- nebula 版本:v3.2.1
- 部署方式:分布式
- 安装方式:RPM
- 是否为线上版本:Y
- 硬件信息
- 问题的具体描述
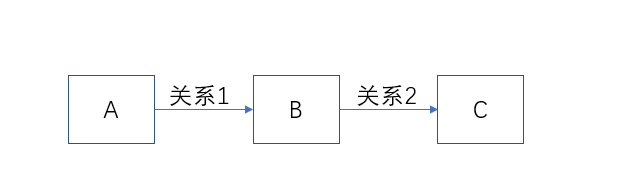
关系如图所示,已知点A的id和目标点C的tag,想查询出符合条件的两跳或三跳的路径,我写的gqls:
MATCH p=(v)-[e:关系1|关系2*3]-(v2:C) where id(v)== “VID” RETURN DISTINCT p limit 100;
路径上的关系1或者2可能数量上千万,也存在稠密点,就设置了max_edge_returned_per_vertex= 1000,两跳的时候查询时间一分钟左右,三跳的时候基本查不出来了,有什么好的优化办法吗?感谢
观察到内存占用很大,达到几十G,但还没有OOM,主要是时间太久,我把超时时间调到十分钟也没查出来
可以 profile 一下 看看 瓶颈在哪一个算子里
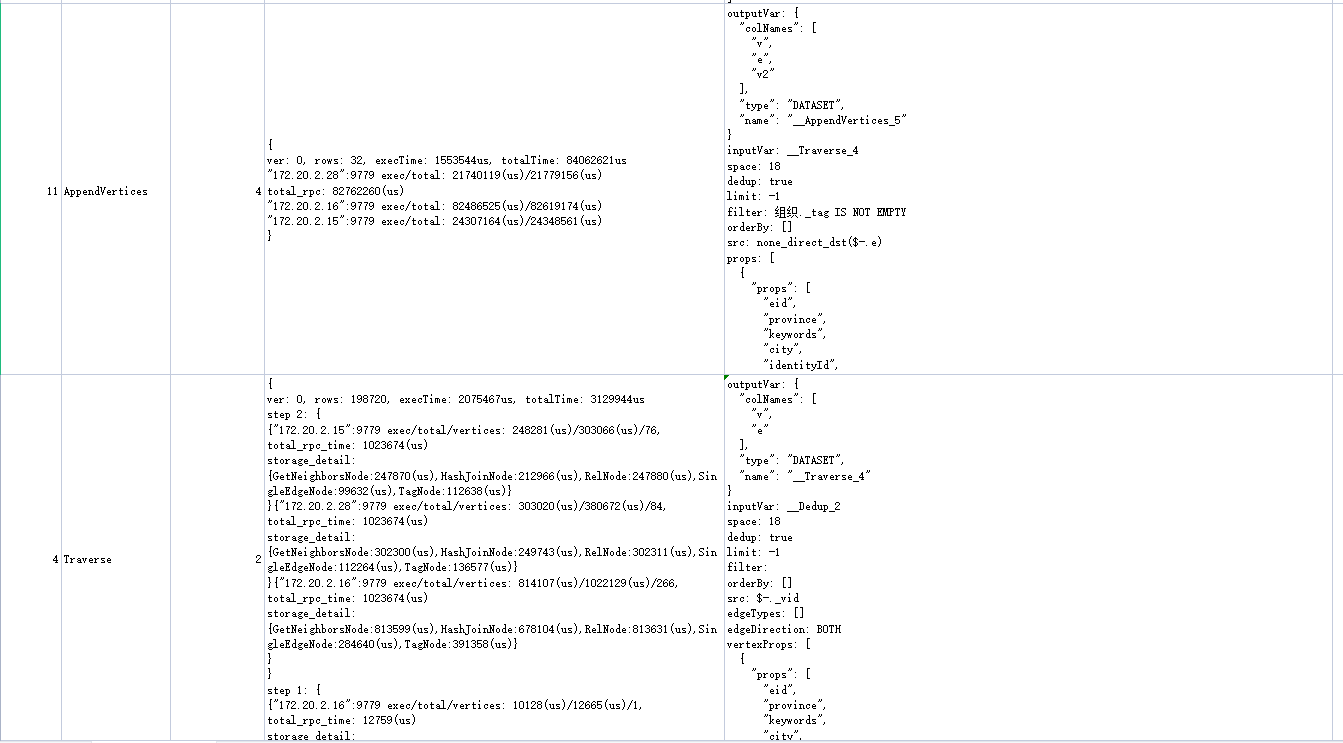
最耗时间的是这两步,语句是MATCH p=(v)-[e:involveTo|belongTo|likeTo*2]-(v2:组织) where id(v)== “事件_skynet事件_13” RETURN DISTINCT p limit 100; 这是查了两步的,三步就会超时了
1 做一下 compaction, 运行命令 SUBMIT JOB COMPACT;
2、在nebula-graph.conf 配置文件中 添加 max_job_size, 可以设置为 服务器核心数目 乘以0.5 到0.7 之间 的数字,增加并行度
1 个赞
wzxstc
9
已经做了compaction,max_job_size也增加之后查询速度确实快了不少,但瓶颈还是存在。随着查询条件里的关系增多,几十G的内存几乎被拉满影响了速度,又查不出来了。感觉单纯增加硬件资源并不能从根本上解决问题,或者有什么从设计上的解决方案么?
system
关闭
11
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。