steam
2022 年5 月 27 日 08:44
4
= =。哥,我让你补充个配置啊,你给我监控图,我也算不出来你多少 CPU 核数啊
Ian
2022 年5 月 27 日 10:05
8
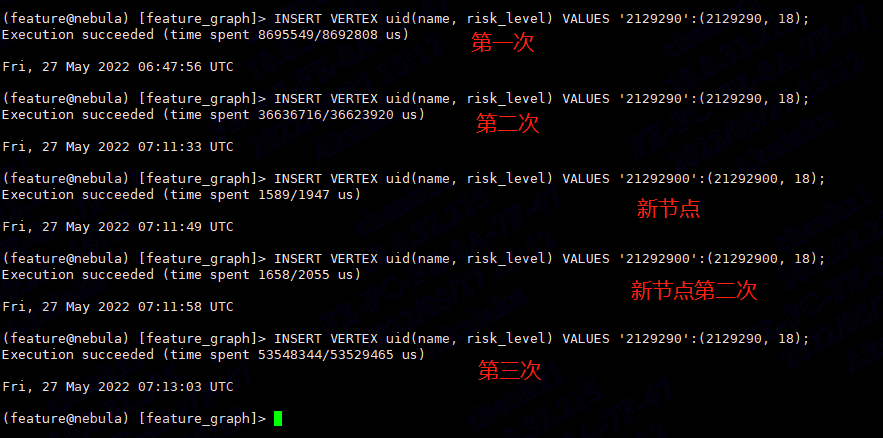
这个空间是新建的,只有我这个项目在使用,按照我的程序,只有判断uid是否存在这个查询:MATCH (v:uid {name:xxx}) RETURN v.uid.name AS name
Ian
2022 年5 月 27 日 10:13
9
Nebula 3.1.0还是不支持并发写入吗?
按你描述的 肯定是存在并发操作了。应该是在3.2版本把并发的限制放松了,允许并发update同一个kv了。然后你另一个RPC报错大概率是因为MATCH把insert挡住了。数据量大不建议用match。
Ian
2022 年5 月 30 日 02:07
12
因为什么原因数据量大不建议用match。
wey
2022 年6 月 1 日 02:25
14
MATCH 的优化现在还没有 LOOKUP/GO 多(在不断被优化中,很多场景已经是可比的表现了,但是还是有点差异原因如第二条)
MATCH 正常拓展时候取点带上所有属性,开销大一些
所以能用 LOOKUP/GO/FETCH 表达的模式匹配是比 MATCH 有更好的表现的哈。
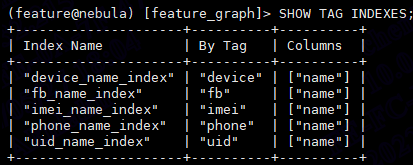
索引的建立一定是有写入开销的,如果能够通过 vid 格式设计避免起始点的基于索引的查询,会对写入有大大的帮助哈
ref: Nebula Graph 索引详解 - siwei.io
Ian
2022 年6 月 1 日 06:52
15
1、执行语句超时的问题通过观察storage日志,重启storage后,暂时没有问题;
另外有一个问题,关于session管理的问题:
system
2022 年7 月 1 日 06:53
16
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。