- nebula 版本:
- 部署方式:分布式
- 安装方式:RPM
- 是否为线上版本:Y
- 硬件信息
- 磁盘( 推荐使用 SSD)SSD
- CPU、内存信息
32c128g 一共五台服务器
202 metad:9559 graphd:9669 storaged:9779
- 磁盘( 推荐使用 SSD)SSD

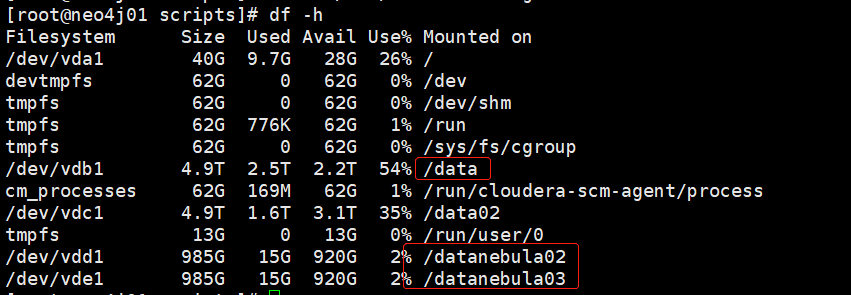
203 metad:9559 graphd:9669 storaged:9779
204 metad:9559 graphd:9669 storaged:9779
205 graphd:9669 storaged:9779
206 graphd:9669 storaged:9779
-
问题的具体描述
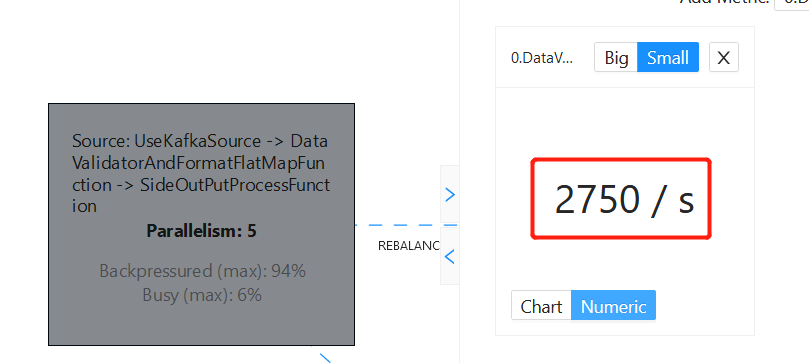
使用Flink消费Kafka后写入Nebula
发现写入速度越来越慢 日志没有明显错误 求解!
-
相关的 meta / storage / graph info 日志信息(尽量使用文本形式方便检索)
meta配置
########## basics ##########
# Whether to run as a daemon process
--daemonize=true
# The file to host the process id
--pid_file=pids/nebula-metad.pid
########## logging ##########
# The directory to host logging files
--log_dir=logs
# Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=0
# Verbose log level, 1, 2, 3, 4, the higher of the level, the more verbose of the logging
--v=0
# Maximum seconds to buffer the log messages
--logbufsecs=0
# Whether to redirect stdout and stderr to separate output files
--redirect_stdout=true
# Destination filename of stdout and stderr, which will also reside in log_dir.
--stdout_log_file=metad-stdout.log
--stderr_log_file=metad-stderr.log
# Copy log messages at or above this level to stderr in addition to logfiles. The numbers of severity levels INFO, WARNING, ERROR, and FATAL are 0, 1, 2, and 3, respectively.
--stderrthreshold=2
--meta_client_timeout_ms=6000000
--session_idle_timeout_secs=600
########## networking ##########
# Comma separated Meta Server addresses
--meta_server_addrs=172.17.126.202:9559,172.17.126.203:9559,172.17.126.204:9559
# Local IP used to identify the nebula-metad process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=172.17.126.202
# Meta daemon listening port
--port=9559
# HTTP service ip
--ws_ip=0.0.0.0
# HTTP service port
--ws_http_port=19559
# HTTP2 service port
--ws_h2_port=19560
# Port to listen on Storage with HTTP protocol, it corresponds to ws_http_port in storage's configuration file
--ws_storage_http_port=19779
########## storage ##########
# Root data path, here should be only single path for metad
--data_path=/data/nebula/meta
########## Misc #########
# The default number of parts when a space is created
--default_parts_num=60
# The default replica factor when a space is created
--default_replica_factor=3
--heartbeat_interval_secs=10
--timezone_name=UTC+08:00
graph配置
########## basics ##########
# Whether to run as a daemon process
--daemonize=true
# The file to host the process id
--pid_file=pids/nebula-graphd.pid
# Whether to enable optimizer
--enable_optimizer=true
# The default charset when a space is created
--default_charset=utf8
# The defaule collate when a space is created
--default_collate=utf8_bin
# Whether to use the configuration obtained from the configuration file
--local_config=true
########## logging ##########
# The directory to host logging files
--log_dir=logs
# Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=0
# Verbose log level, 1, 2, 3, 4, the higher of the level, the more verbose of the logging
--v=0
# Maximum seconds to buffer the log messages
--logbufsecs=0
# Whether to redirect stdout and stderr to separate output files
--redirect_stdout=true
# Destination filename of stdout and stderr, which will also reside in log_dir.
--stdout_log_file=graphd-stdout.log
--stderr_log_file=graphd-stderr.log
# Copy log messages at or above this level to stderr in addition to logfiles. The numbers of severity levels INFO, WARNING, ERROR, and FATAL are 0, 1, 2, and 3, respectively.
--stderrthreshold=2
########## query ##########
# Whether to treat partial success as an error.
# This flag is only used for Read-only access, and Modify access always treats partial success as an error.
--accept_partial_success=false
# Maximum sentence length, unit byte
--max_allowed_query_size=4194304
########## networking ##########
# Comma separated Meta Server Addresses
--meta_server_addrs=172.17.126.202:9559,172.17.126.203:9559,172.17.126.204:9559
# Local IP used to identify the nebula-graphd process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=172.17.126.202
# Network device to listen on
--listen_netdev=any
# Port to listen on
--port=9669
# To turn on SO_REUSEPORT or not
--reuse_port=false
# Backlog of the listen socket, adjust this together with net.core.somaxconn
--listen_backlog=1024
# Seconds before the idle connections are closed, 0 for never closed
--client_idle_timeout_secs=300
# Seconds before the idle sessions are expired, 0 for no expiration
--session_idle_timeout_secs=300
# The number of threads to accept incoming connections
--num_accept_threads=1
# The number of networking IO threads, 0 for # of CPU cores
--num_netio_threads=0
# The number of threads to execute user queries, 0 for # of CPU cores
--num_worker_threads=0
# HTTP service ip
--ws_ip=0.0.0.0
# HTTP service port
--ws_http_port=19669
# HTTP2 service port
--ws_h2_port=19670
# storage client timeout
--storage_client_timeout_ms=300000
# Port to listen on Meta with HTTP protocol, it corresponds to ws_http_port in metad's configuration file
--ws_meta_http_port=19559
########## authentication ##########
# Enable authorization
--enable_authorize=false
# User login authentication type, password for nebula authentication, ldap for ldap authentication, cloud for cloud authentication
--auth_type=password
########## memory ##########
# System memory high watermark ratio
--system_memory_high_watermark_ratio=0.9
########## experimental feature ##########
# if use experimental features
--enable_experimental_feature=false
--timezone_name=UTC+08:00
storage配置
########## basics ##########
# Whether to run as a daemon process
--daemonize=true
# The file to host the process id
--pid_file=pids/nebula-storaged.pid
# Whether to use the configuration obtained from the configuration file
--local_config=true
########## logging ##########
# The directory to host logging files
--log_dir=logs
# Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=0
# Verbose log level, 1, 2, 3, 4, the higher of the level, the more verbose of the logging
--v=0
# Maximum seconds to buffer the log messages
--logbufsecs=0
# Whether to redirect stdout and stderr to separate output files
--redirect_stdout=true
# Destination filename of stdout and stderr, which will also reside in log_dir.
--stdout_log_file=storaged-stdout.log
--stderr_log_file=storaged-stderr.log
# Copy log messages at or above this level to stderr in addition to logfiles. The numbers of severity levels INFO, WARNING, ERROR, and FATAL are 0, 1, 2, and 3, respectively.
--stderrthreshold=2
########## networking ##########
# Comma separated Meta server addresses
--meta_server_addrs=172.17.126.202:9559,172.17.126.203:9559,172.17.126.204:9559
# Local IP used to identify the nebula-storaged process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=172.17.126.202
# Storage daemon listening port
--port=9779
# HTTP service ip
--ws_ip=0.0.0.0
# HTTP service port
--ws_http_port=19779
# HTTP2 service port
--ws_h2_port=19780
# heartbeat with meta service
--heartbeat_interval_secs=10
######### Raft #########
# Raft election timeout
--raft_heartbeat_interval_secs=60
# RPC timeout for raft client (ms)
--raft_rpc_timeout_ms=10000
## recycle Raft WAL
--wal_ttl=28800
--storage_client_timeout_ms=6000000
########## Disk ##########
# Root data path. Split by comma. e.g. --data_path=/disk1/path1/,/disk2/path2/
# One path per Rocksdb instance.
--data_path=/data/nebula/data/storage/,/datanebula02/nebula/data/storage/,/datanebula03/nebula/data/storage/
# Minimum reserved bytes of each data path
--minimum_reserved_bytes=268435456
# The default reserved bytes for one batch operation
--rocksdb_batch_size=4096
--auto_remove_invalid_space=true
# The default block cache size used in BlockBasedTable.
# The unit is MB.
--rocksdb_block_cache=4
# The type of storage engine, `rocksdb', `memory', etc.
--engine_type=rocksdb
# Compression algorithm, options: no,snappy,lz4,lz4hc,zlib,bzip2,zstd
# For the sake of binary compatibility, the default value is snappy.
# Recommend to use:
# * lz4 to gain more CPU performance, with the same compression ratio with snappy
# * zstd to occupy less disk space
# * lz4hc for the read-heavy write-light scenario
--rocksdb_compression=lz4
# Set different compressions for different levels
# For example, if --rocksdb_compression is snappy,
# "no:no:lz4:lz4::zstd" is identical to "no:no:lz4:lz4:snappy:zstd:snappy"
# In order to disable compression for level 0/1, set it to "no:no"
--rocksdb_compression_per_level=
# Whether or not to enable rocksdb's statistics, disabled by default
--enable_rocksdb_statistics=false
# Statslevel used by rocksdb to collection statistics, optional values are
# * kExceptHistogramOrTimers, disable timer stats, and skip histogram stats
# * kExceptTimers, Skip timer stats
# * kExceptDetailedTimers, Collect all stats except time inside mutex lock AND time spent on compression.
# * kExceptTimeForMutex, Collect all stats except the counters requiring to get time inside the mutex lock.
# * kAll, Collect all stats
--rocksdb_stats_level=kExceptHistogramOrTimers
# Whether or not to enable rocksdb's prefix bloom filter, enabled by default.
--enable_rocksdb_prefix_filtering=true
# Whether or not to enable rocksdb's whole key bloom filter, disabled by default.
--enable_rocksdb_whole_key_filtering=false
############## rocksdb Options ##############
# rocksdb DBOptions in json, each name and value of option is a string, given as "option_name":"option_value" separated by comma
--rocksdb_db_options={}
# rocksdb ColumnFamilyOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_column_family_options={"write_buffer_size":"134217728","max_write_buffer_number":"10","target_file_size_base":"67108864","level0_file_num_compaction_trigger":"16","disable_auto_compactions":"false","level0_slowdown_writes_trigger":"40","level0_stop_writes_trigger":"50","max_bytes_for_level_base":"1073741824","max_bytes_for_level_multiplier":"16"}
# rocksdb BlockBasedTableOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_block_based_table_options={"block_size":"32768","cache_index_and_filter_blocks":"true"}
--timezone_name=UTC+08:00
#--num_io_threads=32
#--num_worker_threads=32
#--max_concurrent_subtasks=32
#--snapshot_part_rate_limit=52428800
#--snapshot_batch_size=10485760
#--rebuild_index_part_rate_limit=20971520
#--rebuild_index_batch_size=5242880
#--max_edge_returned_per_vertex=100000000
#--rocksdb_rate_limit=200
#--enable_partitioned_index_filter=true
meta日志
I20221026 14:08:55.842074 30920 EventListener.h:21] Rocksdb start compaction column family: default because of LevelL0FilesNum, status: OK, compacted 5 files into 0, base level is 0, output level is 1
I20221026 14:08:55.956387 30920 EventListener.h:35] Rocksdb compaction completed column family: default because of LevelL0FilesNum, status: OK, compacted 5 files into 1, base level is 0, output level is 1
I20221026 14:13:44.799752 30920 EventListener.h:21] Rocksdb start compaction column family: default because of LevelL0FilesNum, status: OK, compacted 5 files into 0, base level is 0, output level is 1
I20221026 14:13:44.934183 30920 EventListener.h:35] Rocksdb compaction completed column family: default because of LevelL0FilesNum, status: OK, compacted 5 files into 1, base level is 0, output level is 1
graph日志
I20221026 14:12:40.405613 12949 GraphSessionManager.cpp:219] ClientSession 1666763715787785 has expired
I20221026 14:12:40.406301 12949 GraphSessionManager.cpp:219] ClientSession 1666763715702036 has expired
I20221026 14:12:40.407793 12949 GraphSessionManager.cpp:219] ClientSession 1666763715769109 has expired
I20221026 14:12:40.408385 12949 GraphSessionManager.cpp:219] ClientSession 1666763715757346 has expired
I20221026 14:12:40.408932 12949 GraphSessionManager.cpp:219] ClientSession 1666763715707444 has expired
I20221026 14:12:40.409466 12949 GraphSessionManager.cpp:219] ClientSession 1666763715731261 has expired
I20221026 14:12:40.410030 12949 GraphSessionManager.cpp:219] ClientSession 1666763715716685 has expired
I20221026 14:12:40.411563 12949 GraphSessionManager.cpp:219] ClientSession 1666763715746657 has expired
I20221026 14:12:40.412112 12949 GraphSessionManager.cpp:219] ClientSession 1666763715730550 has expired
I20221026 14:12:40.412626 12949 GraphSessionManager.cpp:219] ClientSession 1666763715791751 has expired
I20221026 14:12:40.413147 12949 GraphSessionManager.cpp:219] ClientSession 1666763715746953 has expired
I20221026 14:12:40.413641 12949 GraphSessionManager.cpp:219] ClientSession 1666763715773585 has expired
I20221026 14:12:40.414265 12949 GraphSessionManager.cpp:219] ClientSession 1666763715773847 has expired
I20221026 14:12:40.414739 12949 GraphSessionManager.cpp:219] ClientSession 1666763715765938 has expired
I20221026 14:12:40.415223 12949 GraphSessionManager.cpp:219] ClientSession 1666763715795925 has expired
I20221026 14:12:40.415736 12949 GraphSessionManager.cpp:219] ClientSession 1666763715751128 has expired
I20221026 14:12:40.416201 12949 GraphSessionManager.cpp:219] ClientSession 1666763715699929 has expired
I20221026 14:12:40.416675 12949 GraphSessionManager.cpp:219] ClientSession 1666763715752670 has expired
I20221026 14:12:40.417114 12949 GraphSessionManager.cpp:219] ClientSession 1666763715789567 has expired
E20221026 14:13:14.558285 12846 QueryInstance.cpp:137] SemanticError: Column count doesn't match value count.
E20221026 14:14:22.091053 12847 QueryInstance.cpp:137] SemanticError: Column count doesn't match value count.
E20221026 14:14:22.777086 12862 QueryInstance.cpp:137] SemanticError: Column count doesn't match value count.
I20221026 14:14:42.840534 12949 GraphSessionManager.cpp:219] ClientSession 1666764617994148 has expired
storage日志
I20221026 14:15:41.083765 12371 CompactionFilter.h:92] Do default minor compaction!
I20221026 14:16:31.291898 12371 EventListener.h:35] Rocksdb compaction completed column family: default because of LevelL0FilesNum, status: OK, compacted 74 files into 36, base level is 0, output level is 1
I20221026 14:16:31.743239 12371 EventListener.h:158] Stall conditions changed column family: default, current condition: Normal, previous condition: Delayed
I20221026 14:16:31.743777 12371 EventListener.h:21] Rocksdb start compaction column family: default because of LevelMaxLevelSize, status: OK, compacted 2 files into 0, base level is 1, output level is 2
I20221026 14:16:31.743816 12371 CompactionFilter.h:92] Do default minor compaction!
I20221026 14:16:33.000794 12371 EventListener.h:35] Rocksdb compaction completed column family: default because of LevelMaxLevelSize, status: OK, compacted 2 files into 1, base level is 1, output level is 2
I20221026 14:16:33.002121 12371 EventListener.h:21] Rocksdb start compaction column family: default because of LevelMaxLevelSize, status: OK, compacted 6 files into 0, base level is 1, output level is 2
I20221026 14:16:33.002164 12371 CompactionFilter.h:92] Do default minor compaction!
I20221026 14:16:42.336824 12371 EventListener.h:35] Rocksdb compaction completed column family: default because of LevelMaxLevelSize, status: OK, compacted 6 files into 7, base level is 1, output level is 2
I20221026 14:16:42.394048 12371 EventListener.h:21] Rocksdb start compaction column family: default because of LevelMaxLevelSize, status: OK, compacted 7 files into 0, base level is 1, output level is 2
I20221026 14:16:42.394093 12371 CompactionFilter.h:92] Do default minor compaction!
I20221026 14:16:58.006485 12371 EventListener.h:35] Rocksdb compaction completed column family: default because of LevelMaxLevelSize, status: OK, compacted 7 files into 7, base level is 1, output level is 2
I20221026 14:16:58.008047 12371 EventListener.h:21] Rocksdb start compaction column family: default because of LevelMaxLevelSize, status: OK, compacted 9 files into 0, base level is 1, output level is 2
I20221026 14:16:58.008098 12371 CompactionFilter.h:92] Do default minor compaction!
I20221026 14:17:08.585141 12372 EventListener.h:158] Stall conditions changed column family: default, current condition: Delayed, previous condition: Normal
I20221026 14:17:15.045038 12371 EventListener.h:35] Rocksdb compaction completed column family: default because of LevelMaxLevelSize, status: OK, compacted 9 files into 9, base level is 1, output level is 2
I20221026 14:17:15.123966 12371 EventListener.h:21] Rocksdb start compaction column family: default because of LevelL0FilesNum, status: OK, compacted 72 files into 0, base level is 0, output level is 1
I20221026 14:17:15.124289 12371 CompactionFilter.h:92] Do default minor compaction!
I20221026 14:18:05.766561 12371 EventListener.h:35] Rocksdb compaction completed column family: default because of LevelL0FilesNum, status: OK, compacted 72 files into 37, base level is 0, output level is 1
I20221026 14:18:06.219296 12371 EventListener.h:158] Stall conditions changed column family: default, current condition: Normal, previous condition: Delayed
I20221026 14:18:06.219981 12371 EventListener.h:21] Rocksdb start compaction column family: default because of LevelMaxLevelSize, status: OK, compacted 7 files into 0, base level is 1, output level is 2
I20221026 14:18:06.220031 12371 CompactionFilter.h:92] Do default minor compaction!