nebula 版本: 3.2.0
部署方式:分布式
安装方式:源码编译
是否为线上版本:Y
硬件信息
磁盘 1TSSD
CPU、内存信息 40C240G
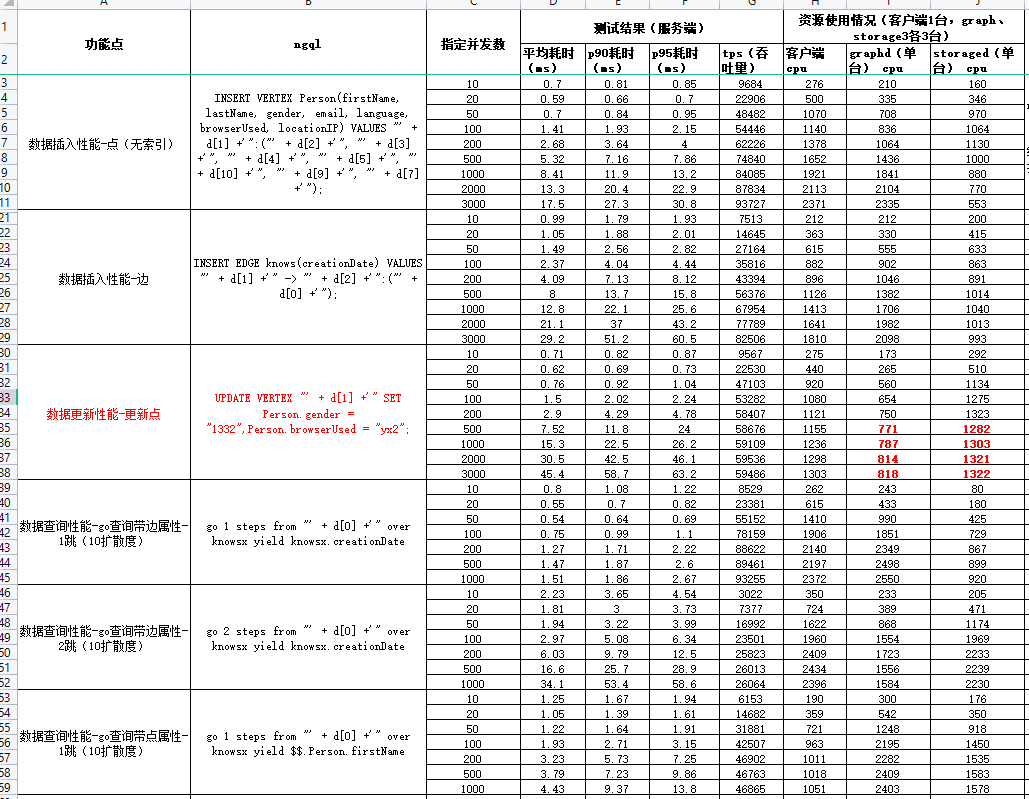
最近在做性能测试,搞了四台物理机,1Tssd 每台40c,有三台用来部署集群(每一台都一个meta、storage、graph服务),有一台放了k6用来发起压测,用来测试插入、更新、查询的性能。
可以看到:可以看到update我已经压到瓶颈了,加大并发也上不去了,但是它到瓶颈的时候graph+storage加起来才使用了20C ,距离容量还差20c没有用,而且他的tps比insert要小很多,磁盘io我感觉也不会到瓶颈
我想咨询下,这个update的瓶颈点是在哪里,为什么会有这样的现象?
update 比 insert 多了一次磁盘读,读取已经存在的数据。
你是按顺序压测的么?insert 后,有没有做 compact,或者有没有开启自动 compact?
1 个赞
我没有手动做compact,自动compact是有的。
嗯,你 block_cache 设置了多大,然后整个数据大概多大。
从你的数据上看,update 并发小的时候还好,但是 storage 的 cpu 使用比 insert 高,而并发大的时候,storage cpu 比 insert 高很多了,比如 2000 并发。
你可以在压测 update 的时候,perf 看一下 storage。
1 个赞
我看缓存的配置是
# The default block cache size used in BlockBasedTable.
# The unit is MB.
--rocksdb_block_cache=4
这个一个block_cache是4mb这么小的吗,一共有多少个blcok?
感谢楼主的测试,很赞!
除了 CPU 和 I/O 可能会饱和,内存访问也可能饱和,从而成为性能瓶颈。内存的最大带宽是受到 CPU 的访存指令发射能力、操作系统或者数据库的内存管理相关的开销(比如虚拟地址到物理地址的转换,页表缓存大小等等)、内存控制器、内存通道的数量等等等等因素控制的。在数据库实际运行过程中,访问数据的模式(随机还是跳跃还是顺序),软件、硬件预取的效果,访问数据在内存中的分布等等,都会决定实际的内存带宽利用率和内存访问延迟。在比较大的有多个 CPU socket 的机型中,一个 socket 上的线程访问另外一个socket连接的内存会比访问本地内存慢大概 30% 以上,也就是所谓的 NUMA 现象。可以使用 numactl -H 命令来查看您机器的 NUMA 配置。
总之内存访问上的潜在的瓶颈点是很多的。可以尝试用 perf 或者 vtune 等工具来 profile 一下内存(还有 cache)相关的 hardware counter,会获得更清晰的开销 breakdown。
内存中存储数据的数据结构有很多种,他们的设计也会极大的影响内存访问的性能。以 NebulaGraph 在存储层使用的 RocksDB 为例,它除了实现了不同种类的 cache 以外,内存中的 memtable 也会存储刚刚插入的数据,也可以服务查询。
一般来讲可以通过敏感性测试,在不做特别细粒度 profiling 的情况下,了解系统各方面开销的分布。比如说可以往数据库中加载入很大的数据集,比如 1TB,然后尝试控制查询数据的分布,如果分布越倾斜,那么热点越集中,查询越有可能命中内存,性能会较 I/O 密集型的场景好很多;反之,查询会更多的访问 I/O,性能会更差。
也可以做一些跟数据量相关的敏感性测试,比如导入 10GB、100GB、500GB、1TB的数据,对比它们的导入速度、执行时间等等。像 RocksDB 这样的底层存储引擎,在持续写入时间比较长,数据量比较大的情况下,后台会触发许多 compaction 操作,消耗比较多的 CPU 和 I/O 资源,从监控上可以看到相应的资源曲线的变化。
您所做的变更并发数量的测试也是一种敏感度测试。
如何优化多线程并发下内存这部分的性能是一个很经典的课题,常见的优化方法有使用无锁的内存数据结构、减少相关算法对线程间同步的需求、对数据进行分区、使用向量化的查询处理等等等等。目前 NebulaGraph 正在针对相关内容进行深入优化,未来可以支持更多的并发,获得更好的扩展性。
2 个赞
system
2022 年10 月 6 日 02:22
8
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。