nebula 版本:v3.2.0
部署方式:分布式
安装方式: RPM
是否为线上版本:Y
spark 版本:2.4.3
python 版本:3.7
nebula_spark_connector 版本:3.0.0

1 个赞
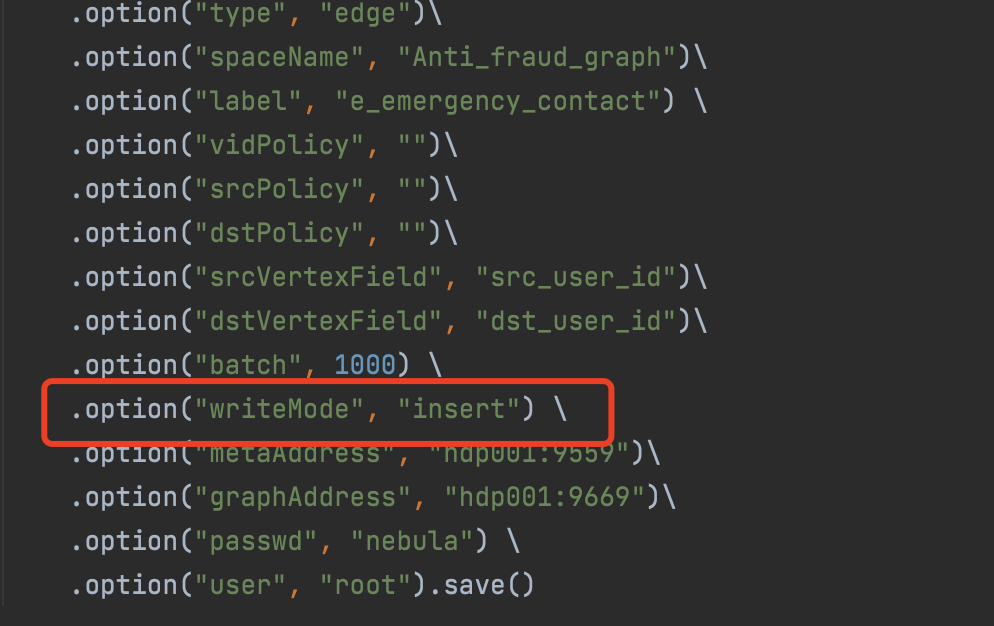

- 少个
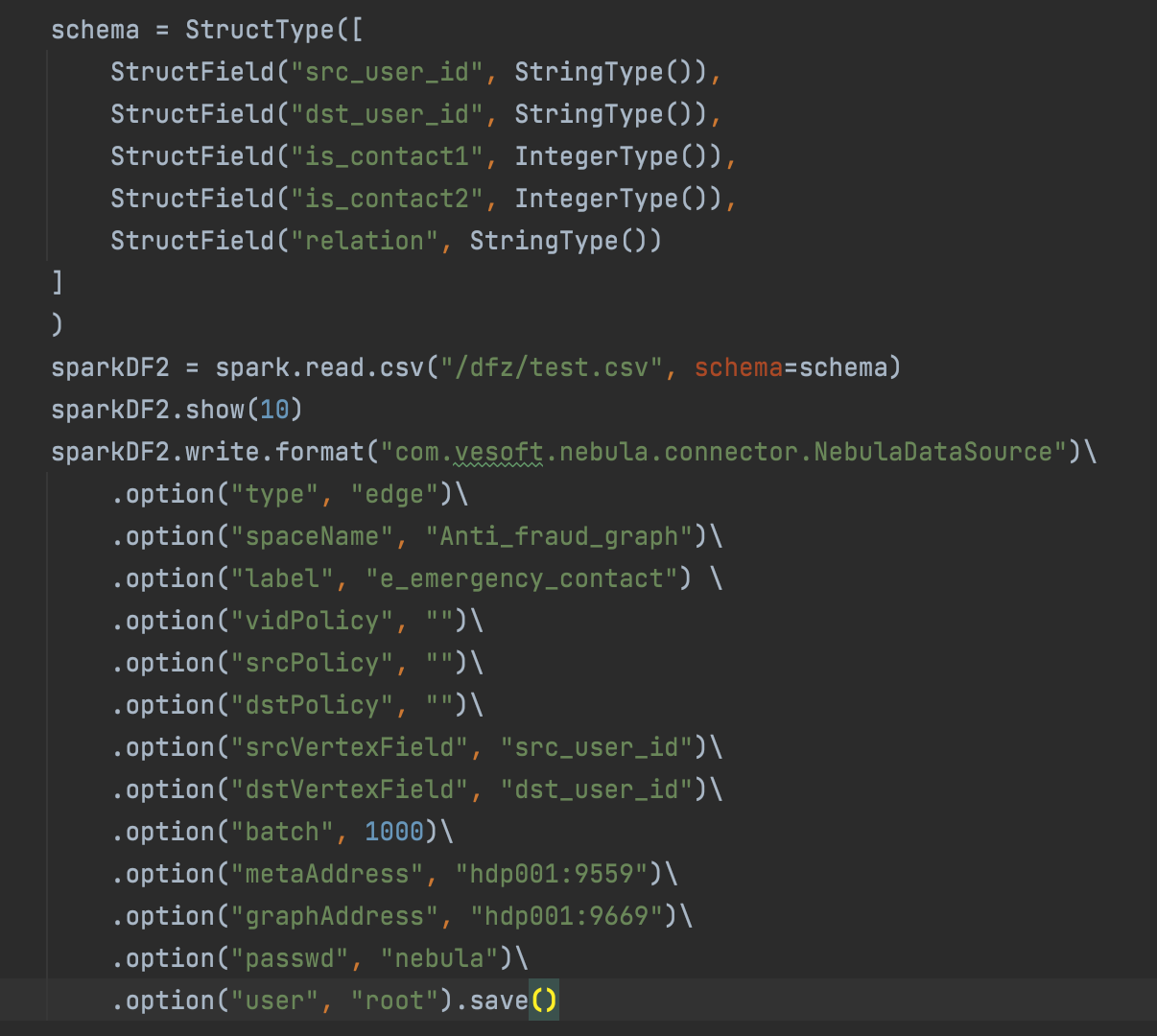
.option("rankFiled", "")\对于边而言rankFeild 是必填的,没有的话保持空字符串。 - 对于edge 而言应该是没有vidPolicy 字段的,这个你写了 可能会报错吧
3 个赞
感谢,这里还有一个错字,我提 pr 了,回头合并之后注意一下变化哈
Opps, 这里之前我还没发现,这次只发现了 rankfiled/rankfield。
要不要来水一个 pr ?
1 个赞
ok 我稍后提一个,我还真没注意rankdField 拼错了,一直是复制.
1 个赞
词序不影响人脑理解 
1 个赞
请问这边方便提供一个pySpark写入边成功的demo吗,我想参考一下
df.write.format("com.vesoft.nebula.connector.NebulaDataSource")\
.mode("overwrite")\
.option("timeout", 300000)\
.option("connectionRetry", 1)\
.option("executionRetry", 2)\
.option("srcPolicy", "")\
.option("dstPolicy", "")\
.option("metaAddress", metaHost[cluster])\
.option("graphAddress", graphHost[cluster])\
.option("user", "root")\
.option("passwd", "nebula")\
.option("type", "edge")\
.option("spaceName", "Relation")\
.option("label", "rel")\
.option("srcVertexField", "srcid")\
.option("dstVertexField", "dstid")\
.option("rankFiled", "")\
.option("batch", 3000)\
.option("writeMode", "insert").save()
我提个pr 加上个py example 吧 @wey
2 个赞
麻烦提一个吧!在 readme 上,加上 doc effect,如果可以再去 docs-cn repo 也提一个  ,现在都是只有点写入
,现在都是只有点写入
1 个赞
是的,我用的也是这个版本,我的nebula 是v3.2.0 看readme 是都兼容的。
你检查下 你的数据有没有null 值
你的Dataframe schema 和 edge 的schema 相同吗
没看出来哪里不对
不好意思哈,这边犯了低级错误导致的,您这边提供的方法是对的,问题已经解决了,谢谢帮助