nebula2.0.1用spark-connect reader读取点然后写入hive,读取止20%左右报错

您好,这个192.168.1.220 是本地ip还是服务器ip呀?或者是什么?
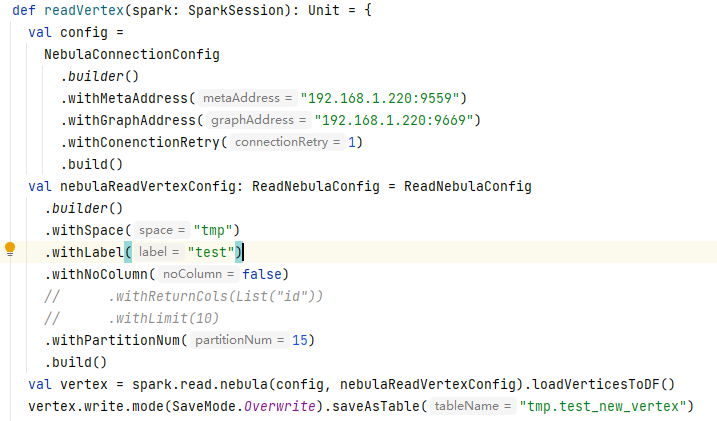
贴一下更多日志吧,你是直接跑example吗,你要先确保你的NebulaGraph中有tmp这个space,并且有test这个tag
这个是NebulaGraph meta服务所在的机器ip
space与tag都是有的,代码读取少量进行点进行展示是没问题的,点总量有7千万左右,读出1千3百万左右就会报错 spark版本 2.4.8 nebula 2.0.1
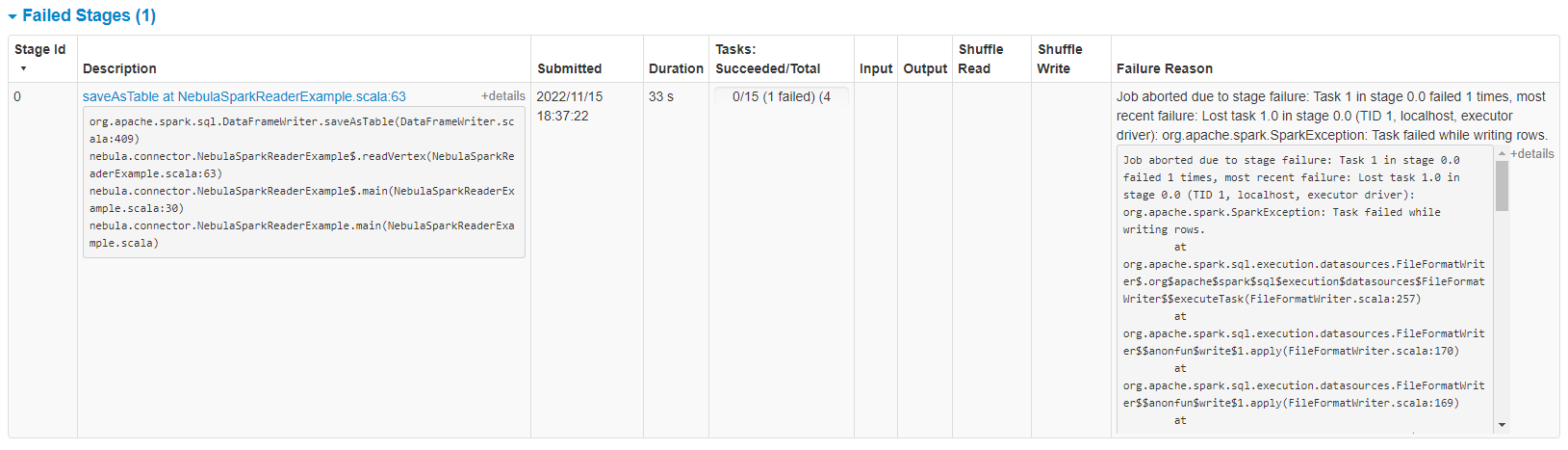
这个是报错日志
java.util.NoSuchElementException: Unable to activate object
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:400)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:277)
at com.vesoft.nebula.client.storage.StorageConnPool.getStorageConnection(StorageConnPool.java:42)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.lambda$next$0(ScanVertexResultIterator.java:81)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.facebook.thrift.transport.TTransportException: java.net.BindException: Address already in use: connect
at com.facebook.thrift.transport.TSocket.open(TSocket.java:204)
at com.vesoft.nebula.client.storage.GraphStorageConnection.open(GraphStorageConnection.java:40)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:59)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:16)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:391)
... 8 more
Caused by: java.net.BindException: Address already in use: connect
at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method)
at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:85)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at com.facebook.thrift.transport.TSocket.open(TSocket.java:199)
... 12 more
22/11/16 14:56:35 ERROR ScanVertexResultIterator: get storage client error,
java.util.NoSuchElementException: Unable to activate object
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:400)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:277)
at com.vesoft.nebula.client.storage.StorageConnPool.getStorageConnection(StorageConnPool.java:42)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.lambda$next$0(ScanVertexResultIterator.java:81)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.facebook.thrift.transport.TTransportException: java.net.BindException: Address already in use: connect
at com.facebook.thrift.transport.TSocket.open(TSocket.java:204)
at com.vesoft.nebula.client.storage.GraphStorageConnection.open(GraphStorageConnection.java:40)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:59)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:16)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:391)
... 8 more
Caused by: java.net.BindException: Address already in use: connect
at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method)
at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:85)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at com.facebook.thrift.transport.TSocket.open(TSocket.java:199)
... 12 more
22/11/16 14:56:35 ERROR ScanVertexResultIterator: get storage client error,
java.util.NoSuchElementException: Unable to activate object
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:400)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:277)
at com.vesoft.nebula.client.storage.StorageConnPool.getStorageConnection(StorageConnPool.java:42)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.lambda$next$0(ScanVertexResultIterator.java:81)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.facebook.thrift.transport.TTransportException: java.net.BindException: Address already in use: connect
at com.facebook.thrift.transport.TSocket.open(TSocket.java:204)
at com.vesoft.nebula.client.storage.GraphStorageConnection.open(GraphStorageConnection.java:40)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:59)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:16)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:391)
... 8 more
Caused by: java.net.BindException: Address already in use: connect
at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method)
at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:85)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at com.facebook.thrift.transport.TSocket.open(TSocket.java:199)
... 12 more
22/11/16 14:56:35 ERROR Utils: Aborting task
com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message: Unable to activate object
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:99)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:133)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:67)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:244)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:248)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:170)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
22/11/16 14:56:35 ERROR ScanVertexResultIterator: get storage client error,
java.util.NoSuchElementException: Unable to activate object
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:400)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:277)
at com.vesoft.nebula.client.storage.StorageConnPool.getStorageConnection(StorageConnPool.java:42)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.lambda$next$0(ScanVertexResultIterator.java:81)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.facebook.thrift.transport.TTransportException: java.net.BindException: Address already in use: connect
at com.facebook.thrift.transport.TSocket.open(TSocket.java:204)
at com.vesoft.nebula.client.storage.GraphStorageConnection.open(GraphStorageConnection.java:40)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:59)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:16)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:391)
... 8 more
Caused by: java.net.BindException: Address already in use: connect
at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method)
at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:85)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at com.facebook.thrift.transport.TSocket.open(TSocket.java:199)
... 12 more
22/11/16 14:56:35 ERROR Utils: Aborting task
com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message: Unable to activate object
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:99)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:133)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:67)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:244)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:248)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:170)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
22/11/16 14:56:35 ERROR Utils: Aborting task
com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message: Unable to activate object
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:99)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:133)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:67)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:244)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:248)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:170)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
22/11/16 14:56:35 ERROR Utils: Aborting task
com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message: Unable to activate object
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:99)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:133)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:67)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:244)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:248)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:170)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
22/11/16 14:56:37 ERROR FileFormatWriter: Job job_20221116145607_0000 aborted.
22/11/16 14:56:37 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
org.apache.spark.SparkException: Task failed while writing rows.
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:257)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:170)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message: Unable to activate object
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:99)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:133)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:67)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:244)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:248)
... 10 more
22/11/16 14:56:37 ERROR TaskSetManager: Task 0 in stage 0.0 failed 1 times; aborting job
22/11/16 14:56:37 ERROR FileFormatWriter: Aborting job b8624997-431c-4009-836f-1d572bd4f076.
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0, localhost, executor driver): org.apache.spark.SparkException: Task failed while writing rows.
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:257)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:170)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message: Unable to activate object
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:99)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:133)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:67)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:244)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:248)
... 10 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1889)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1877)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1876)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1876)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:926)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:926)
at scala.Option.foreach(Option.scala:245)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:926)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2110)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2059)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2048)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:737)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:167)
at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:159)
at org.apache.spark.sql.execution.datasources.DataSource.writeAndRead(DataSource.scala:503)
at org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand.saveDataIntoTable(createDataSourceTables.scala:217)
at org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand.run(createDataSourceTables.scala:176)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:104)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:122)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.createTable(DataFrameWriter.scala:474)
at org.apache.spark.sql.DataFrameWriter.saveAsTable(DataFrameWriter.scala:453)
at org.apache.spark.sql.DataFrameWriter.saveAsTable(DataFrameWriter.scala:409)
at nebula.connector.NebulaSparkReaderExample$.readVertex(NebulaSparkReaderExample.scala:57)
at nebula.connector.NebulaSparkReaderExample$.main(NebulaSparkReaderExample.scala:30)
at nebula.connector.NebulaSparkReaderExample.main(NebulaSparkReaderExample.scala)
Caused by: org.apache.spark.SparkException: Task failed while writing rows.
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:257)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:170)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message: Unable to activate object
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:99)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:133)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:67)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:244)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:248)
... 10 more
Exception in thread "main" org.apache.spark.SparkException: Job aborted.
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:198)
at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:159)
at org.apache.spark.sql.execution.datasources.DataSource.writeAndRead(DataSource.scala:503)
at org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand.saveDataIntoTable(createDataSourceTables.scala:217)
at org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand.run(createDataSourceTables.scala:176)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:104)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:122)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.createTable(DataFrameWriter.scala:474)
at org.apache.spark.sql.DataFrameWriter.saveAsTable(DataFrameWriter.scala:453)
at org.apache.spark.sql.DataFrameWriter.saveAsTable(DataFrameWriter.scala:409)
at nebula.connector.NebulaSparkReaderExample$.readVertex(NebulaSparkReaderExample.scala:57)
at nebula.connector.NebulaSparkReaderExample$.main(NebulaSparkReaderExample.scala:30)
at nebula.connector.NebulaSparkReaderExample.main(NebulaSparkReaderExample.scala)
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0, localhost, executor driver): org.apache.spark.SparkException: Task failed while writing rows.
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:257)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:170)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message: Unable to activate object
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:99)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:133)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:67)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:244)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:248)
... 10 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1889)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1877)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1876)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1876)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:926)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:926)
at scala.Option.foreach(Option.scala:245)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:926)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2110)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2059)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2048)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:737)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:167)
... 27 more
Caused by: org.apache.spark.SparkException: Task failed while writing rows.
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:257)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:170)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message: Unable to activate object
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:99)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:133)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:67)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:244)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:248)
... 10 more
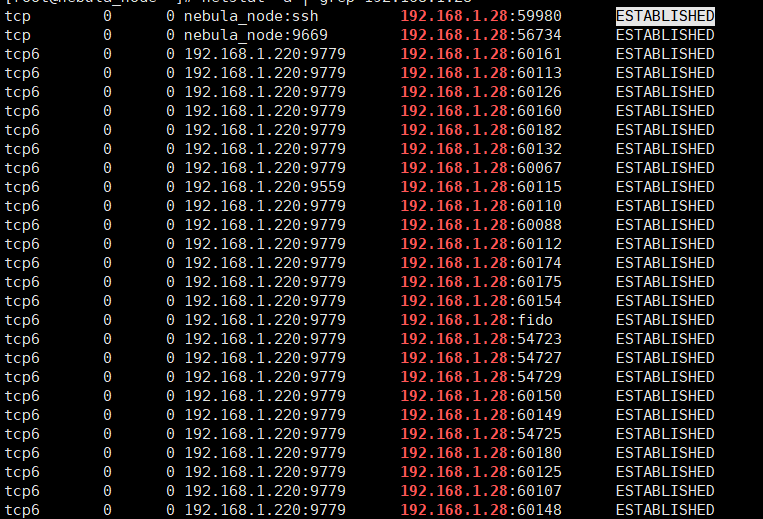
你用netstat -a查看下是否有TIME_WAIT的连接,如果是的话 可以修改下系统支持的tcp连接数。
https://customer.precisely.com/s/article/Error-java-net-BindException-Address-already-in-use-connect-in-EngageOne-Vault?language=en_US
查了一下没有TIME_WAIT的连接
established 连接数有多少,space有多少个partition?看看是正常的连接去读取数据 还是存在泄漏
您好,这个读取错误怎么解决呀,我也遇到了,也发了帖子,暂时没有人回复呢
如果堆栈一样,那你贴一下下下面的的信息
问题解决了,服务端的tcp连接数量没有问题,我是用idea在本地跑的代码,把本机的tcp连接数量调高 65535,把tcp连接保留时间调短 30s,然后就可以正常读取了
如果报错一致的话可以试着调大一下本机的最大tcp连接数量
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。