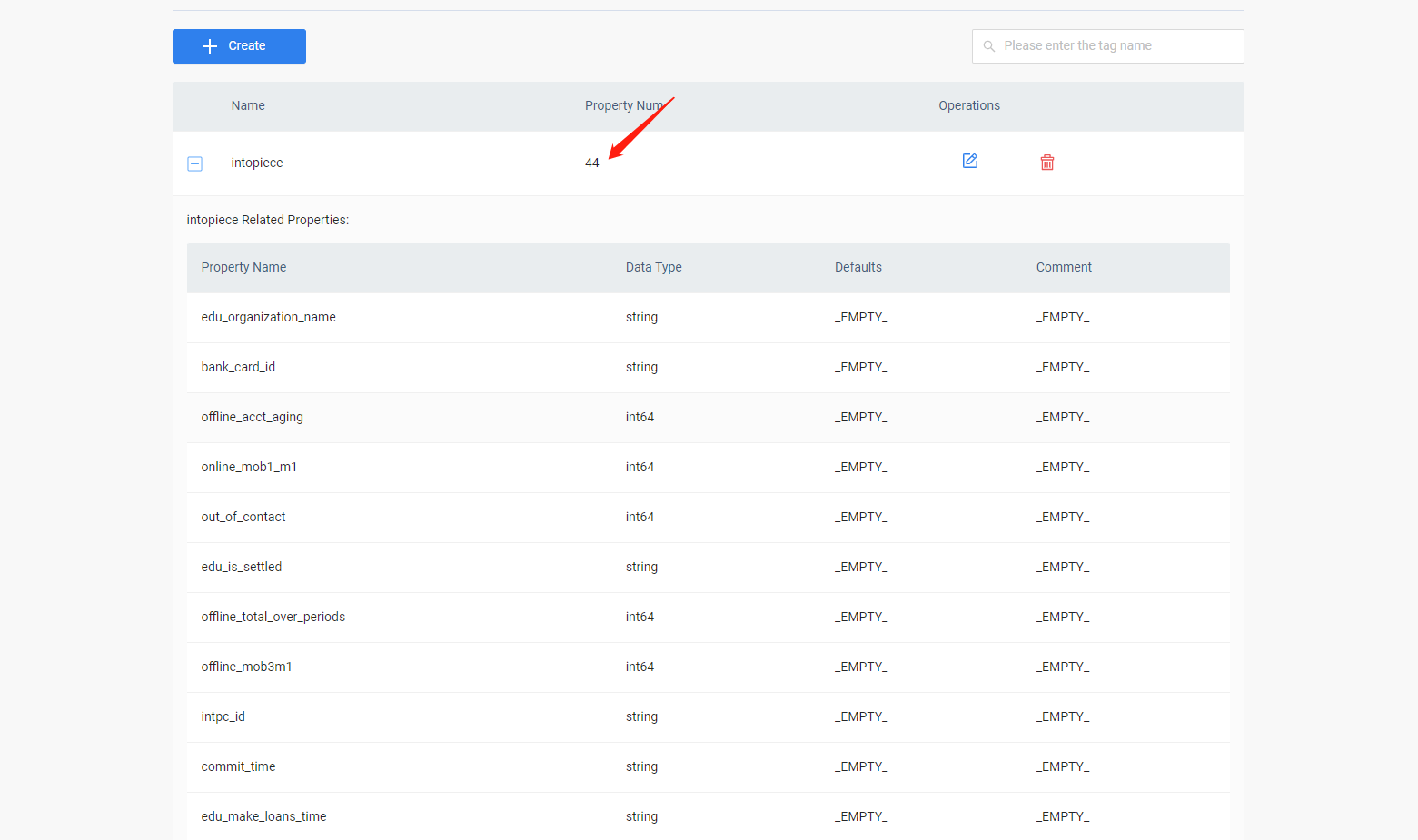
match (n:intopiece) where n.intopiece.loan_business_id ==‘A1440720220821037089’ return n;
使用了loan索引去查 1千W数据 跑了 Execution Time 0.091819 (s),感觉是有点慢啊,请问是怎么导致的呢
match (n:intopiece) where n.intopiece.loan_business_id ==‘A1440720220821037089’ return n;
使用了loan索引去查 1千W数据 跑了 Execution Time 0.091819 (s),感觉是有点慢啊,请问是怎么导致的呢
查到索引后, 还会回表读下原始数据.
可以在语句前面加个profile, 看看哪个算子慢了
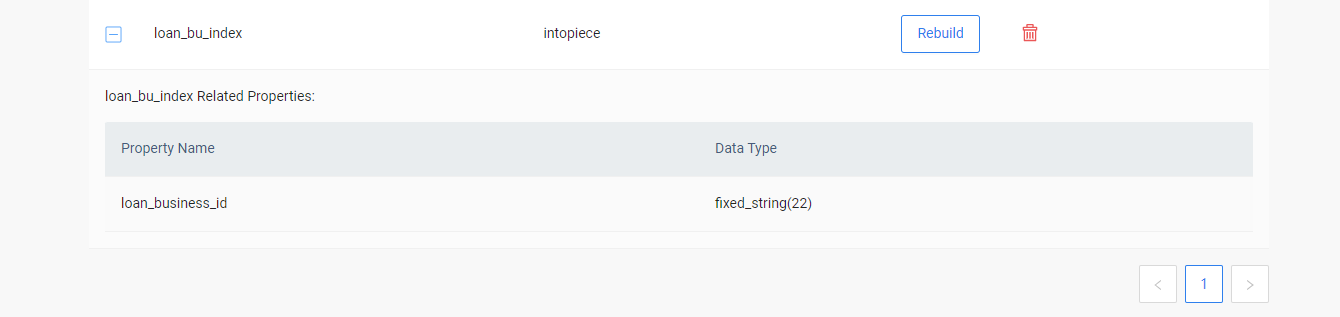
这个indexScan 就很慢,字面上看是索引扫描的慢,可是什么原因导致的慢呢?我的索引长度是22
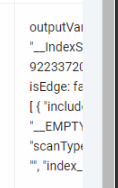
operator info这列可以截个完整的图吗
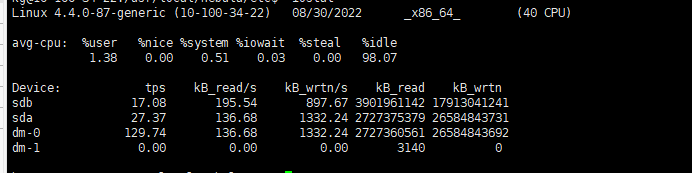
啥硬盘
HDD
emmmmm你这个我只能归结于数据量大然后HDD随机读性能太差。。。。或许你调整下rocksdb的参数会有一些性能提升。
rocksdb 这个我之前调整到了50G了已经
可以调整下每层sst文件的大小,减少sst文件数量
HDD 随机读 几十ms,合理吧。
建议 氪金
因为这个数据量在 neo4j上跑过,同样的cypher语句,neo4j不到1ms,2步子图 查询结果的情况下400ms以内完成,我在导入相同数据,索引什么的都一样的情况下,各项结果都慢,我想了解下,这问题能靠换SSD解决吗
sst 参数在哪里调啊 ,配置文件里没找到属性啊
新入库的数据?
我是把neo4j的全量数据导进的nebula,同样的索引,同样的机器配置
HDD上用1ms,这个不合理吧。当然可以进cache。
不过纠结这种点查询的语句没啥意义,换redis还能更快。
match (n:intopiece) where n.intopiece.loan_business_id ==‘A1440720220821037089’ return n;
另外,存储计算分离,storage->graph都要1ms