Warning Unhealthy 5s kubelet Readiness probe failed: Get “http://10.233.70.98:19559/status”: dial tcp 10.233.70.98:19559: connect: connection refused

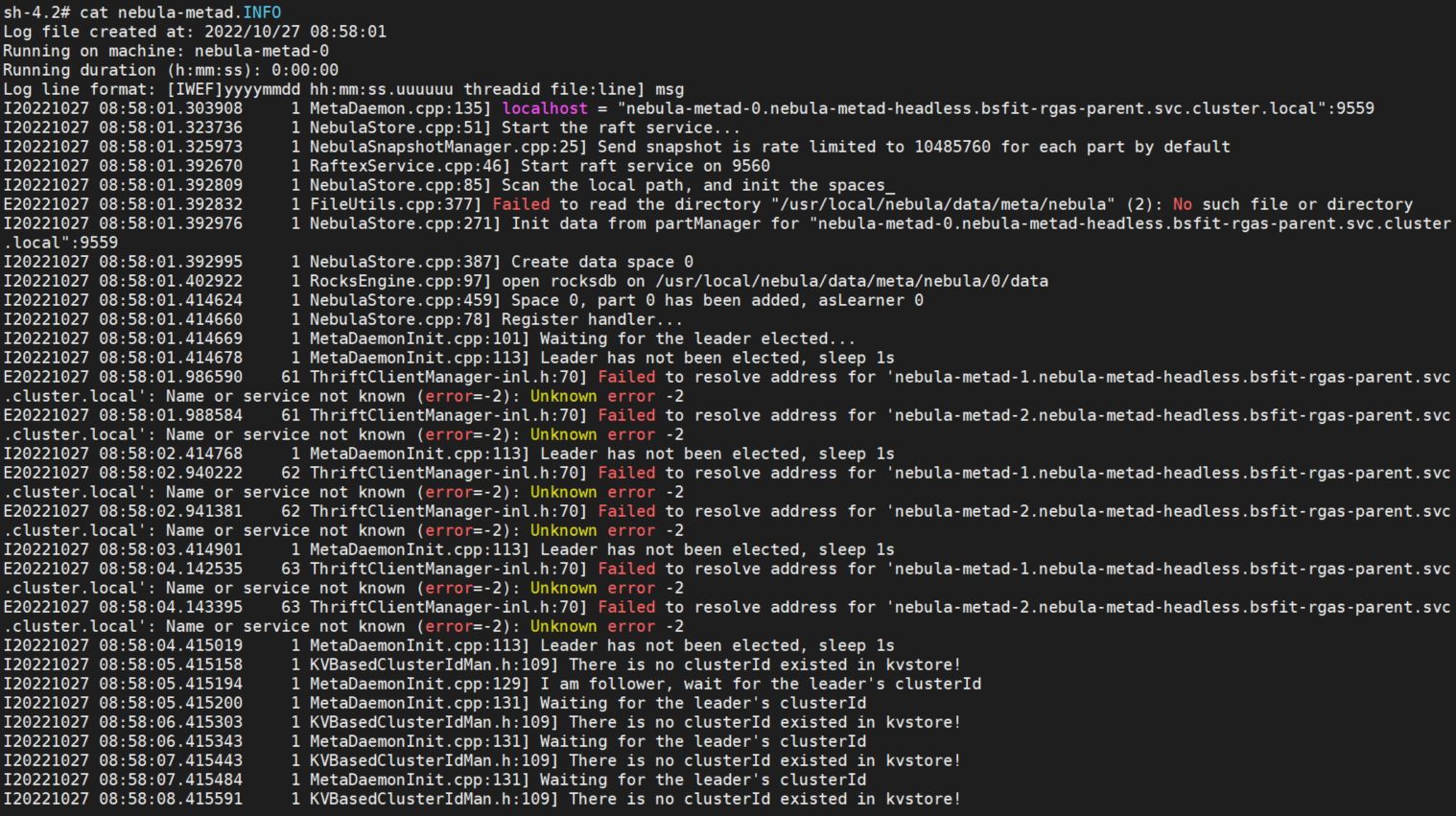
进入metad-0查看日志
E20221027 08:58:01.392832 1 FileUtils.cpp:377] Failed to read the directory “/usr/local/nebula/data/meta/nebula” (2): No such file or directory
E20221027 08:58:01.986590 61 ThriftClientManager-inl.h:70] Failed to resolve address for ‘nebula-metad-1.nebula-metad-headless.bsfit-rgas-parent.svc.cluster.local’: Name or service not known (error=-2): Unknown error -2
E20221027 08:58:01.988584 61 ThriftClientManager-inl.h:70] Failed to resolve address for ‘nebula-metad-2.nebula-metad-headless.bsfit-rgas-parent.svc.cluster.local’: Name or service not known (error=-2): Unknown error -2