nebula-exchange导入json数据,一个小时,大概才导入2亿,这个需要怎么优化呢,有60亿关系
# Spark 相关配置
spark: {
app: {
name: Nebula Exchange 3.0.0
}
driver: {
cores: 3
maxResultSize: 1G
}
executor: {
memory:6G
}
cores: {
max: 16
}
}
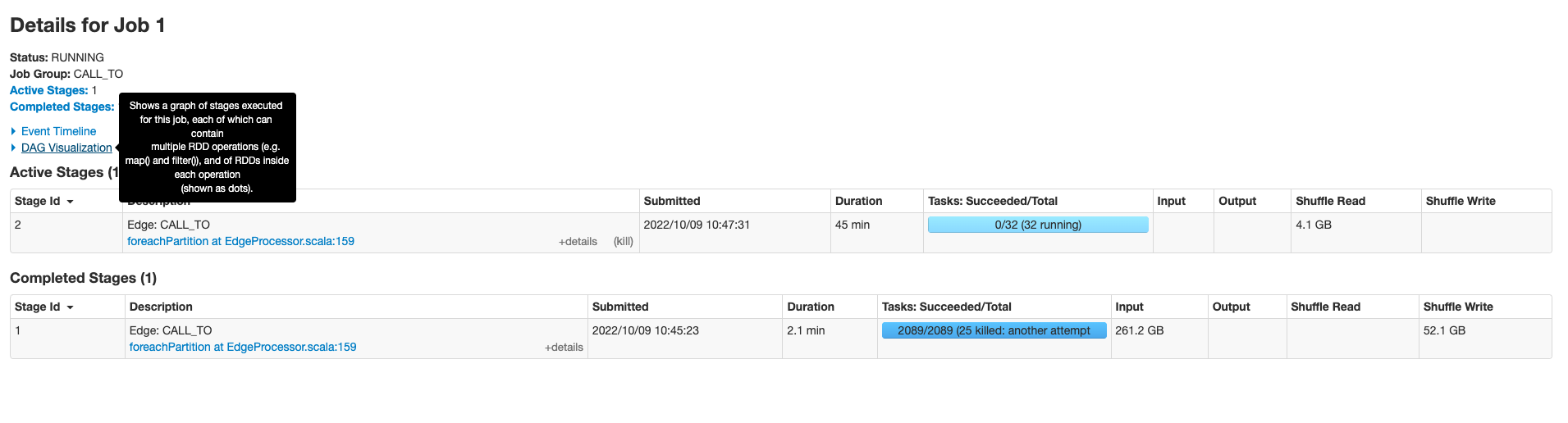
分区数改为256 num-executor改为200
spark-submit --class com.vesoft.nebula.exchange.Exchange --master yarn --name CBK_CENTR_BANK --num-executors 50 --executor-cores 4 --queue root.xy_etl --conf spark.driver.extraClassPath=./ --conf spark.executor.extraClassPath=./ nebula-exchange_spark_2.2-3.0.0.jar -c CBK_CENTR_BANK.con
提高配置中的batch数
增大配置中的partition数
大概调到多少呢
nicole
9
你分配的总核数是50*4=200, partition数可以配置200, 如果一个点或者一个边的属性不多,batch 可以设置2000试下。
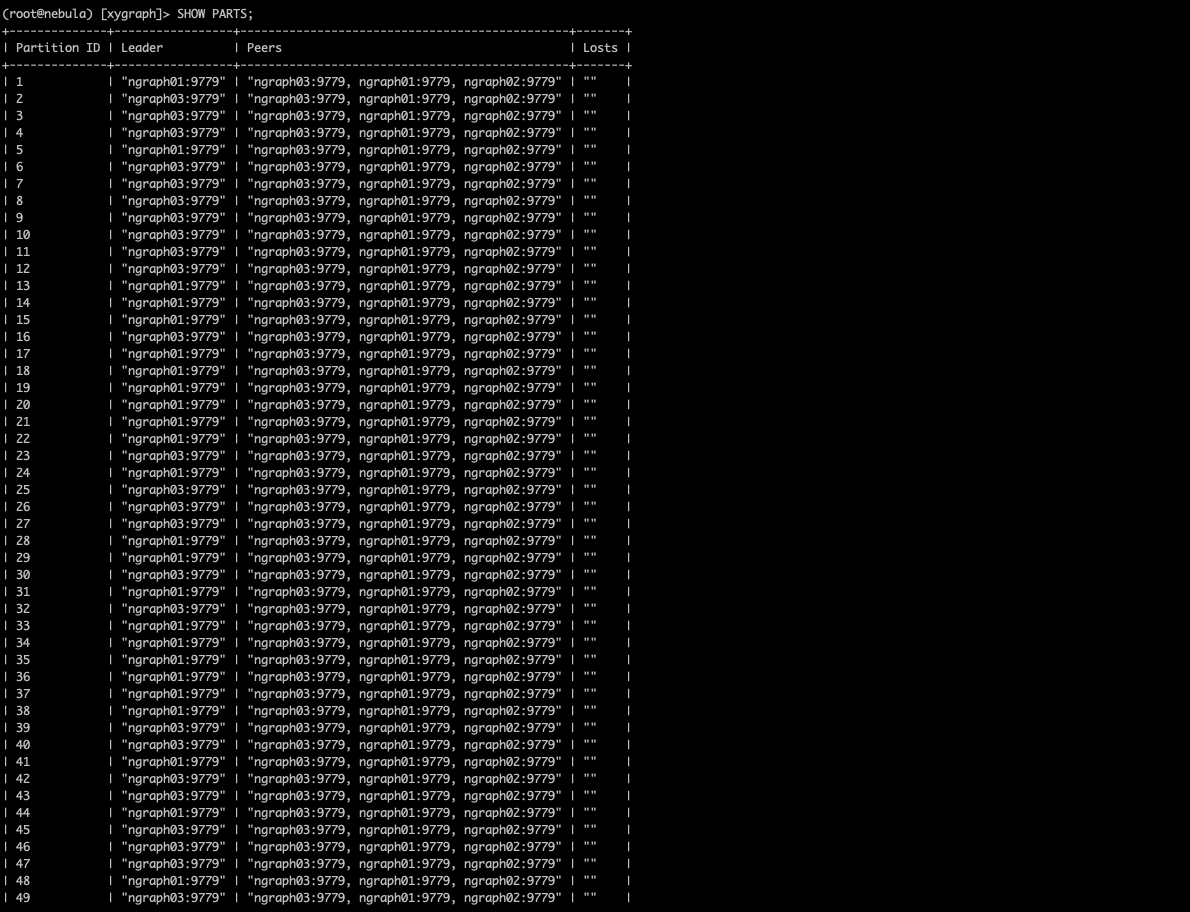
为什么graph02从来没有做过leader呢,这正常吗
nicole
13
raft buffer is full, 这个需要 @critical27 来帮忙看下
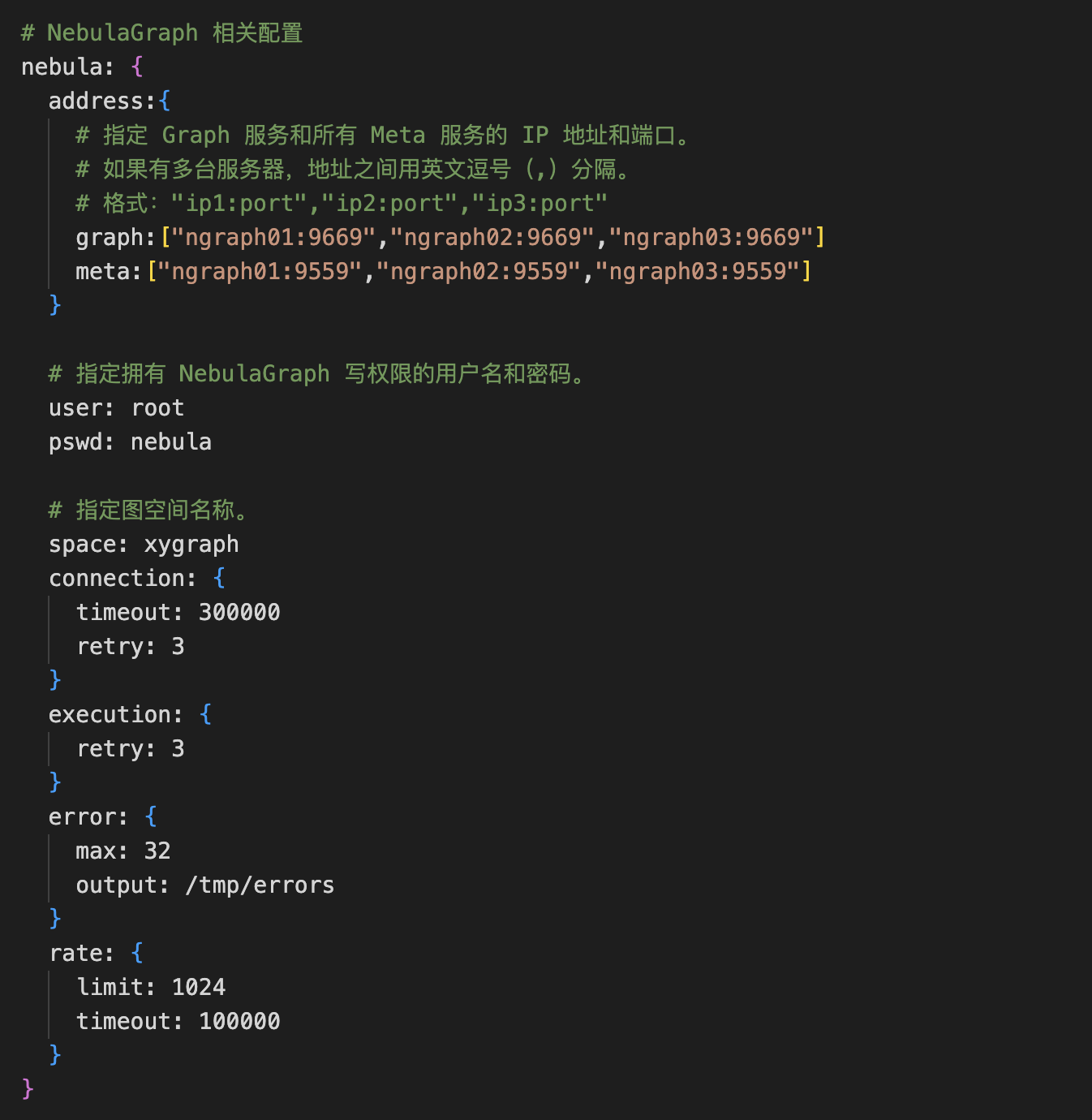
目前的配置
{
# Spark 相关配置
spark: {
app: {
name: Nebula Exchange 3.0.0
}
driver: {
cores: 3
maxResultSize: 1G
}
executor: {
memory:6G
}
cores: {
max: 16
}
}
# NebulaGraph 相关配置
nebula: {
address:{
# 指定 Graph 服务和所有 Meta 服务的 IP 地址和端口。
# 如果有多台服务器,地址之间用英文逗号(,)分隔。
# 格式:"ip1:port","ip2:port","ip3:port"
graph:["ngraph01:9669","ngraph02:9669","ngraph03:9669"]
meta:["ngraph01:9559","ngraph02:9559","ngraph03:9559"]
}
# 指定拥有 NebulaGraph 写权限的用户名和密码。
user: root
pswd: nebula
# 指定图空间名称。
space: xygraph
connection: {
timeout: 300000000
retry: 3
}
execution: {
retry: 3
}
error: {
max: 32
output: /tmp/errors
}
rate: {
limit: 1024
timeout: 300000000
}
}
# 处理边
edges: [
# 设置 Edge type follow 相关信息。
{
# 指定 NebulaGraph 中定义的 Edge type 名称。
name: CALL_TO
type: {
# 指定数据源,使用 JSON。
source: json
# 指定如何将点数据导入 NebulaGraph:Client 或 SST。
sink: client
}
# 指定 JSON 文件的路径。
# 如果文件存储在 HDFS 上,用双引号括起路径,以 hdfs://开头,例如"hdfs://ip:port/xx/xx"。
# 如果文件存储在本地,用双引号括起路径,以 file://开头,例如"file:///tmp/xx.json"。
path: "hdfs://xydwns/tmp/ngraph/CALL_TO_2.json"
# 在 fields 里指定 JSON 文件中 key 名称,其对应的 value 会作为 NebulaGraph 中指定属性的数据源。
# 如果需要指定多个值,用英文逗号(,)隔开。
fields: [cnt,last_callmark_on,first_callmark_on]
# 指定 NebulaGraph 中定义的属性名称。
# fields 与 nebula.fields 的顺序必须一一对应。
nebula.fields: [cnt,last_callmark_on,first_callmark_on]
# 指定一个列作为起始点和目的点的源。
# vertex 的值必须与 JSON 文件中的字段保持一致。
# 目前,NebulaGraph 3.2.1仅支持字符串或整数类型的 VID。
source: {
field: src
}
target: {
field: dst
}
# 指定一个列作为 rank 的源(可选)。
#ranking: rank
# 指定单批次写入 NebulaGraph 的最大边数量。
batch: 2000
# 指定 Spark 分片数量。
partition: 60
}
]
# 如果需要添加更多边,请参考前面的配置进行添加。
}
提交命令
nohup spark-submit --class com.vesoft.nebula.exchange.Exchange --master yarn --name CBK_AUTOMOBILE --num-executors 3 --executor-memory=30G --executor-cores 60 --conf spark.driver.extraClassPath=./ --conf spark.executor.extraClassPath=./ nebula-exchange_spark_2.2-3.0.0.jar -c CBK_AUTOMOBILE.conf >> CBK_AUTOMOBILE.log &
速度依旧很慢,平均一分钟才900万左右,跟你们测试的速度相差太远,这个具体优化点在哪里呢
nicole
15
你的partition才60,分配了180个core, 有120core都是闲置着的
nicole
17
partition 可以调到180,或者360 都行的
1 个赞
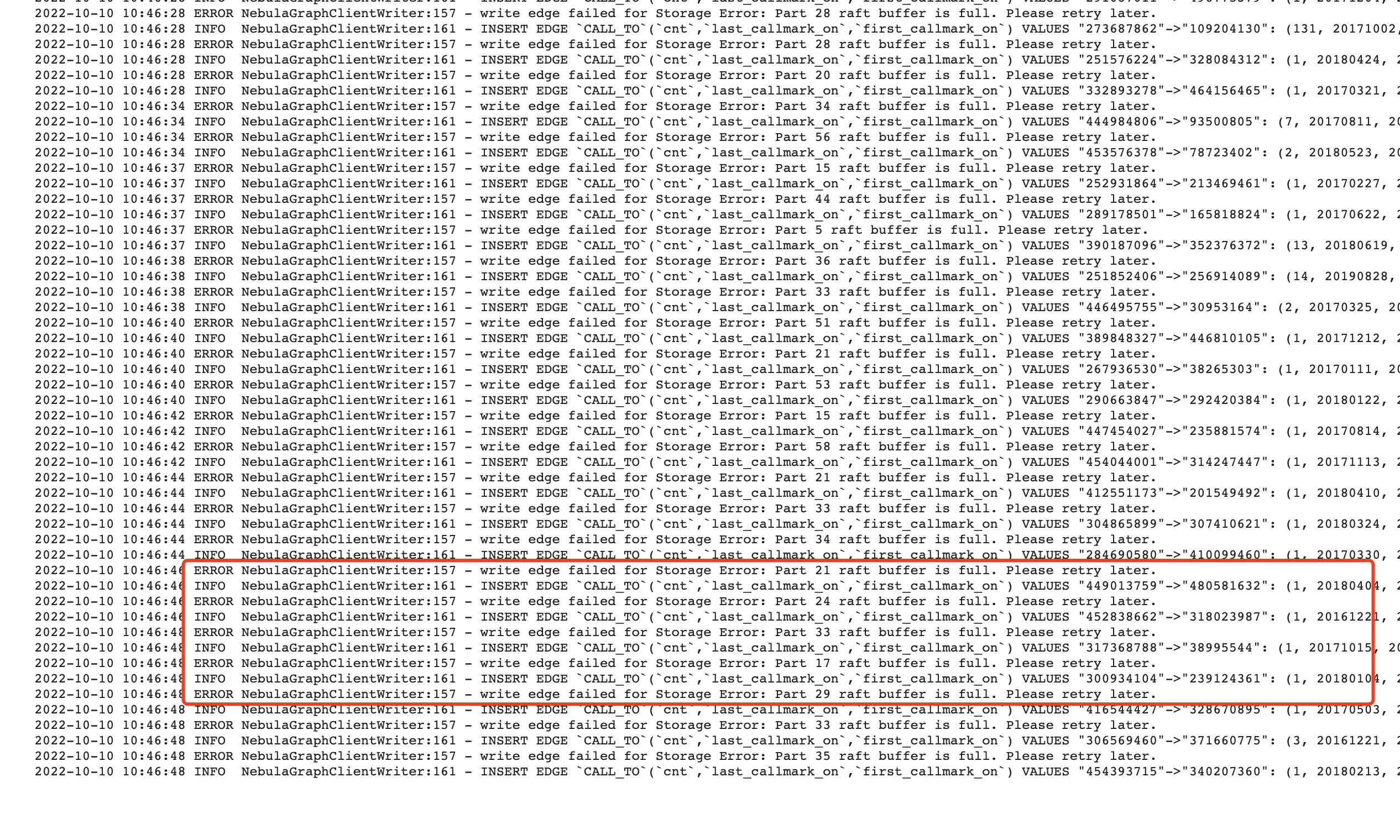
调到180就有writebuffer,有一个writterbuffer错误问题
system
关闭
19
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。