neo4j
2022 年9 月 28 日 05:43
1
目前在使用exchange的2.0版本,使用的spark2.4的模块进行导数据,发现在导一个边200亿数据的时候速度比较慢。
分析发现主要集中在这个代码的140行https://github.com/vesoft-inc/nebula-exchange/blob/master/nebula-exchange_spark_2.4/src/main/scala/com/vesoft/nebula/exchange/processor/EdgeProcessor.scala https://github.com/vesoft-inc/nebula-exchange/blob/master/exchange-common/src/main/scala/com/vesoft/exchange/common/writer/FileBaseWriter.scala的63行
def writeSstFiles(iterator: Iterator[Row],
fileBaseConfig: FileBaseSinkConfigEntry,
partitionNum: Int,
namenode: String,
batchFailure: LongAccumulator): Unit = {
val taskID = TaskContext.get().taskAttemptId()
var writer: NebulaSSTWriter = null
var currentPart = -1
val localPath = fileBaseConfig.localPath
val remotePath = fileBaseConfig.remotePath
try {
iterator.foreach { vertex =>
val key = vertex.getAs[Array[Byte]](0)
val value = vertex.getAs[Array[Byte]](1)
var part = ByteBuffer
.wrap(key, 0, 4)
.order(ByteOrder.nativeOrder)
.getInt >> 8
if (part <= 0) {
part = part + partitionNum
}
if (part != currentPart) {
if (writer != null) {
writer.close()
val localFile = s"$localPath/$currentPart-$taskID.sst"
HDFSUtils.upload(localFile,
s"$remotePath/${currentPart}/$currentPart-$taskID.sst",
namenode)
Files.delete(Paths.get(localFile))
}
currentPart = part
val tmp = s"$localPath/$currentPart-$taskID.sst"
writer = new NebulaSSTWriter(tmp)
writer.prepare()
}
writer.write(key, value)
}
} catch {
case e: Throwable => {
LOG.error("sst file write error,", e)
batchFailure.add(1)
}
} finally {
if (writer != null) {
writer.close()
val localFile = s"$localPath/$currentPart-$taskID.sst"
HDFSUtils.upload(localFile,
s"$remotePath/${currentPart}/$currentPart-$taskID.sst",
namenode)
Files.delete(Paths.get(localFile))
}
}
}
第一次执行foreach用了1个小时 左右,观察的日志执行是
后续foreach执行写sst逻辑,我在foreach内部外部都加上了耗时统计内部foreach :所有的foreach单次耗时之和(单次结束时间-单次开始时间=605秒Array[Byte] 外部foreach :结束时间-开始时间=4327秒
(1)第一次执行foreach为什么会耗时一个小时才开始执行?
现场情况
所以executor的堆内堆外内存,设置多大,有没有最佳实践
是的,整个生成sst 比较耗时的部分一个是去重,一个是排序。
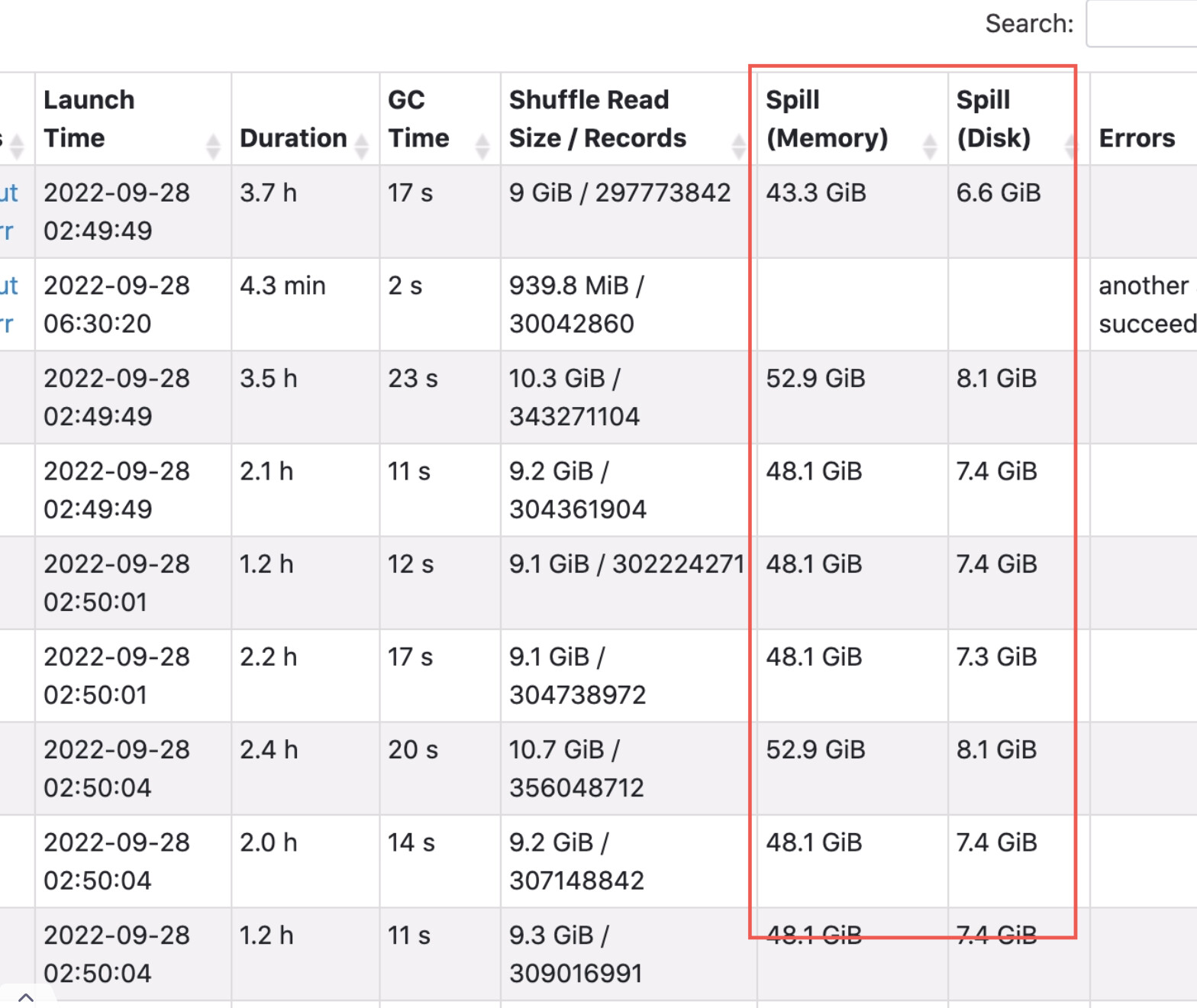
图中看到的shuffle read是foreach前进行的distinct和order中的过程,foreach是action操作,会触发前面所有的transform操作,所以第一次foreach时会耗时很久。 foreach内部没有远程读数据的操作,但在去重时由于该操作是shuffle操作 所以会有executor的写和读的过程。
3 个赞
neo4j
2022 年9 月 29 日 04:14
3
对于spark普通任务来说这种大数据的任务可以拆分成小task来执行。
opened 01:26PM - 29 Jul 21 UTC
closed 05:52AM - 23 Aug 22 UTC
feature req
总结:这种writesst的逻辑,因为需要有序的写单个sst文件,导致无法拆分小的task执行,使spark无法提高并行度,所以对大数据量的task无法起到性能提升作用,从而成为性能瓶颈,这种情况下怎么解决呢?
你可以不用repartitionWithNebula这个配置,最后写sst文件的并发数就是你所配置的shuffle partitions的值。 但这样会生成很多个sst文件,写文件性能上去了,但后面还有download和ingest的操作,这两个操作会因为sst文件数多而速度慢。
1 个赞
neo4j
2022 年10 月 9 日 02:31
5
目前测试不加repartitionWithNebula存在丢数据的问题
是的,这是个已知问题,后面要发的版本没有这个问题了
neo4j
2022 年10 月 9 日 09:18
7
nicole:
知问题,后面要发的版本没有这个问题了
大佬有fix这个问题的链接吗,我学习一下更改的版本是多少,我这边拉的代码可能还没更新
neo4j
2022 年10 月 10 日 02:41
9
这个链接的改动我看是取消了https://github.com/vesoft-inc/nebula-exchange/pull/63 新增的代码
可以帮忙解释一下为什么需要增加orphanVertexKey,增加后为什么会丢数据以及取消这个key后为什么不影响sst的生成吗?感谢
1 个赞
nicole
2022 年10 月 10 日 05:52
10
增加和取消 orphanVertexKey 是为了与图数据的数据存储保持同步
vesoft-inc:master ← cangfengzhs:add_vertex_key
opened 04:04AM - 18 Nov 21 UTC
check vertex key in fetch
#### What type of PR is this?
- [ ] bug
- [x] fea… ture
- [ ] enhancement
#### What does this PR do?
part of support vertex without tag
#### Which issue(s)/PR(s) this PR relates to?
https://github.com/vesoft-inc/nebula/issues/3123
Close https://github.com/vesoft-inc/nebula/issues/2725
#### Special notes for your reviewer, ex. impact of this fix, etc:
There are two remaining issues
1. Fetch returns `EMPTY`. At first I wanted to change it to return `NULL`, but I found that graph would change the execution flow based on the result returned by storage. If storage returns `EMPTY`, graph will think that the corresponding property has not been obtained, and will make a request again in the subsequent execution process; if storage returns `NULL`, graph will think that the value of the property has been obtained, which is `NULL`.
If it is acceptable to return to EMPTY, there is no need to make changes. Otherwise I need some help from someone who is familiar with graph service.
2. The issue of consistency between vertex and tag. For example, suppose there is a vertex and two tags, v1(t1,t2).`Update v1(t1)` and `Delete v1` are executed concurrently in any order, the final result should be that v1 does not exist (of course, t1, t2 also does not exist), but in the current scheme, the data may be v1(t1) after the execution is completed.
In the original design, we considered using locks to maintain consistency, but because the implementation of locks is more complicated, and other people have proposed a simpler solution, we did not adopt the lock solution. But at present, there is still a situation of breaking consistency without using a lock. This problem will be fixed in the future.
#### Additional context:
#### Checklist:
- [x] Documentation affected (Please add the label if documentation needs to be modified.)
- [ ] Incompatible (If it is incompatible, please describe it and add corresponding label.)
- [ ] Need to cherry-pick (If need to cherry-pick to some branches, please label the destination version(s).)
- [ ] Performance impacted: Consumes more CPU/Memory
#### Release notes:
Please confirm whether to reflect in release notes and how to describe:
> `
fix tagless by nevermore3 · Pull Request #4652 · vesoft-inc/nebula · GitHub
增加后丢数据是因为重分区后在同一分区内部数据写入时key被覆盖 Whether to forcibly enable repartitioning when the number of nebula space partitions is greater than 1 · Issue #71 · vesoft-inc/nebula-exchange · GitHub
2 个赞
system
2022 年10 月 17 日 05:52
11
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。