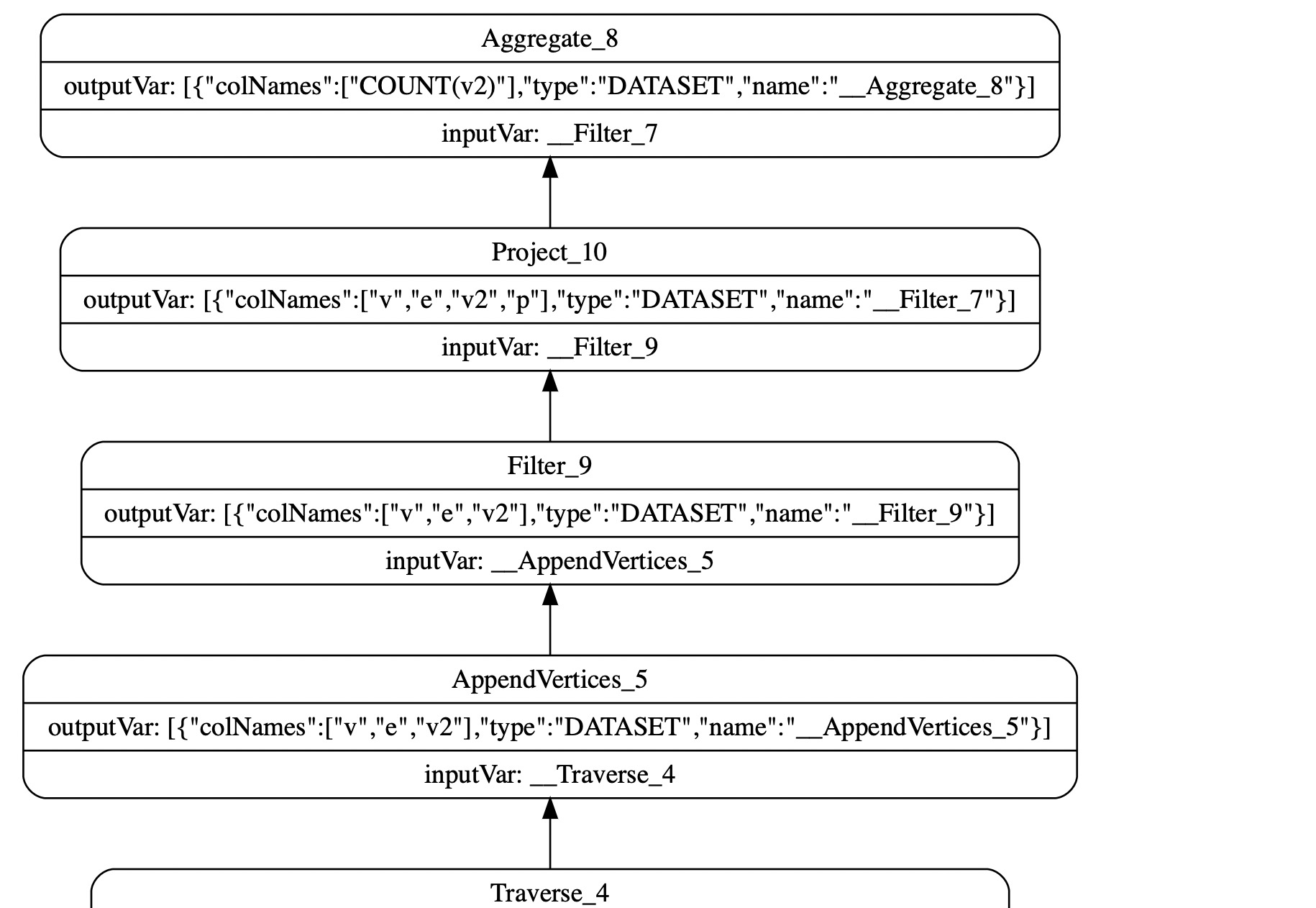
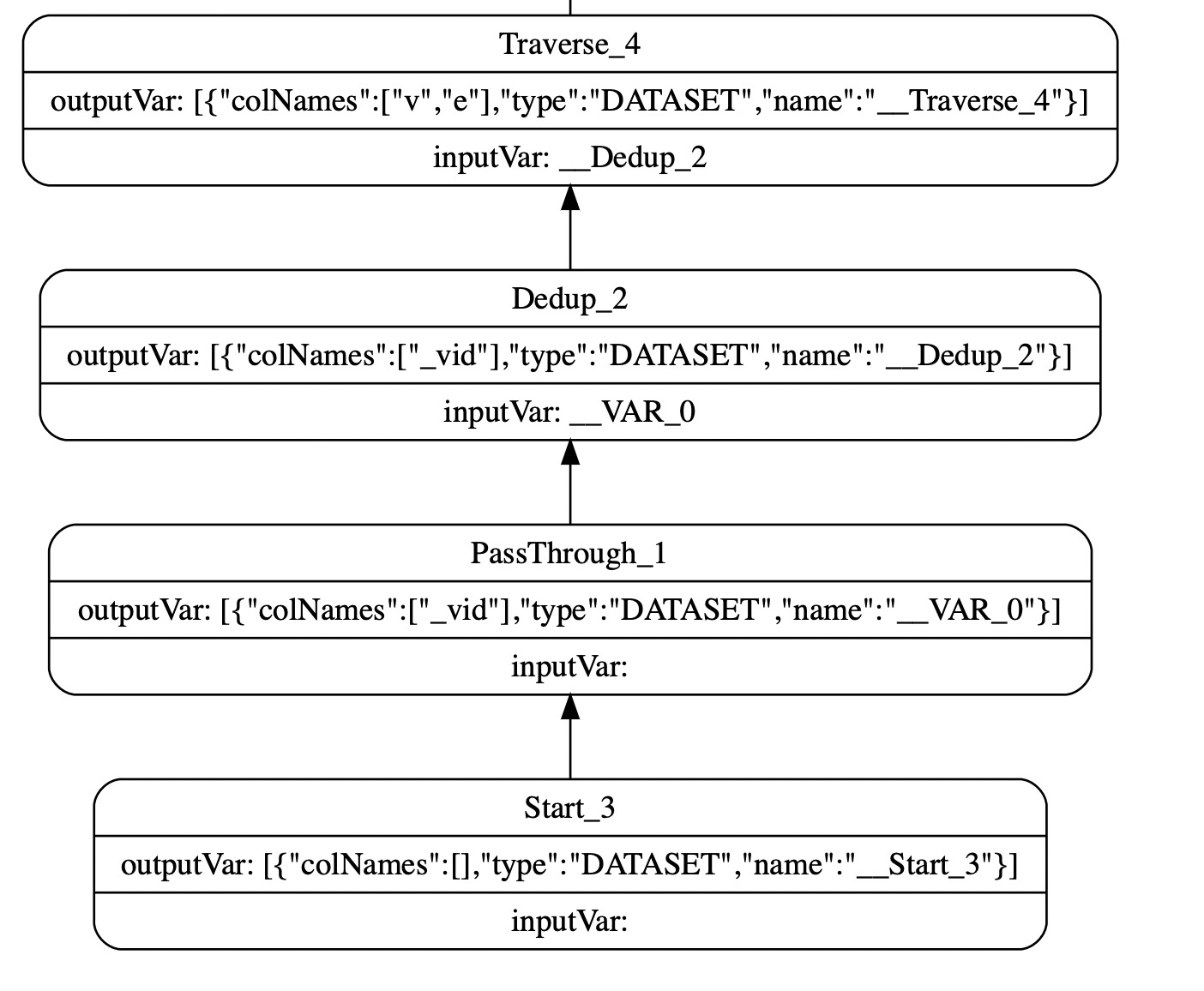
nebula 3.0.0 在做一个数据量比较大的查询的时候会graphd服务会挂掉,查询也无法顺利执行,查看日志发现报错内存不足,请问这样就是无法执行这个查询吗?有没有办法可以看到需要多少内存?
Memory usage has hit the high watermark of system, available: 3.99081e+08 vs. total: 1.34661e+11 in bytes.
W20220622 11:20:58.164331 38430 MemoryUtils.cpp:79] Memory usage has hit the high watermark of system, available: 3.63557e+08 vs. total: 1.34661e+11 in bytes.
W20220622 11:22:38.164403 38430 MemoryUtils.cpp:79] Memory usage has hit the high watermark of system, available: 3.73535e+08 vs. total: 1.34661e+11 in bytes.
W20220622 11:24:18.165807 38430 MemoryUtils.cpp:79] Memory usage has hit the high watermark of system, available: 4.02395e+08 vs. total: 1.34661e+11 in bytes.
W20220622 11:25:58.165757 38430 MemoryUtils.cpp:79] Memory usage has hit the high watermark of system, available: 3.6649e+08 vs. total: 1.34661e+11 in bytes.
W20220622 11:27:38.166309 38430 MemoryUtils.cpp:79] Memory usage has hit the high watermark of system, available: 3.63815e+08 vs. total: 1.34661e+11 in bytes.
W20220622 11:29:18.164100 38430 MemoryUtils.cpp:79] Memory usage has hit the high watermark of system, available: 4.0011e+08 vs. total: 1.34661e+11 in bytes.