各位前辈,我想请教下,如何用python读取nebula graph的数据,然后利用louvain或leiden算法做个简单的社区分割呢?
你可以用 python graphd-client query 全图,然后 cast 成 df 转到 networkx/igraph 去计算
from nebula3.gclient.net import ConnectionPool
from nebula3.Config import Config
import pandas as pd
from typing import Dict
from nebula3.data.ResultSet import ResultSet
def result_to_df(result: ResultSet) -> pd.DataFrame:
"""
build list for each column, and transform to dataframe
"""
assert result.is_succeeded()
columns = result.keys()
d: Dict[str, list] = {}
for col_num in range(result.col_size()):
col_name = columns[col_num]
col_list = result.column_values(col_name)
d[col_name] = [x.cast() for x in col_list]
return pd.DataFrame.from_dict(d, columns=columns)
# define a config
config = Config()
# init connection pool
connection_pool = ConnectionPool()
# if the given servers are ok, return true, else return false
ok = connection_pool.init([('127.0.0.1', 9669)], config)
# option 2 with session_context, session will be released automatically
with connection_pool.session_context('root', 'nebula') as session:
session.execute('USE <your graph space>')
result = session.execute('<your query>')
# <your query> 可以是这样的 MATCH ()-[e:follow]->() RETURN src(e), dst(e), e.degree LIMIT 10000
df = result_to_df(result)
print(df)
你也可以用 python storage-client 扫全图,然后用你喜欢的库比如 networkx/igraph 去算,单机很方便
区别是这个扫数据不占用 graphd 内存,绕过它直接扫底层
扫全图参考
- https://github.com/vesoft-inc/nebula-python/tree/master/example
- https://www.siwei.io/nebula-python-storage-docker-guide/
或者你可以用 pyspark + Nebula_algorithm 去搞,如果pyspark 也算 python 的话,这个的好处是算 louvain 能在超出一台机器的能力上算
这个真没必要
绕弯一点,你甚至可以用我做的 nebula-dgl 去得到图的 dgl 对象,然后存成 networkx 的对象(这个其实没必要,太绕了)
1 个赞
特别感谢!
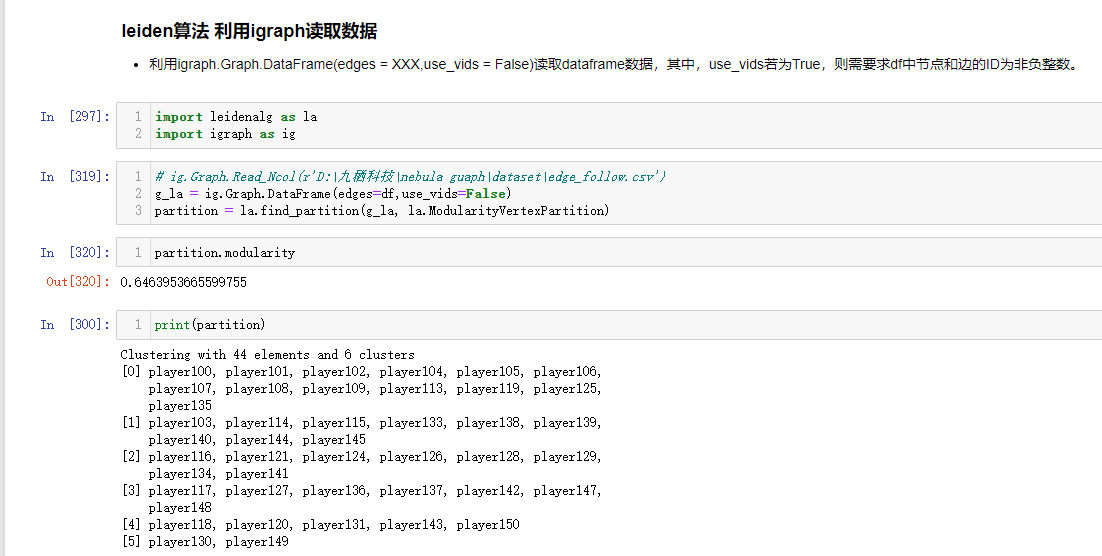
我现在利用python读取了nebula graph的数据,并且调包实现了louvain和leiden社区发现,请问如何将社区划分结果应用回nebula graph呢?最好在nebula graph能可视化展示。
1 个赞
你可以自己攒语句,把 cluster_id 结果作为 某一个 tag 下的 property 写到 NebulaGraph,也可以把结果导出为 csv,利用 nebula-importer 搞。
搞进去了就可以用 nebulagraph 可视化工具展示了。
- 针对您说的第一种方法,给tag增加一个claster_id属性,然后插入对应的值写到nebulagraph。我这么做是否可以呢:
先增加cluster_id:“ALTER TAG player ADD (cluster_id int);”
然后针对不同点,给cluster_id写入不同值:“INSERT VERTEX player (cluster_id) VALUES “player100”:(0), “player101”:(0),“player102”:(0),“player103”:(1); ”… - 针对您说的第二种方法,是指将分区后的partition导出为csv吗?然后给player这个节点的csv,增加个cluster_id属性,并根据partition的值写入进去,最后导入nebulagraph,对吧?
不好意思,由于刚接触这个,可能问的问题比较繁琐,感谢您!
理论上可以的,不过要注意,如果你用 insert,需要把 player 上其他的属性写全,否则可以用 UPDATE 语句哈(只写增加的属性),另外,你这么 bulk 的单个语句写多个是对的,但是要注意,单行语句长度有上限,好像是2048还是多少来的,你可以分成多条哈(比如每条 512 个点之类的)
https://github.com/vesoft-inc/nebula-importer/ 就是一个 go 写的工具,从 csv 里读取插入的数据需要的字段,每行是一个,比如你的csv 可以是这种的 player.csv:
player101,38,Tim Duncan,cluster_0
player102,32,Lao Zhang,cluster_0
Importer 的 yaml 配置文件里告诉他 player.csv 里第0列是 tag player 的 vid,第1列是 player.age 第2列是 player.name 第3列是 player.cluster_id 哈。
数据量大了还有另一个工具叫 nebula exchange,你可以去文档里了解哈。
Importer 不支持 update 只支持 insert,感觉其实不太适合,感觉你直接用 python graphclient 去攒 update 语句比较好。
1 个赞
您好,我将insert换为了update,如下所示

这样一个个添加属性,有点麻烦,如果是上万的数据集,就只能用Importer了吧?
另外,我给每一个节点加完cluster_id属性值后,如何可视化显示出来呢?
确实,update 语句不支持 bulk 一行多条。不过 importer 应该是没有区别的哈。
如果能用 insert(没有其他属性的话,insert 可以一行多条哈)
明白 谢谢
我刚看了 我们部署的studio是v3.4.0版本的。
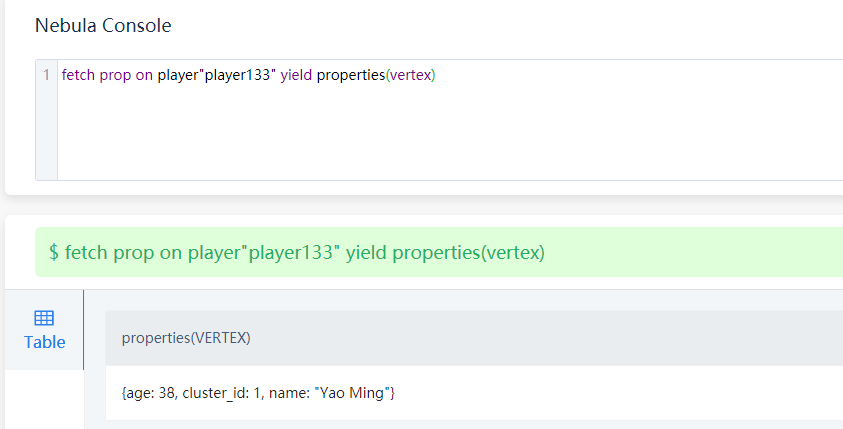
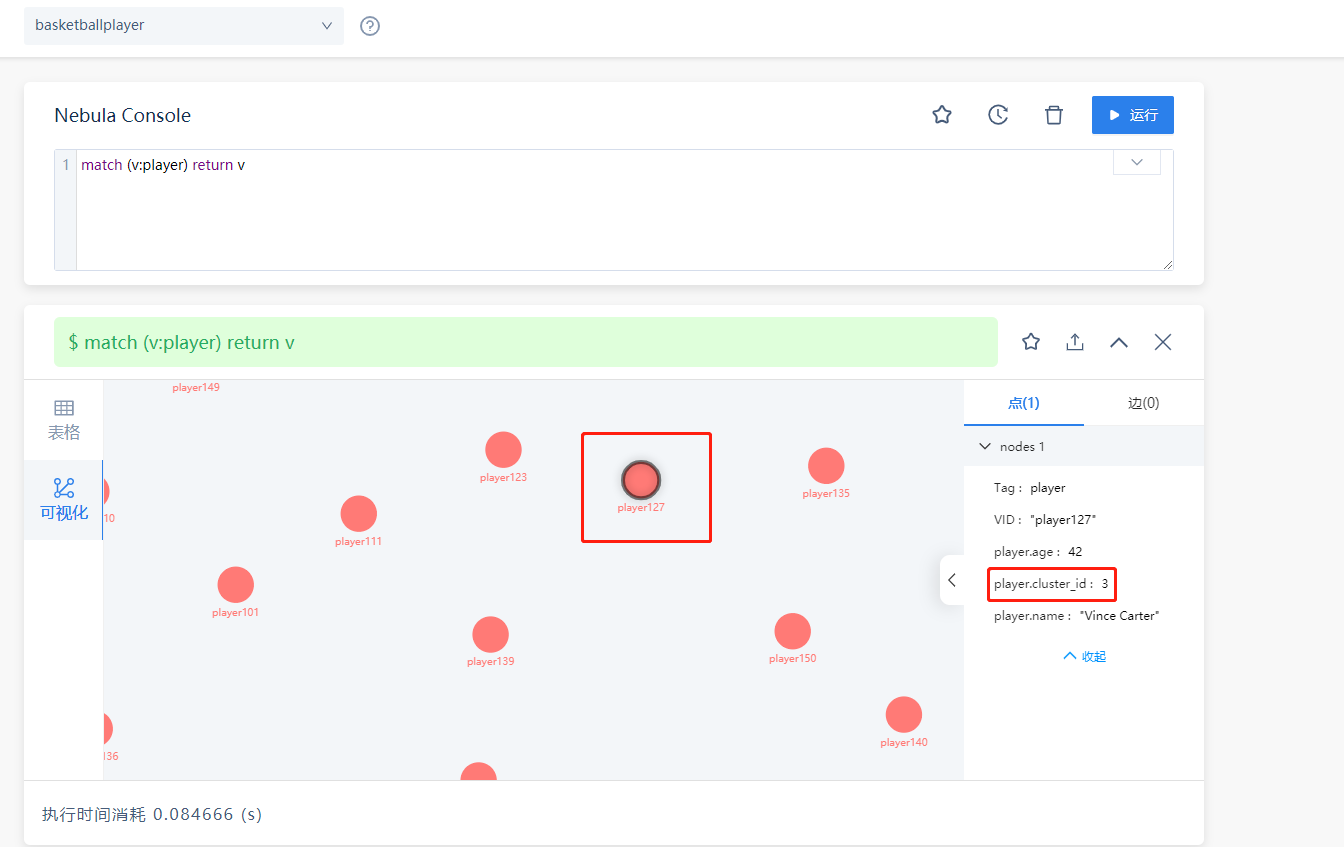
我现在想要看某个节点在哪个社区的话,只能靠 fetch prop on player"playerXXX" yield properties(vertex),去查询它的cluster_id属性,或者在可视化中点击某个节点看它的属性。如下:
有没有什么方法能够让所有节点根据cluster_id属性,聚类成不同的簇呢?类似下面这样的:
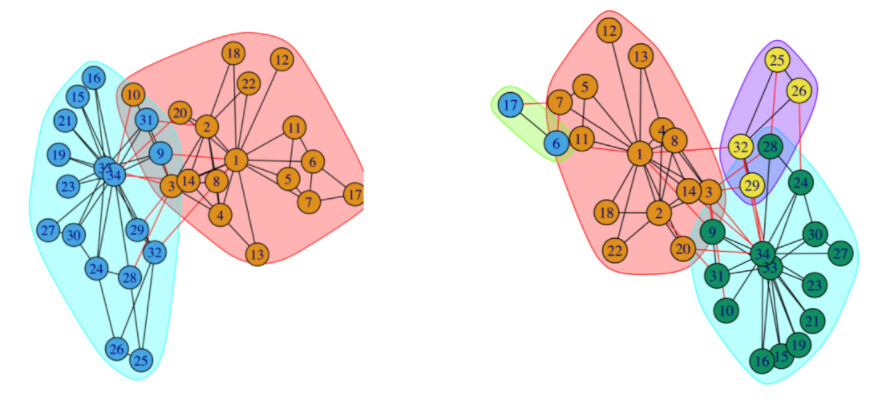
Explorer 里可以在浏览器上直接运行社区识别,按照社区染色
Studio 3.2.5 版本你可以分别返回不同 cluster_id 的点和他们的边,然后手动设定颜色
Studio 3.3+ 的可视化确实不行了,染色就是根据 TAG 做的。
你只能想办法用 networkx 之类的方式去 plot 了![]()
1 个赞
好的 谢谢!
OK 我现在就弄下 ![]()
1 个赞
![]() 谢谢啦
谢谢啦
666哇!用pyspark调用algorithm的话 这样就方便多了啊
发文章了我要去看看 ![]()
2 个赞