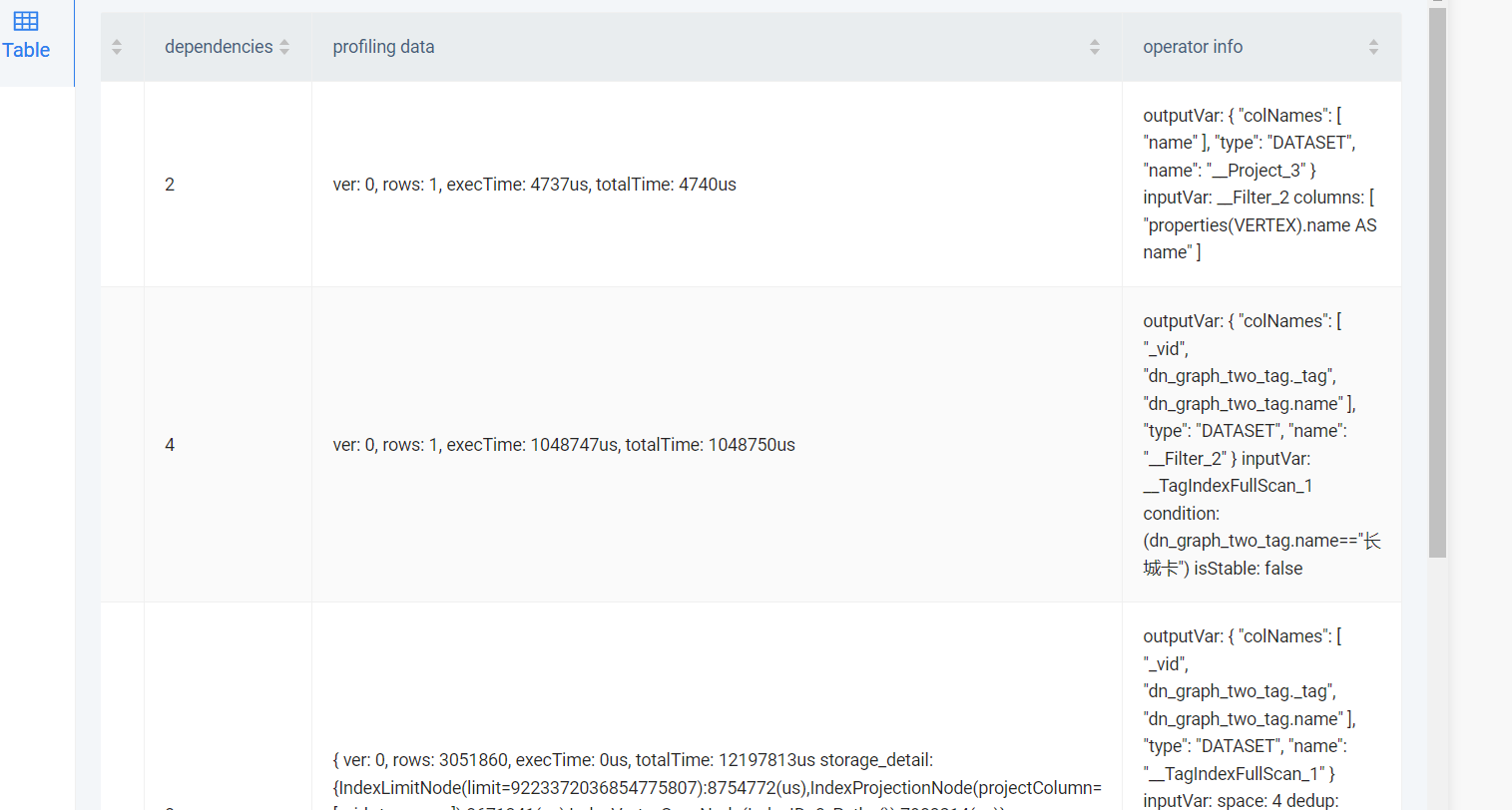
带上profile看看,没道理差那么大吧。。。。
neo4j对label是有索引加速的,单个特定文件。
nebula 默认不会有tag加速,所以limit50的时候,指定tag似乎会更麻烦。。。得去一堆文件挑。。。。
嗯嗯,这两个查询语句完全不一样,建议可以改成一样的试试。
查询语句加个 profile 看一眼执行计划。
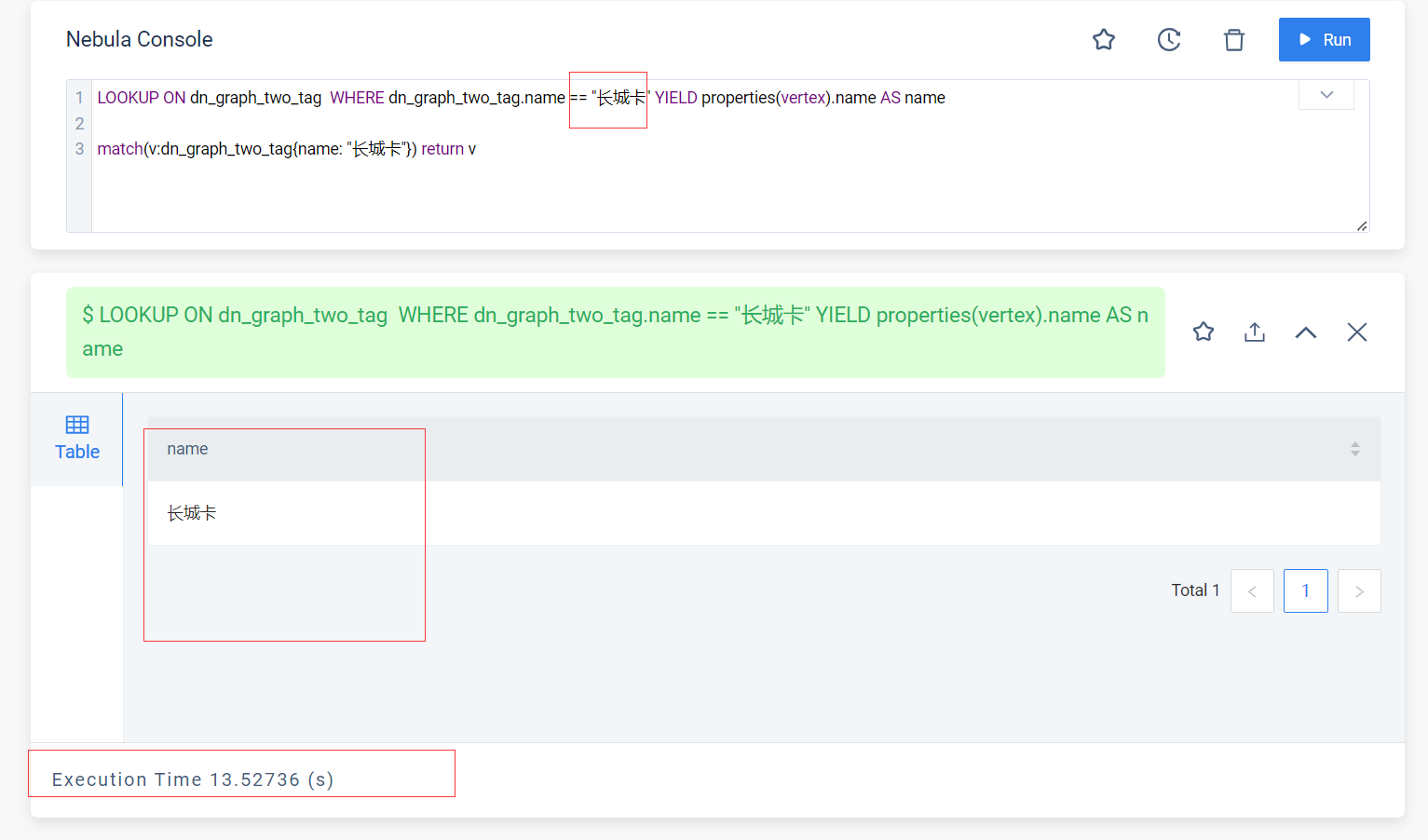
这个慢看起来是索引没有建立在 name 的单属性索引,或者name靠左的复合索引,只有别的索引,然后索引全扫描了,能show一下索引么?
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。