环境信息
- nebula 版本:3.2.0
- 部署方式:分布式 3节点
- 安装方式:RPM
- 是否为线上版本:测试环境
- 硬件信息
- 磁盘 阿里云高效云盘 300G* 1
- CPU、内存信息 4C 16G
- 问题的具体描述
我们在开发数据资产管理平台,参考业内标杆的开源系统Apache Altas / Linkedin Datahub,其底层的存储均仅有一个数据库,Apache Altas(Janus Graph) Linkin Datahub(neo4j),在做数据资产的地图检索的时候,某种特定的资产肯定会有分页查询,比如我们举下面一个例子:

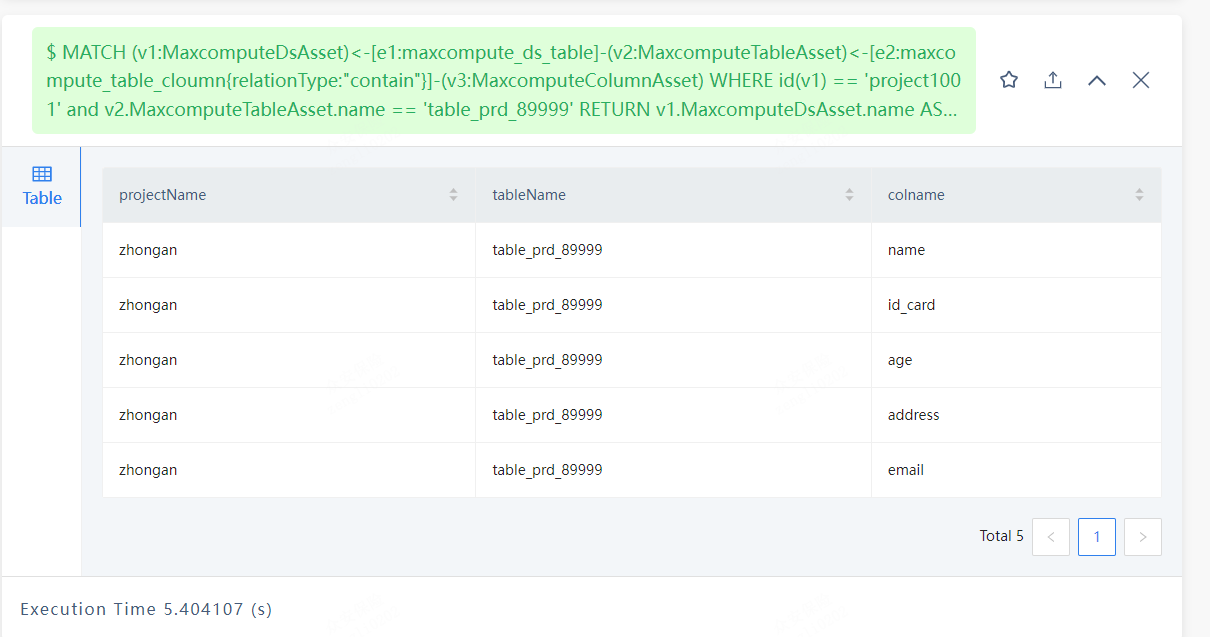
比如一个Maxcompute数据源资产(某个项目空间),其下有表资产,表资产下有列资产。
其在nebulagraph的模型为
TAG
MaxcomputeDsAsset(数据源 项目空间)
MaxcomputeTableAsset(表)
MaxcomputeColumnAsset(列)
Edge
maxcompute_ds_table (项目空间 表关联关系)
maxcompute_table_cloumn(表 列关联关系)
索引
MaxcomputeDsAsset project_name 字段
MaxcomputeTableAsset table_name 字段
MaxcomputeColumnAsset column_name 字段
我们造了一些测试数据,模拟查询 (先模拟一跳分页,没模拟列)
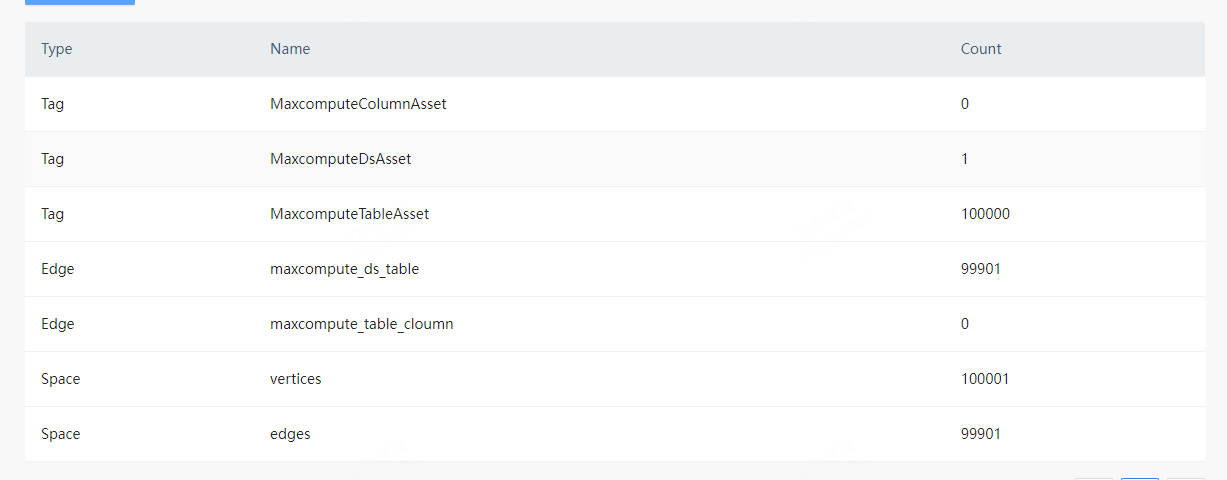
MaxcomputeDsAsset 1个
MaxcomputeTableAsset 10w个 (一个项目空间 10w表)
MaxcomputeTableAsset 20w个(每个表 2列)
集群参数优化(参考论坛和官方配置):
storaged配置
–query_concurrently=true
–rocksdb_column_family_options={“write_buffer_size”:“67108864”,“max_write_buffer_number”:“4”,“max_bytes_for_level_base”:“268435456”,“disable_auto_compactions”:false}
–rocksdb_enable_kv_separation=true
–enable_rocksdb_prefix_filtering=true
–enable_rocksdb_whole_key_filtering=false
–enable_partitioned_index_filter=true
–rocksdb_filtering_prefix_length=12
–rocksdb_block_cache=256
graphd配置
–num_operator_threads=4
我们在做数据地图检索的时候,会先指定选择资产类型,是表或者是列;
我们有如下几个场景:
1.选定资产类型为MaxComputeTable,筛选条件仅table名称前缀过滤
很显然这是一个基于索引的Lookup
LOOKUP ON MaxcomputeTableAsset WHERE MaxcomputeTableAsset.name STARTS WITH ‘table’ YIELD properties(vertex) | limit 1, 10
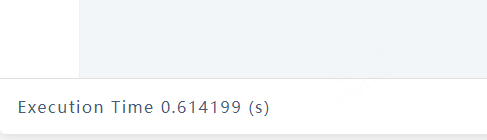
查询速度很快,在毫秒级;
2.选定资产类型为MaxComputeTable,筛选条件新增数据源,table名称前缀过滤不变
这时就无法仅仅对MaxComputeTable的属性进行过滤,需要基于某个MaxcomputeDsAsset 数据源的点,进行1跳过滤的分页查询
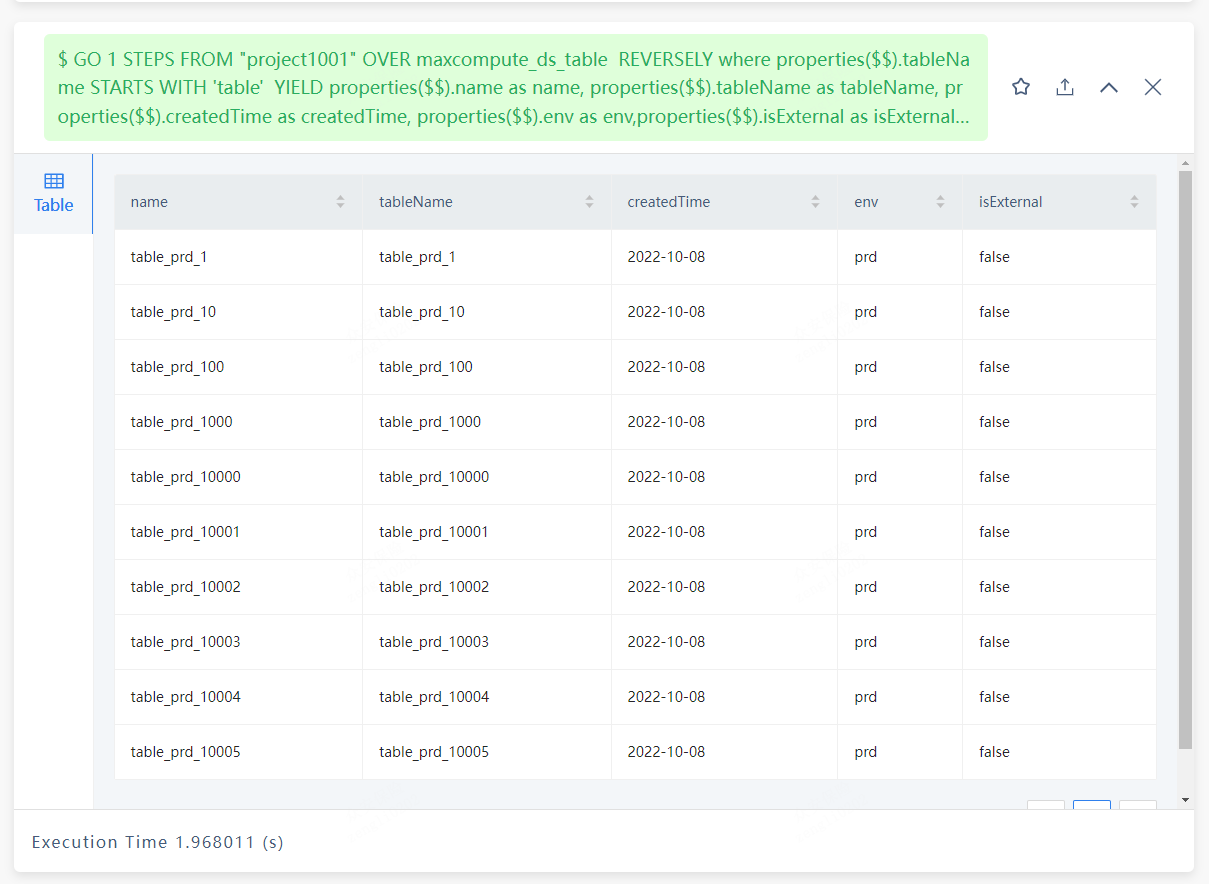
采用GO语句
GO 1 STEPS FROM “project1001” OVER maxcompute_ds_table REVERSELY where properties($$).name STARTS WITH ‘table’ YIELD properties($$).name as name, properties($$).tableName as tableName, properties($$).createdTime as createdTime, properties($$).env as env,properties($$).isExternal as isExternal | LIMIT 1,20
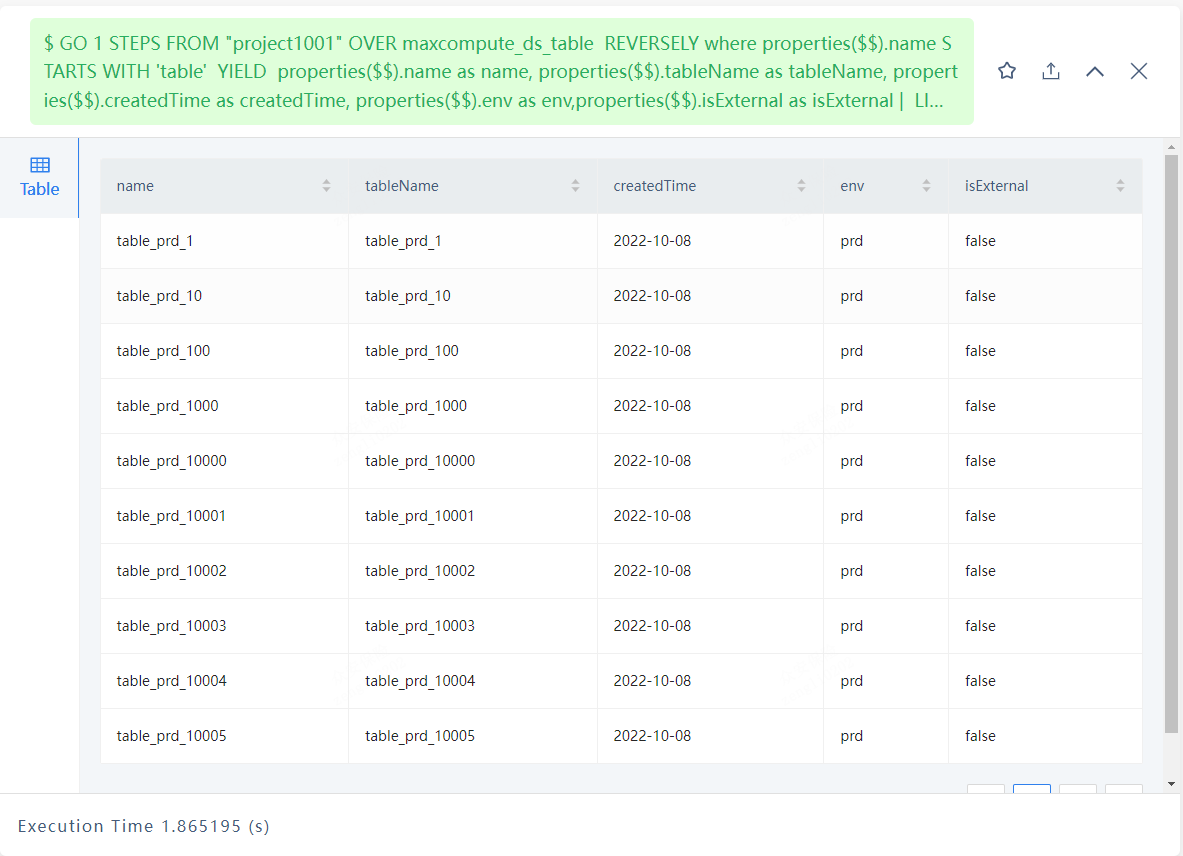
耗时在1.8s
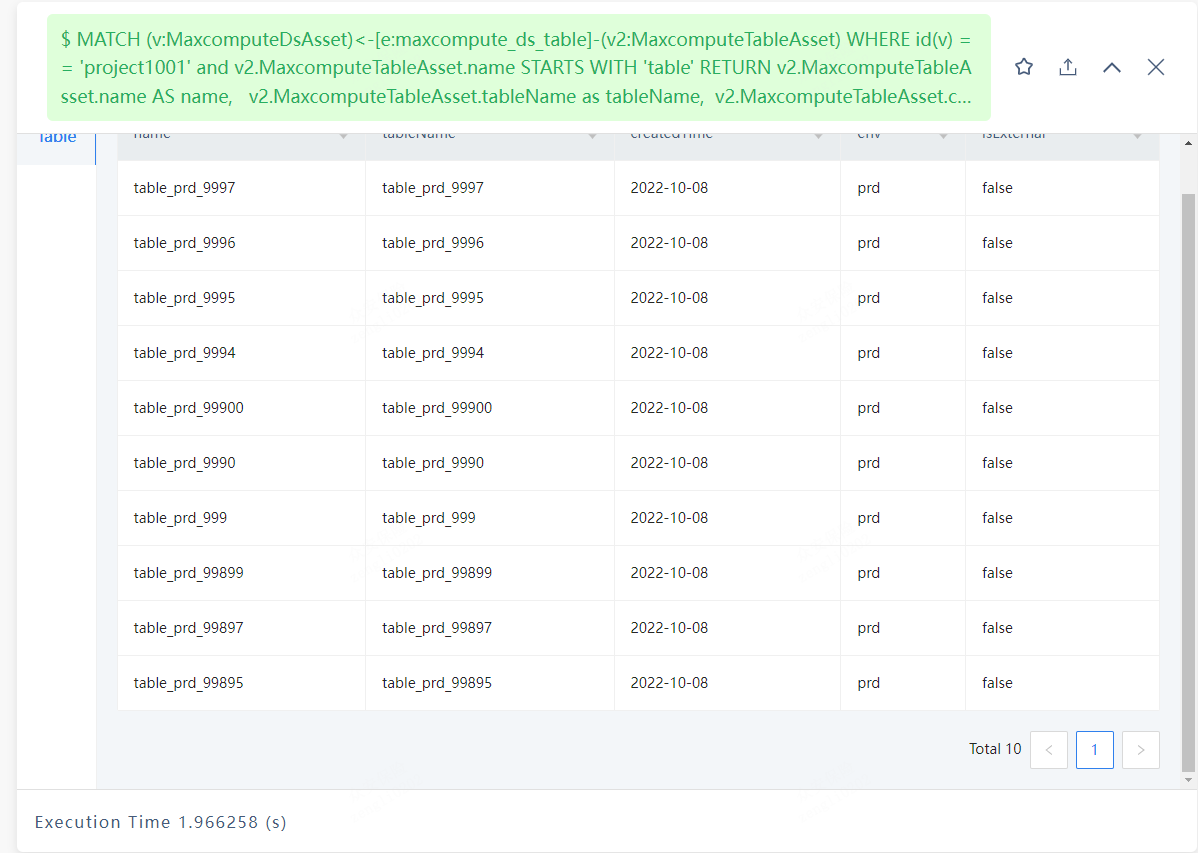
使用Match语句
MATCH (v:MaxcomputeDsAsset)<–(v2:MaxcomputeTableAsset) WHERE id(v) == ‘project1001’ and v2.MaxcomputeTableAsset.name STARTS WITH ‘table’ RETURN v2.MaxcomputeTableAsset.name AS name, v2.MaxcomputeTableAsset.tableName as tableName, v2.MaxcomputeTableAsset.createdTime as createdTime, v2.MaxcomputeTableAsset.env as env, v2.MaxcomputeTableAsset.isExternal as isExternal skip 0 limit 10;
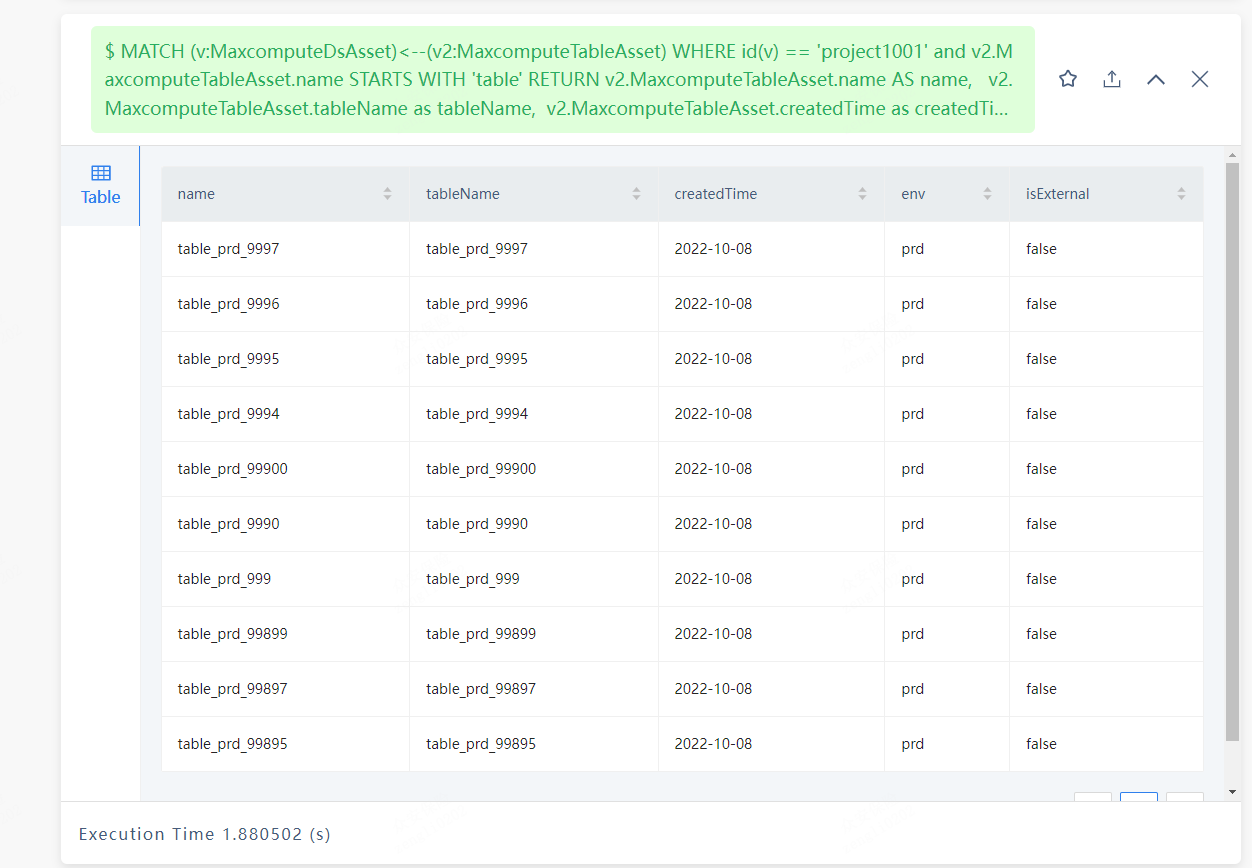
耗时在1.8s
同时我们根据实际生产数据,最大的项目空间下有5.5w张表,进行模拟
– 出边 15w 1跳 Execution Time 3.562981 (s)
– 出边 10w 1跳 Execution Time 1.710542 (s)
– 出边 5w 1跳 Execution Time 1.01257 (s)
– 出边2.5w 1跳 Execution Time 0.56089 (s)
– 出边 1w 1跳 Execution Time 0.167283 (s)
– 出边0.5w 1跳 Execution Time 0.085381 (s)
发现出边越少,性能越好,但是到10w级左右时,耗时已经有明显下降
我们用其他组的neo4j相关模拟进行查询
1跳 用户资源总数据量14w
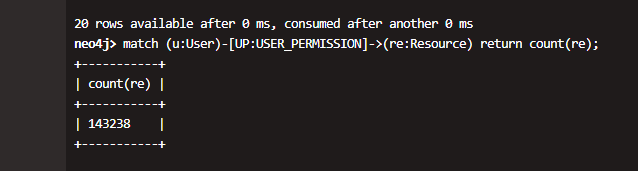
1跳 用户资源分页查询 ,耗时在几十毫秒

想咨询一下,是否有优化的可能。