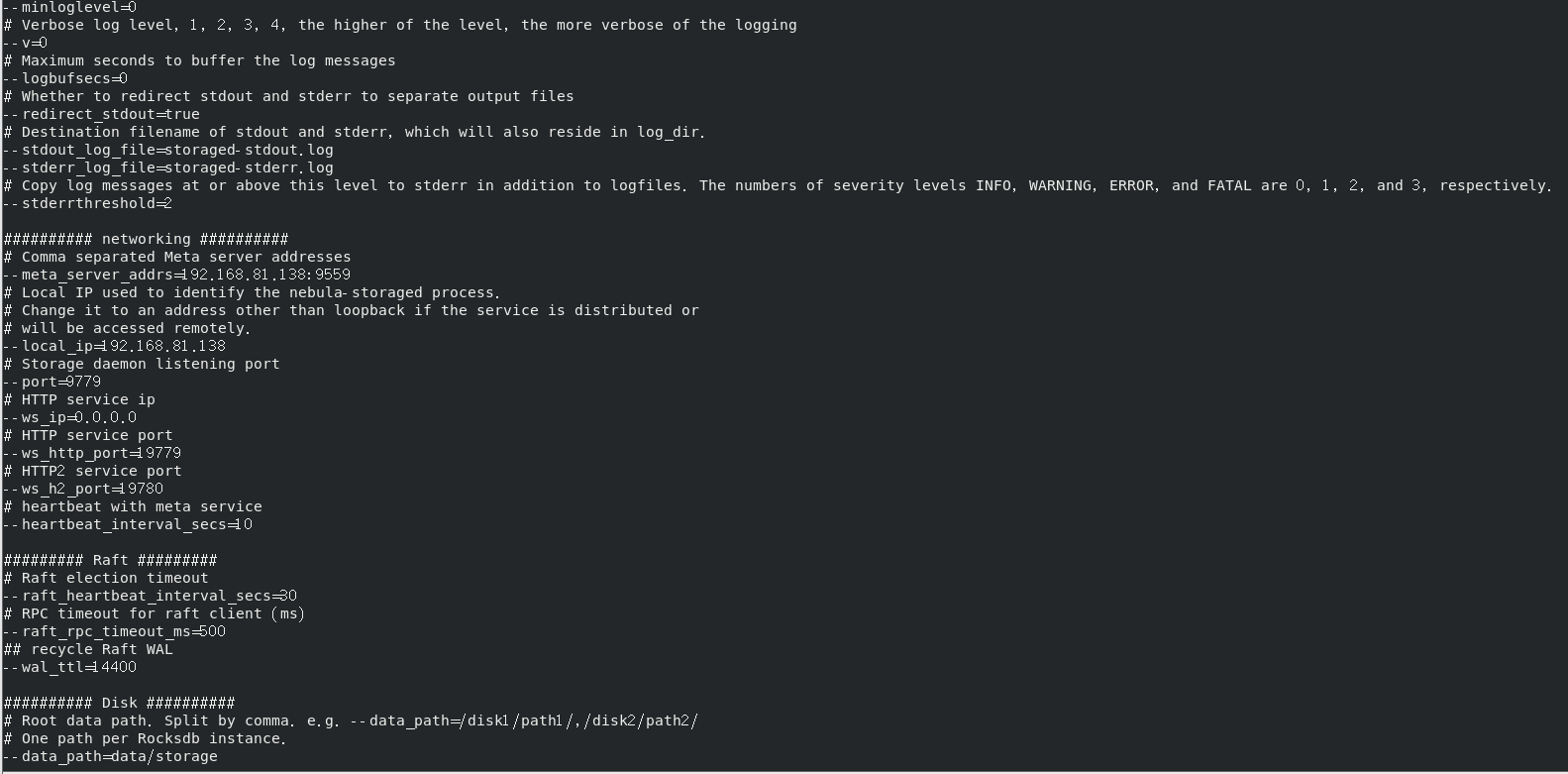
- nebula 版本:(为节省回复者核对版本信息的时间,首次发帖的版本信息记得以截图形式展示)
- 部署方式:单机
- 安装方式:源码编译
- 是否为线上版本:Y / N
- 硬件信息
- 磁盘( 推荐使用 SSD)
- CPU、内存信息
- 问题的具体描述
ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
22/11/16 22:12:15 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
22/11/16 22:12:16 INFO NebulaVertexPartitionReader: partition index: 1, scanParts: List(1, 11, 21, 31, 41, 51, 61, 71, 81, 91)
22/11/16 22:12:16 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message:
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:95)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:141)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:66)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$11$$anon$1.hasNext(WholeStageCodegenExec.scala:619)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:255)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:247)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$24.apply(RDD.scala:836)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$24.apply(RDD.scala:836)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:402)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:408)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
22/11/16 22:12:16 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, localhost, executor driver): com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message:
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:95)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:141)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:66)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
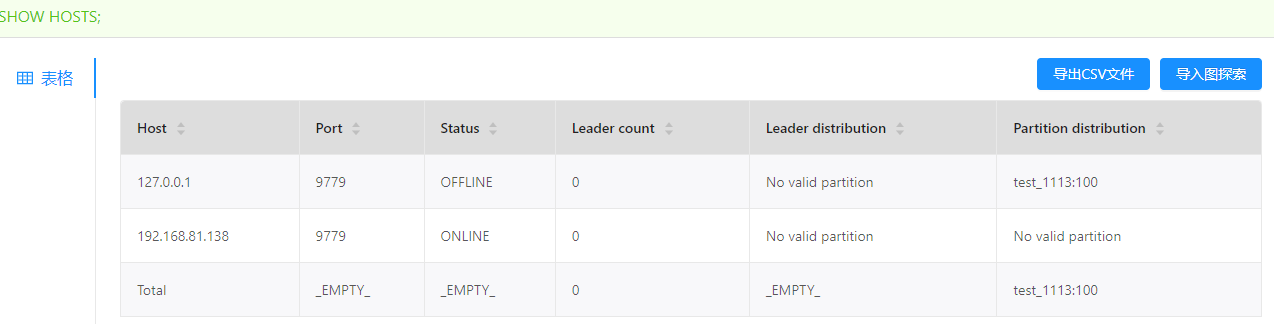
storaged配置