提问参考模版:
- nebula 版本:v2.6.1
- 部署方式:分布式
- 安装方式:RPM
- 是否为线上版本:Y
我用pyspark spark-connector 读取数据,
spark = SparkSession.builder\
.config("spark.jars", "path/nebula-spark-connector-2.6.1.jar")\
.config("hive.metastore.uris", "thrift://**:9083")\
.enableHiveSupport()\
.appName("nebula-connector").getOrCreate()
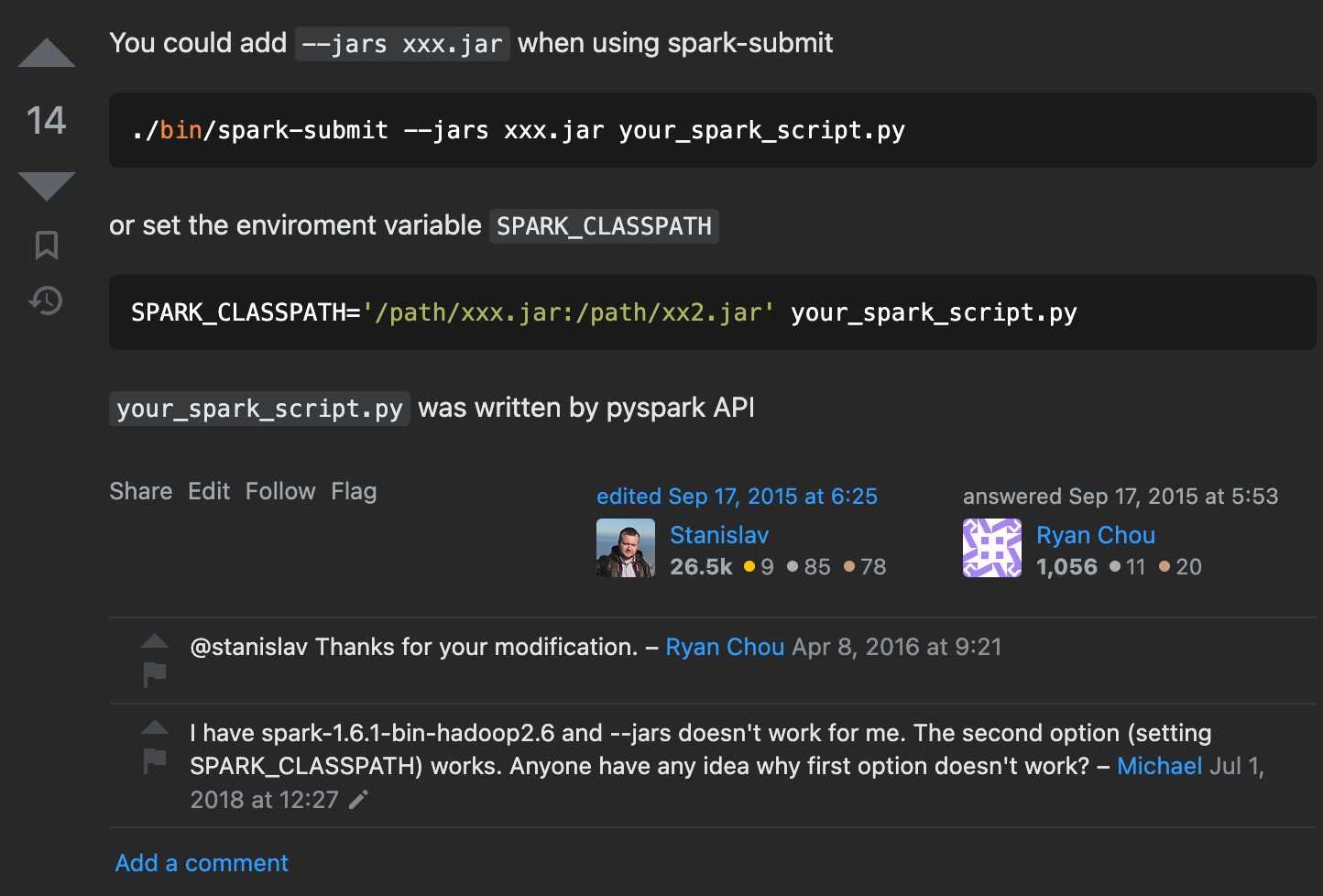
如果spark.jars 写在sparkconf 里面,会报错
Traceback (most recent call last):
File "nebula_relation_writer.py", line 172, in <module>
writeEdge(spark, tag, cluster)
File "nebula_relation_writer.py", line 128, in writeEdge
.option("writeMode", "insert").save() # delete to delete edge, update to update edge
File "/data/yarn/nm/usercache/zhangbl/appcache/application_1657030920107_2794761/container_e37_1657030920107_2794761_02_000001/pyspark.zip/pyspark/sql/readwriter.py", line 734, in save
File "/data/yarn/nm/usercache/zhangbl/appcache/application_1657030920107_2794761/container_e37_1657030920107_2794761_02_000001/py4j-0.10.7-src.zip/py4j/java_gateway.py", line 1257, in __call__
File "/data/yarn/nm/usercache/zhangbl/appcache/application_1657030920107_2794761/container_e37_1657030920107_2794761_02_000001/pyspark.zip/pyspark/sql/utils.py", line 63, in deco
File "/data/yarn/nm/usercache/zhangbl/appcache/application_1657030920107_2794761/container_e37_1657030920107_2794761_02_000001/py4j-0.10.7-src.zip/py4j/protocol.py", line 328, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o116.save.
: java.lang.ClassNotFoundException: Failed to find data source: com.vesoft.nebula.connector.NebulaDataSource. Please find packages at http://spark.apache.org/third-party-projects.html
at org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSource(DataSource.scala:657)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:244)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.ClassNotFoundException: com.vesoft.nebula.connector.NebulaDataSource.DefaultSource
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$20$$anonfun$apply$12.apply(DataSource.scala:634)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$20$$anonfun$apply$12.apply(DataSource.scala:634)
at scala.util.Try$.apply(Try.scala:192)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$20.apply(DataSource.scala:634)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$20.apply(DataSource.scala:634)
at scala.util.Try.orElse(Try.scala:84)
at org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSource(DataSource.scala:634)
... 12 more
但是如果spark-submit 的时候,用spark.jars 参数则不会报错,请问这个是为什么?我的理解写在sparkconf 里面和提交时参数 应该没有多大区别的?