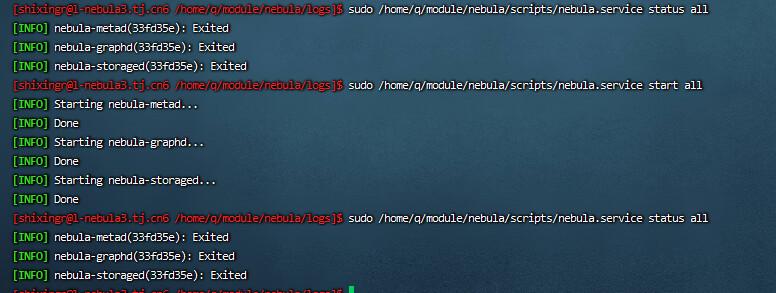
[shixingr@l-nebula1.tj.cn6 /home/q/module/nebula/logs]$ cat nebula-metad.ERROR
Log file created at: 2022/09/29 21:22:59
Running on machine: l-nebula1.tj.cn6
Running duration (h:mm:ss): 0:00:00
Log line format: [IWEF]yyyymmdd hh:mm:ss.uuuuuu threadid file:line] msg
E20220929 21:22:59.933522 43178 MetaDaemon.cpp:129] 10.66.140.34 is not a valid ip in current host, candidates: 10.66.140.41,127.0.0.1
[shixingr@l-nebula1.tj.cn6 /home/q/module/nebula/logs]$ cat nebula-storaged.ERROR
Log file created at: 2022/09/29 21:22:59
Running on machine: l-nebula1.tj.cn6
Running duration (h:mm:ss): 0:00:00
Log line format: [IWEF]yyyymmdd hh:mm:ss.uuuuuu threadid file:line] msg
E20220929 21:22:59.994889 43198 StorageDaemon.cpp:123] 10.66.140.34 is not a valid ip in current host, candidates: 10.66.140.41,127.0.0.1
[shixingr@l-nebula1.tj.cn6 /home/q/module/nebula/logs]$ cat nebula-graphd.ERROR
Log file created at: 2022/09/29 21:22:59
Running on machine: l-nebula1.tj.cn6
Running duration (h:mm:ss): 0:00:00
Log line format: [IWEF]yyyymmdd hh:mm:ss.uuuuuu threadid file:line] msg
E20220929 21:22:59.963265 43188 GraphDaemon.cpp:110] 10.66.140.34 is not a valid ip in current host, candidates: 10.66.140.41,127.0.0.1
########## basics ##########
# Whether to run as a daemon process
--daemonize=true
# The file to host the process id
--pid_file=pids/nebula-metad.pid
########## logging ##########
# The directory to host logging files
--log_dir=logs
# Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=0
# Verbose log level, 1, 2, 3, 4, the higher of the level, the more verbose of the logging
--v=0
# Maximum seconds to buffer the log messages
--logbufsecs=0
# Whether to redirect stdout and stderr to separate output files
--redirect_stdout=true
# Destination filename of stdout and stderr, which will also reside in log_dir.
--stdout_log_file=metad-stdout.log
--stderr_log_file=metad-stderr.log
# Copy log messages at or above this level to stderr in addition to logfiles. The numbers of severity levels INFO, WARNING, ERROR, and FATAL are 0, 1, 2, and 3, respectively.
--stderrthreshold=2
# wether logging files' name contain time stamp, If Using logrotate to rotate logging files, than should set it to true.
--timestamp_in_logfile_name=true
########## networking ##########
# Comma separated Meta Server addresses
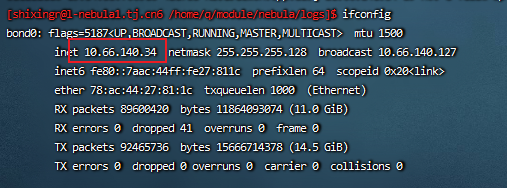
--meta_server_addrs=10.66.140.34:9559,10.66.140.39:9559
# Local IP used to identify the nebula-metad process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=10.66.140.34
# Meta daemon listening port
--port=9559
# HTTP service ip
--ws_ip=0.0.0.0
# HTTP service port
--ws_http_port=19559
# Port to listen on Storage with HTTP protocol, it corresponds to ws_http_port in storage's configuration file
--ws_storage_http_port=19779
########## storage ##########
# Root data path, here should be only single path for metad
--data_path=data/meta
########## Misc #########
# The default number of parts when a space is created
--default_parts_num=100
# The default replica factor when a space is created
--default_replica_factor=1
--heartbeat_interval_secs=10
--agent_heartbeat_interval_secs=60
[shixingr@l-nebula1.tj.cn6 /home/q/module/nebula]$ cat logs/nebula-metad.ERROR
Log file created at: 2022/09/30 18:59:58
Running on machine: l-nebula1.tj.cn6
Running duration (h:mm:ss): 0:00:00
Log line format: [IWEF]yyyymmdd hh:mm:ss.uuuuuu threadid file:line] msg
E20220930 18:59:58.606060 115728 MetaDaemon.cpp:129] 10.66.140.34 is not a valid ip in current host, candidates: 192.163.16.64,192.160.0.0,127.0.0.1,10.66.140.41