- nebula 版本:3.1
- 部署方式:分布式
- 安装方式: RPM
- 是否为线上版本:Y
- 硬件信息
- 磁盘 SSD
- CPU、内存信息
- 版本信息:
- nebula-spark-connector-3.0.0.jar
- pyspark:2.4.0
问题的具体描述
sessions会话没有自动释放:
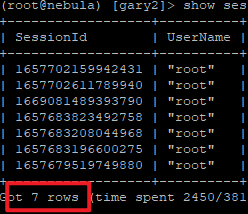
使用nebula-spark-connector写入数据后,session没有自动释放,只能等待过期时间,具体的option见下图。每当执行一次write,就会多一个session(3次vertex1次edge)。
此前出现过session达到上限,才做的这次验证。请问下,是不是配置少了什么东西,有什么可靠的解决方法吗。
- 写入前:
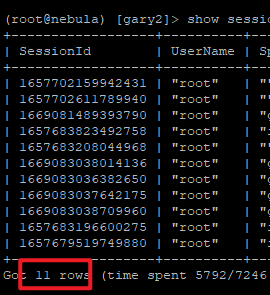
- 写入后:
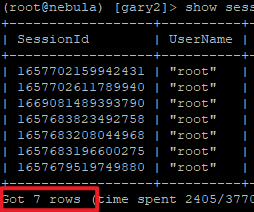
- 10分钟后自动过期(nebula-graphd.conf设定成10分钟):
代码
df.write.format("com.vesoft.nebula.connector.NebulaDataSource") \
.option("type", "vertex") \
.option("spaceName", "XXX") \
.option("label", 'tag_name') \
.option("vidPolicy", "") \
.option("vertexField", 'vid_field_name') \
.option("writeMode", "insert") \
.option("batch", 512) \
.option("metaAddress", "192.XXX.XXX.XXX:9559,192.XXX.XXX.XXX:9559,192.XXX.XXX.XXX:9559") \
.option("graphAddress", "192.XXX.XXX.XXX:9669,192.XXX.XXX.XXX:9669,192.XXX.XXX.XXX:9669") \
.option("passwd", "XXX") \
.option("user", "root") \
.save()
df.write.format("com.vesoft.nebula.connector.NebulaDataSource") \
.mode("overwrite") \
.option("srcPolicy", "") \
.option("dstPolicy", "") \
.option("rankFiled", "") \
.option("metaAddress", "192.XXX.XXX.XXX:9559,192.XXX.XXX.XXX:9559,192.XXX.XXX.XXX:9559") \
.option("graphAddress", "192.XXX.XXX.XXX:9669,192.XXX.XXX.XXX:9669,192.XXX.XXX.XXX:9669") \
.option("user", "root") \
.option("passwd", "XXX") \
.option("type", "edge") \
.option("spaceName", "XXX") \
.option("label", 'edge_name') \
.option("srcVertexField", 'src_id_name') \
.option("dstVertexField", 'dst_vid_name') \
.option("rankField", "") \
.option("batch", 512) \
.option("writeMode", "insert").save()