请问一下,a space的storage节点,下面存在存储文件data和wal,怎么安全的迁移到另外一个create space a as b出来的storage节点呢?
直接把data和wal文件移动过去,可能有哪些不兼容点呢?
考虑用 spark connector 的话可以这边读(绕过graphd扫storage)那边写导数据,不用 hack 底层这些
1 个赞
这步文档里没有看出来,我看配置读写其中包括的配置连接:withMetaAddress、withGraphAddress,并没有包括storage节点的地址,怎么绕过graph的呢?
meta 里维护了所有其他服务的列表哈,而且认为 storaged 是动态的,所以是实时从 meta 取 sotraged 的地址,按需去扫数据哈。
参考 https://www.siwei.io/nebula-algo-spark-k8s/
还有官方博客讲心跳机制的那一篇
1 个赞
好的,谢谢,我先学习一下
我看了一下这个的仓库
https://github.com/vesoft-inc/nebula-spark-connector
发现速度上写入1亿带属性的点需要10分钟左右
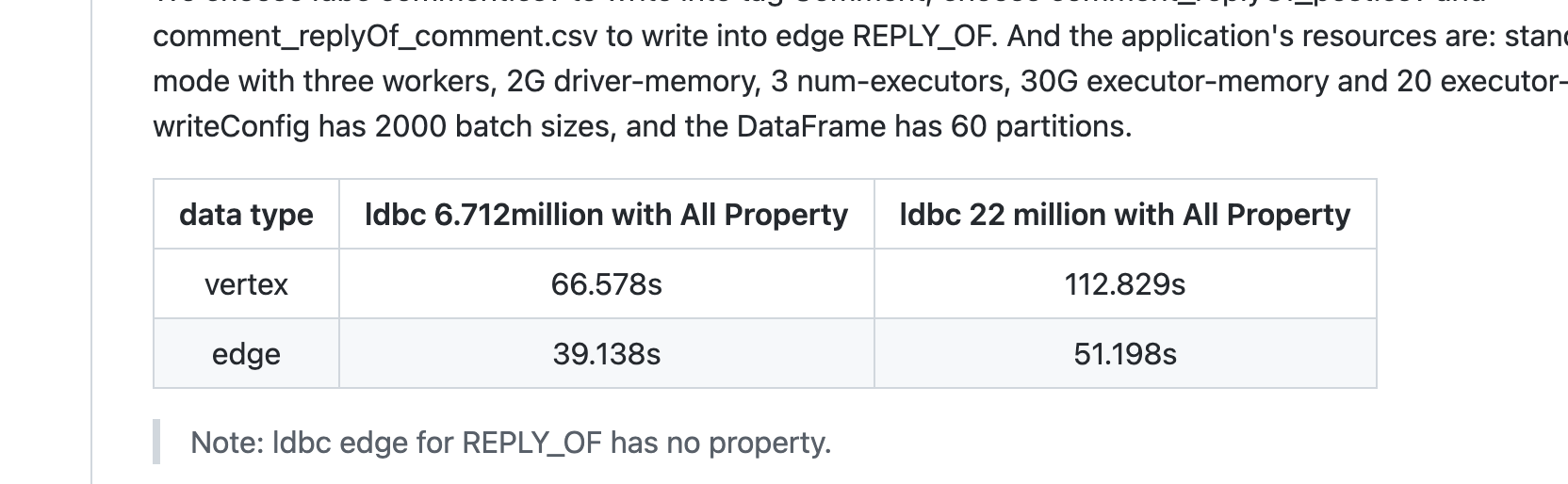
我们现在其中的一个场景
机器部署和数据情况
5台机器5个storage节点,3副本,整体数据200亿
平均到一台机器的数据量:200亿 * 3副本 / 5台机器 = 120亿单机
需求背景
现在想每日做全量数据导入:在另外一个集群做ingest,然后把对应storage节点的数据通过spark-connector导入线上集群节点
方案耗时
根据场景数据计算120亿 / 1亿 * 10 分钟 / 60分钟 = 20h,大概单节点需要20h
不确定是不是计算的有些问题,感觉耗时高,我这个场景不太适合使用spark-connector
看看这个 利用 snapshot 进行集群迁移
另外写入速度其实和硬件还有调优相关,可以实验看看。
再有,如果是企业版 exchange 的话,支持 nebula集群间的导入导出 @nicole 企业版可以 nebula server 读,file(sst) sink 么?文档里看好像只是支持 CSV sink 
1 个赞
企业版只可以从nebula中导出csv。
1 个赞
收到🫡