能稳定复现吗,直接attach进去看看  log里面,机器挂掉附近时间点的语句是什么,比如parsing xxx啥的
log里面,机器挂掉附近时间点的语句是什么,比如parsing xxx啥的
稳定复现可以做到 等virt 到240+ 自己就挂了。感觉就是虚拟内存不释放的问题。

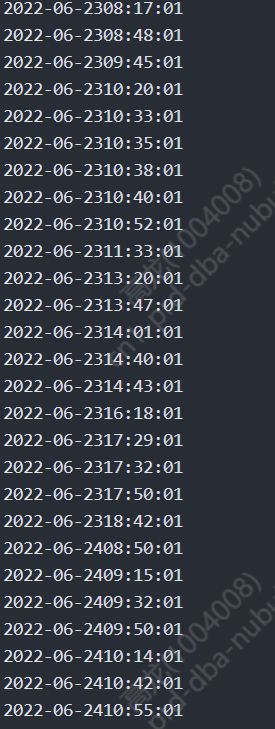
附近没有什么日志信息的,看过好几次了,感觉就是虚拟内存的增加引起的,这个是哪里可以调整控制吗
 别忘了我啊
别忘了我啊
这是一直在跑各种语句吗?
是的 就是按正常的线上应用再跑

 还搭理我吗
还搭理我吗
稍等片刻哈
关于最开始的问题,block cache降到了4M,是会显著降低性能的。按照工业界经验,可以将block cache设置成2/3内存大小。可否试验一下,将block cache设置成2/3内存大小后,是否出现上述core dump问题。
block cache 已经调整为100G,现在主要是nebula graph宕机。
240G附近,graphd和storage分别占用的virt和res是多少呢?



由于现在流量降低了,所以不太容易复现那种情况,目前三台服务器情况如上,给人的感觉就是nebula graph使用的内存一直在增长而没有释放的过程。有没有什么方案可以实现nebula graph内存释放
executor-pri3-4[162595]: segfault at 18 ip 0000000001067031 sp 00007f6885cf4060 error 4 in nebula-graphd[ece000+1754000] 这是系统的报错。内存越界,nebula-graph放到最大的日志记录,ERROR和WARRING也没有有用信息。INFO每次的信息都不一样。
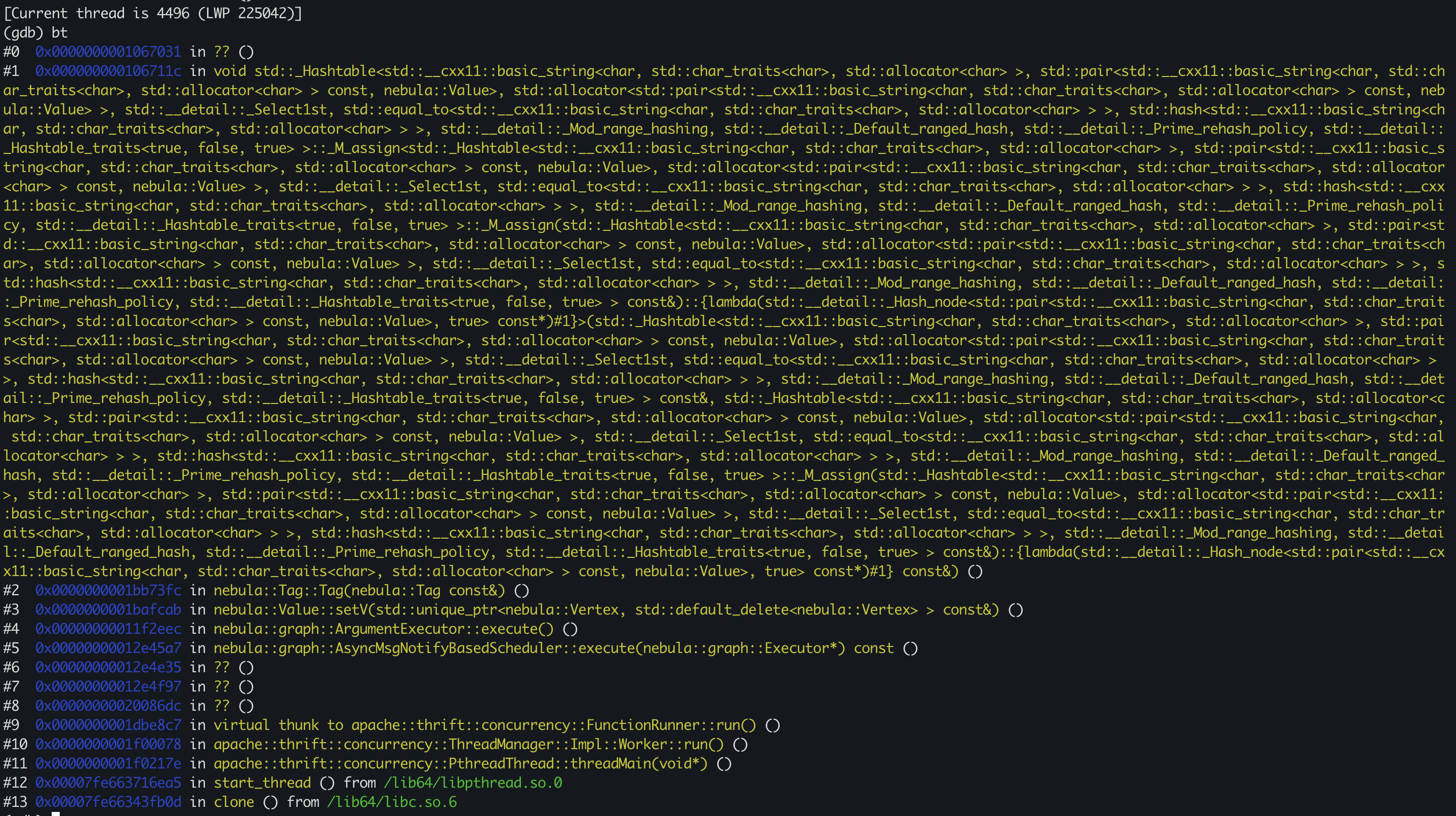
最好可以把 graph 挂掉的时候 执行的ngql语句发一下,看了@xjc 发的堆栈信息不是很完整
match (m:Ncdgrkh)-[r1:Rrz|Rfrdb|Rtz|Rsjkzr|Rlxr]->(gs:Ngs) where id(m) ==“Nzrr_34” with m, gs match pas=(gs:Ngs)<-[r1:Rrz|Rfrdb|Rtz|Rsjkzr|Rlxr]-(m:Ncdgrkh)-[r2:Rrz|Rfrdb|Rtz|Rsjkzr|Rlxr]-> (co:Ngs)<-[r3:Rrz|Rfrdb|Rtz|Rsjkzr|Rlxr]-(n:Nzrr)-[r4:Rrz|Rfrdb|Rtz|Rsjkzr|Rlxr]->(:Ngs)-[r5:Rrz|Rfrdb|Rtz|Rsjkzr|Rlxr]-(:Nzrr) where id(m)<>id(n) and r2.is_valid == “0” and r3.is_valid == “0” and r4.is_valid == “0” and r5.is_valid == “0” return pas,‘司’ as rule limit 30 我们这边抓了一下 ,这种语句跑时间长了就会导致graph挂掉,这个是需要修改语句吗,还是有别的解决方案
语句没问题,时间长了 graph 挂掉,能否确定一下当时的内存情况,是内存满了被系统挂掉 还是内存正常,graph挂掉了