
本文首发于 DataFunTalk 公众号,授权 NebulaGraph 社区转发。原文出处:https://mp.weixin.qq.com/s/opUSv68huVn0qznkCHJZBQ
导读:本文将分享图算法在风控中的应用。
今天的介绍会围绕下面四点展开:
- 图算法和风控简介
- 图算法在风控的演化
- 相应平台的心得
- 展望未来
分享嘉宾|汪浩然,互联网行业资深风控和图计算专家。
图算法和风控简介
什么是图算法——图论算法
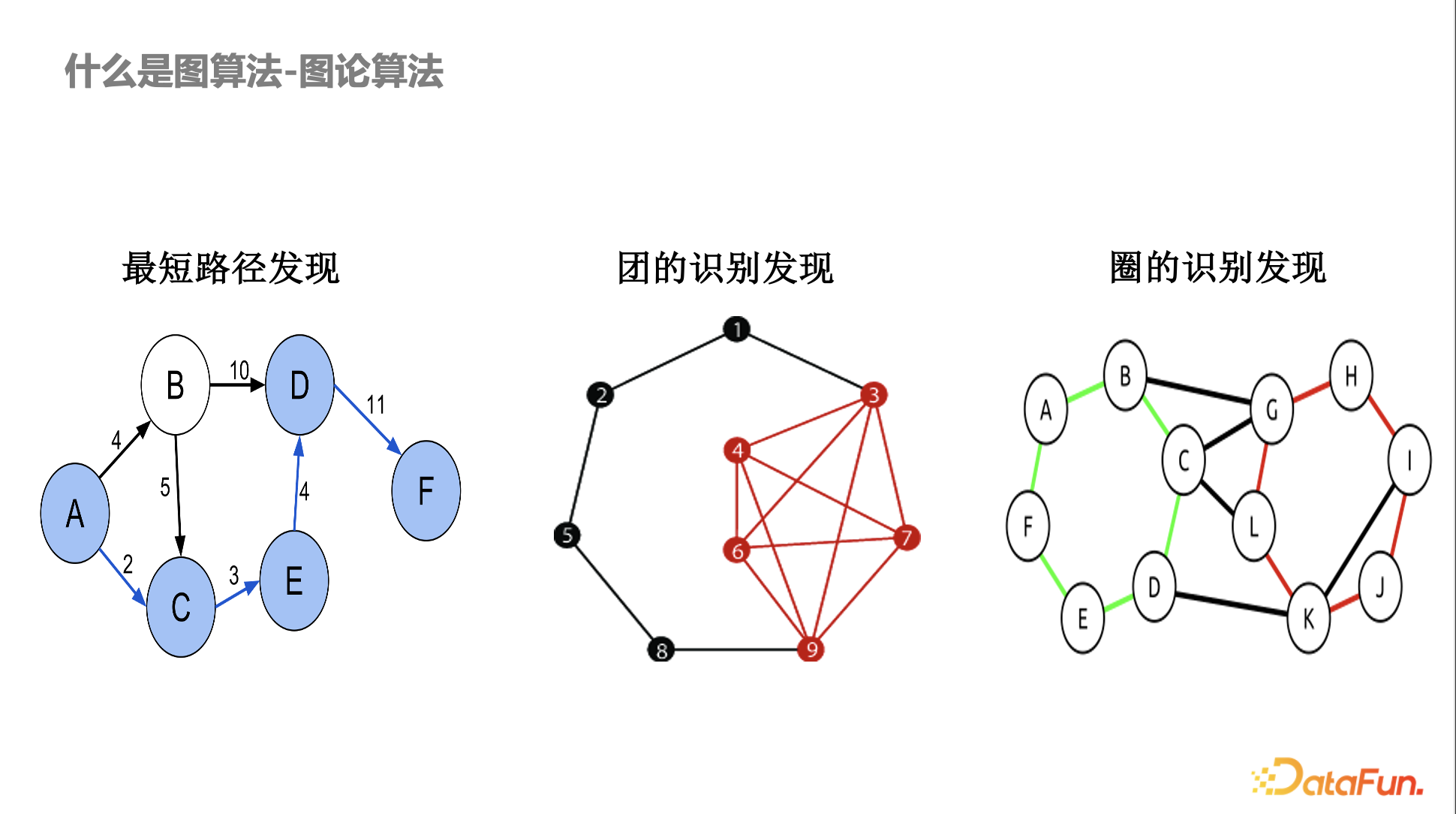
图算法最早来源于图论和组合优化相关算法,在风控里面应用比较多的基本上都是传统的图算法或比较偏数学理论的算法,如最短路径发现,不同的账号和交易之间存在异常的最短路径,某些账号或设备存在异常的关联。另外,还有图的识别,比如洗钱,会涉及到异常的环路。
早期图在风控的应用都是基于明确的数学结构定义,如果大家仔细研究这些算法,会发现有的算法是多项式时间可以解决的,有些是多项式时间无法解决的,比如 NP-hard 问题。在团或圈的发现算法中,其实会用到一些近似算法。而且风控中有意思的一点是数学上定义得越严格,黑产绕过就越容易。比如黑产知道你的目的是发现团,他会故意某几个设备少一两条边,那数学严格的定义就很容易被绕过。
什么是图算法——图机器学习
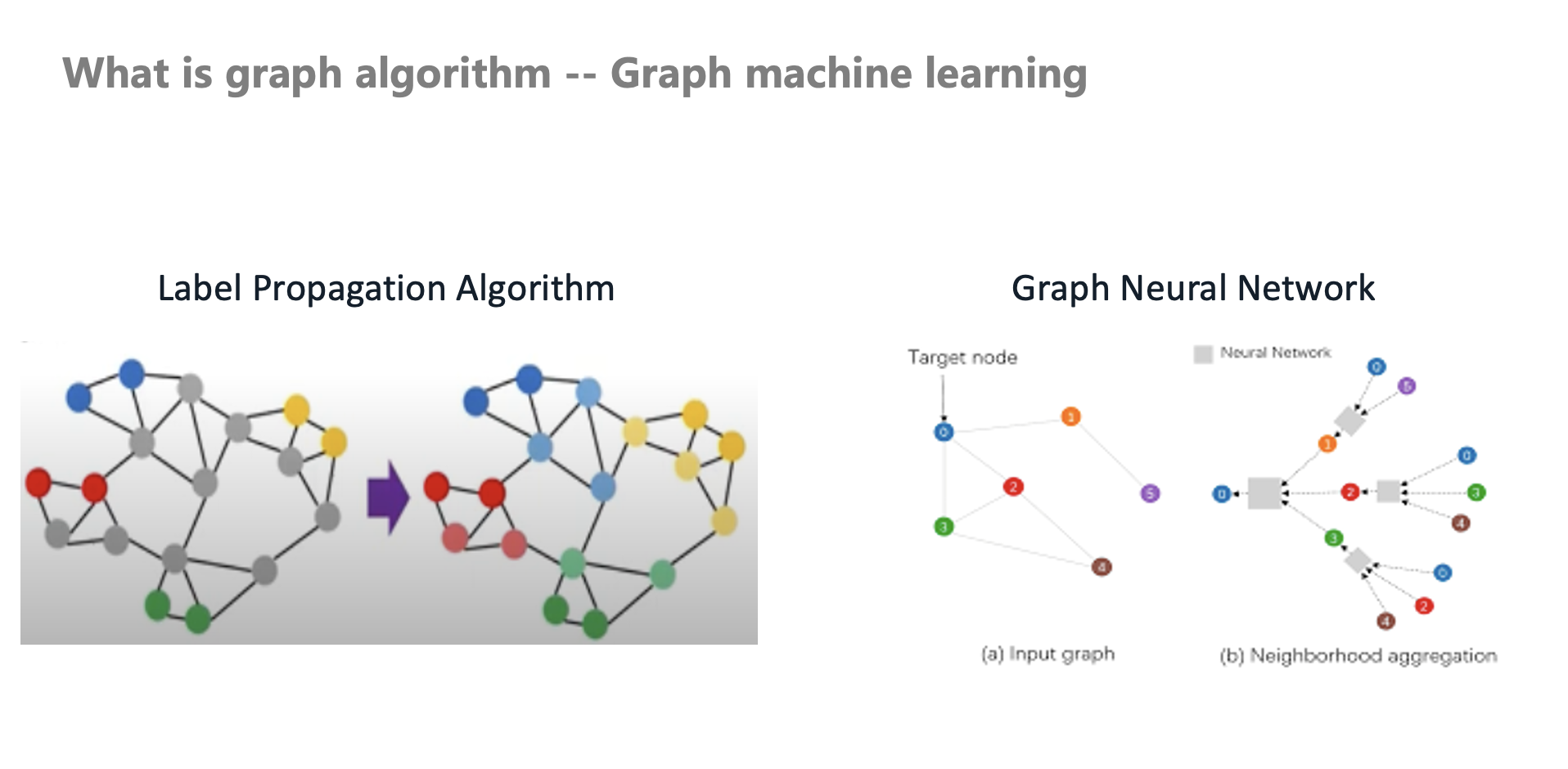
早期业内是直接应用这套传统图算法到风控中,随着技术的发展,图机器学习也开始应用在风控中。比如早期本人在交易场景中落地了一个标签传播算法,它是一个 Transudative 推演式的算法(非归纳式)。
在现实应用中,很多时候我们没有办法对黑白灰样本去做完全精确的定位。那该如何利用类似社交网络的同质性(好人和好人关系近,坏人和坏人关系近)做团伙识别?在风控场景,很容易通过强规则产出高准确率的样本,但覆盖率很低(低召回),那么如何扩充这些样本呢?
此时标签传播算法和半监督技术就开始在风控中使用。图神经网络的半监督学习,其学习能力和鲁棒性高于传统图算法。有别于传统的图算法的自定义 Aggregate 和 Message Passing,随着图神经网络的发展,也越来越多的应用到风控场景。
什么是图算法——图挖掘算法

风控场景中使用到很多图挖掘算法,如:
- 高密度子图,一些异常账号和异常行为对象之间会存在高密度子图。
- 邻居域异常,异常节点、边、网络存在异常的形状(如星形散射状),即该账户的邻居域异常。
- 复杂网络,比如异常网络的度分布和正常网络的度分布是不同的。如有时挖掘了一些团伙,可以基于 Degree Sequence 构建特征和模型。不同 Degree Sequence 分布的网络存在不同的特性,这可以指导我们进一步构建拓扑相关特征。
什么是风控

上图中的台词很好地概括了风控的工作,“人活一世,有的人成了面子,有的人成了里子,都是时势使然”。从事金融风控、交易风控,风控规则和算法是公司的核心竞争力,都需要保密。有很多精彩的算法及落地不方便出来交流,可能很少有人知道,但这都成了里子。风控同学也是甘于寂寞,不断地去进行各种对抗,同时也在钻研技术和业务。
互联网风控干什么

众所周知的羊毛党薅羊毛、账户被盗、盗卡、现金贷、“以贷养贷”、猫池、恶意退货、物流空包、各种各样的诈骗、杀猪盘等等,这些场景都属于互联网风控范畴。
图算法和风控的相遇

为什么图算法和风控会相遇?黑产作案存在团伙性,一个人不可能靠一个账户就去作案,更多的时候需要多人多账户的协同。
团伙特性就会使黑产之间产生关联,这就引入了图算法。作案有相似性,但案件和作案人之间可能没有物理和空间关联,但在某些角度他们存在相似性(如行为)。风控也可以通过除了直接的关系外的点和点之间的相似性构造边。因为作案有相似性,这也是网络可以存在的一个条件。
还有一个原因是作案需要大量的账号和设备资源的配合,利益的驱动就会让黑产做更多的事情。作案需要成本,如手机、账号等。物以类聚,人以群分(同质性)。
以上这些就是图算法和风控相遇的原因。
图算法在风控的演化
几个核心趋势

早年间风控尤其是风控策略,更多的是一个 Rule Writer。通过业务理解写规则,慢慢演化成算法模型。还有从经典一阶的 Velocity 变量变成了 Neutral Net Aggregator(后面会细讲)。传统的风控算法或规则只能看到相邻点的特征,现在可以通过神经网络计算 Aggregator。这也是从数学严格定义的网络结构到图神经网络、Strict Definition 到概率化的推断的演进过程。
本人曾请教过图灵奖得主 John Hopcroft,他在图的匹配还有自动机方面做了很多工作。当时问他,传统的图算法的研究对现在的人工智能有没有什么帮助?首先他觉得是没有的(可能是谦虚),他谈到一个非常大的趋势,过去大部分都是严格数学的定义,以后会更偏向概率推断。这个趋势也很契合风控,数学上定义得越严格,越容易被黑产攻克。使用机器学习、图神经网络去进行学习,最终就是变成了一个概率的推断。
经典一阶的 Velocity 变量
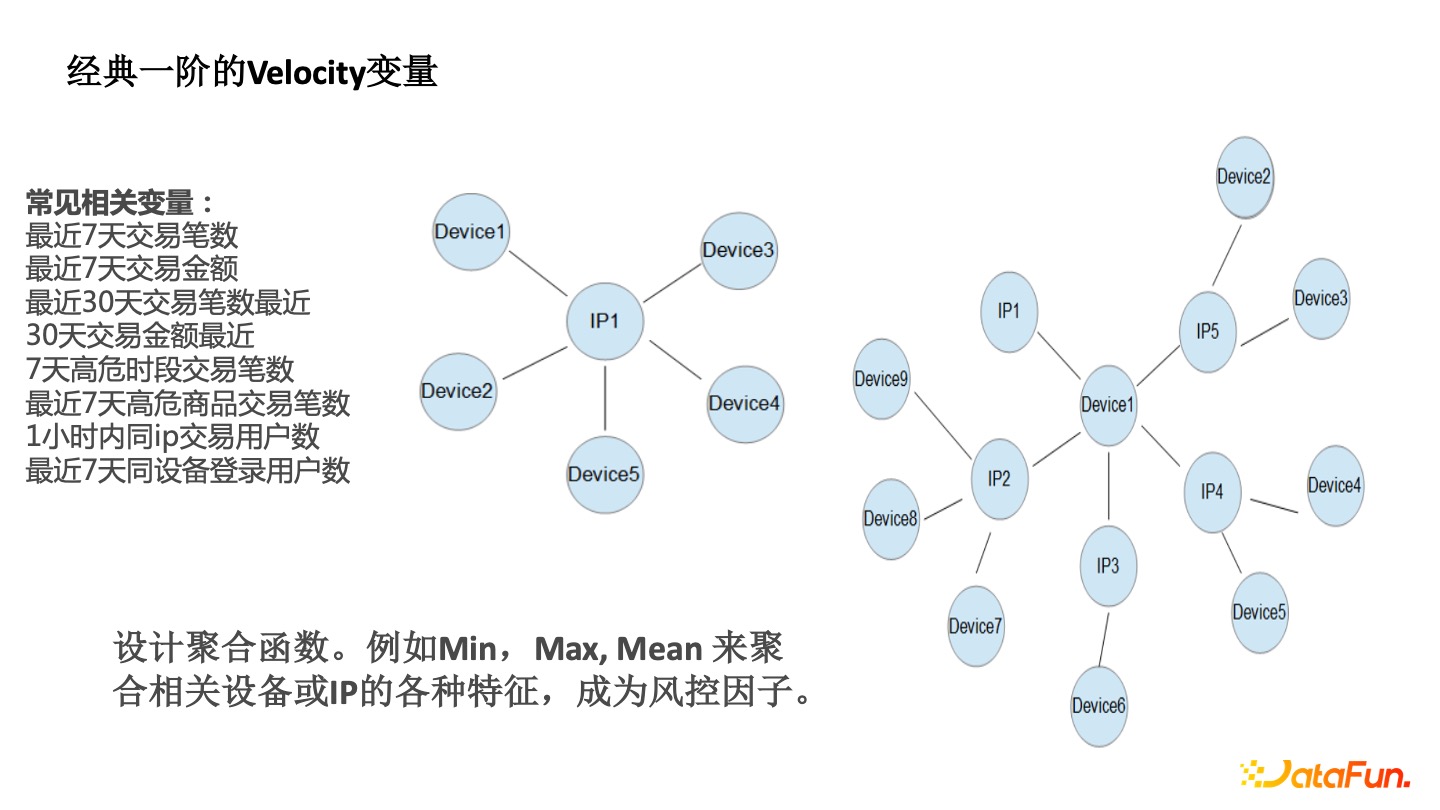
传统的一阶 Velocity 能看到一个 IP 周围有很多的 Device 。要评估该IP 的风险,可以观察其相邻的 Device 的风险特征,如最近几天的交易登录统计,最近 7 天的交易笔数,一小时内同 IP 的交易用户数等,这些都属于一阶 Velocity。
以前风控从业者相当于人工构建了图神经网络的 Aggregate 函数(Min、Max、Mean)。
- Min 函数,比如该 IP 周围 Device 注册的最小时间,如设备注册最小时间都是最近的,即新设备,那么该 IP 存在很大的风险。
- Max 函数,如设备上的最大的账户数,多人共用单个设备也是异常。
- Mean 函数,如周围的设备平均的交易数。之前风控从业者通过手工去设计这个一阶的 Aggregate,通过图算法能从一阶到两阶。
神经网络的聚合
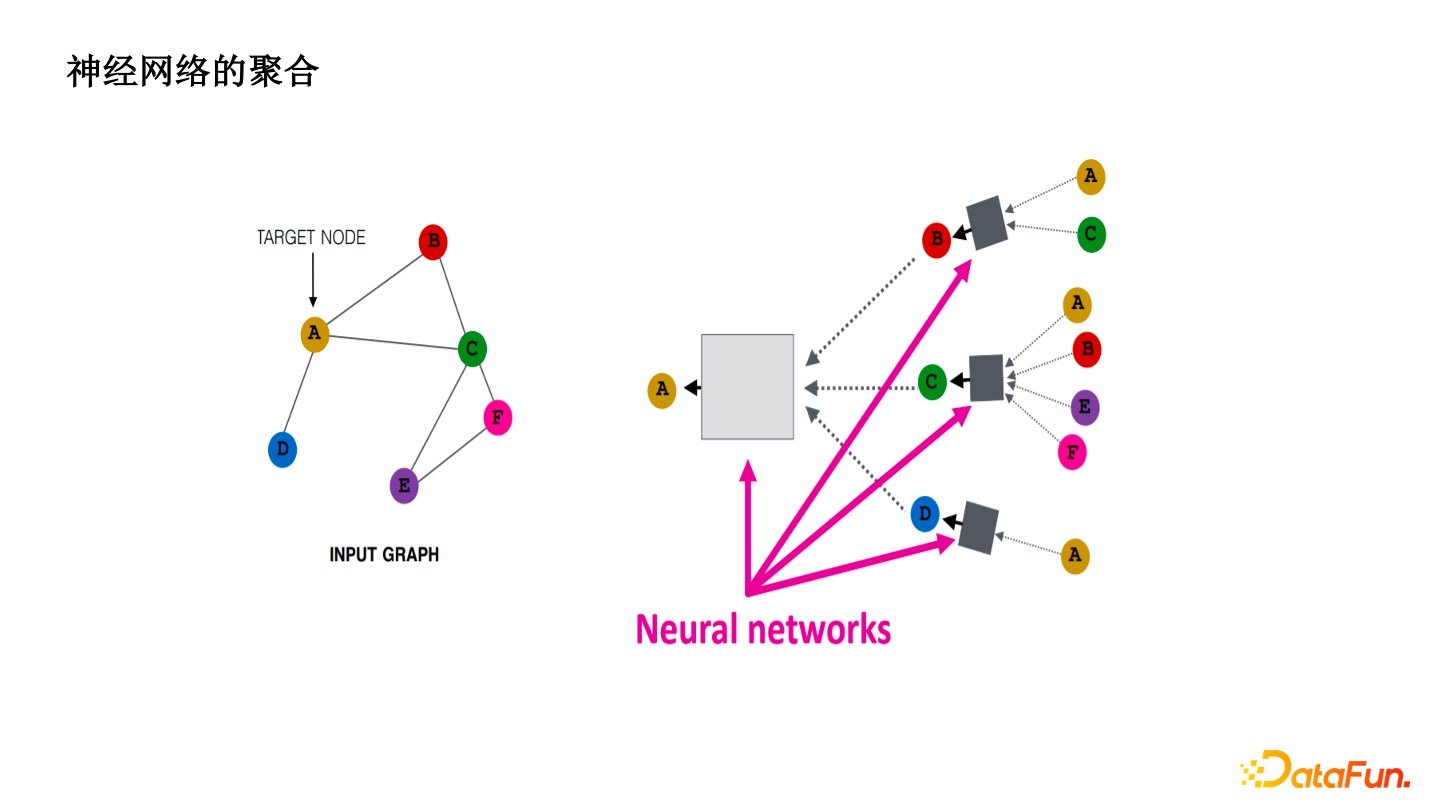
引入了神经网络以后,把一阶或者二阶的 Velocity 通过神经网络学习。让算法去学坏人的 Pattern 而不是手工地去归纳,增加了绕过成本和模型的鲁棒性。单纯的一阶的阈值很容易被黑产试出来,通过鲁棒性的 MLP 去预测,有明显的效果提升。
Aggregator 算子的突破

Aggregator 算子最核心的算法上的突破就是 Deepmind 实现的。它用了代数拓扑的概念,如一个节点的邻居有 N 个点,每个都只有一个特征,即 Size 是 N 的 Multi-Size,这时至少要 N 个 Aggregate 才能够避免入射的产生。从算法上来讲,GNN 如 GrapSAGE,Gat 等价于一阶的 WL-test,本质上转换成了同构图的问题。同构就是让不同的子图确实能够通过 Aggregate 函数不发生入射。
为解决这个问题,Deepmind 设计了一种新型的 Aggregator 算子, N 个 Moments 对应着 N 个 Aggregator 算子。后面加了一个 Scalers, 下面的 Sigma 相当于是整合度的总和。d 就是这个点的度,Alpha 是一个系数,Alpha 有 1 又有 -1。
在社交电商领域,基于人和人的推荐,有些商品实际上是适合刘耕宏这种度很大的人来推荐的,这时 Alpha=1。有些私密的商品适合你的闺蜜来向你推荐,此时 Alpha=-1。你们两个度都很小,但你们两个是有联系的,这样推荐商品转化率是很高的。
这些在社交电商的场景下去解释是很合理的。最终通过从一阶 Velocity 的规则到不同 Aggregate 聚合函数,再有 MLP,Scalers 对不同度的归一化,再去使用 MLP,形成了整体框架。
相应平台的心得
早期一些 Velocity 很简单,但是工程压力大。要保证不同的特征能对齐,还有时间窗口的计算也很复杂。比如风控的过程中,想实现时间衰减,昨天的累计和与今天的累计和加上不同的权重或者系数,都需要做很大的系统改造。我们需要站在更高的角度上去做风控的聚合算法和底层存储索引系统,否则就是打补丁模式。
其实,实现难度也不大,用 DGL 都可以很轻松地去实现这样的算子。
从算法角度来看,制约 GNN 学习能力的就是算子。不能变成另一种极端,复杂的框架和链路,用简单的算子。如果算子非常简单,就像四则混合运算,再怎么组合,再怎么搭积木,最后也就是四则混合运算,做不了微积分,又何谈更高阶的运算。
常用离线图算法框架——GraphX

早期尝试去做图的时候,主要是做图的最短路径,单机版很简单。在大厂数据量很大,会使用分布式的图学习。首先是思维的转变,传统的图算法,都是 Sequency 的结构,很少有迭代式或者分布式。在 Message Passing 的框架下,代表有阿里的 ODPS Graph、Spark GraphX,背后的框架都用的是谷歌的思想,第一次把图算法的思路转化成以点为中心,和周围的点去做通信。
数学家说这是一种 local算法,怎么通过 Local 的算法来产生一个全局的观测?当所有的点都在做 Local 的时候,就变成分布式了。
相对来说,阿里 ODPS Graph 实际上没有很复杂的设计,但是它保证了只要 Work 足够,总能算出结果。而且它是用 Java 开发,相对于 GraphX Scala 没有做太多的封装,可以自己去写一些底层的函数。在实际的使用中,它并没有很耗内存,GraphX 是非常耗内存的。如果要实现 Pre-K 框架这种 Message Passing 的传统图算法甚至图标签算法,ODPS Graph 是一个不错的选择。
腾讯高性能分布式图计算框架——Plato
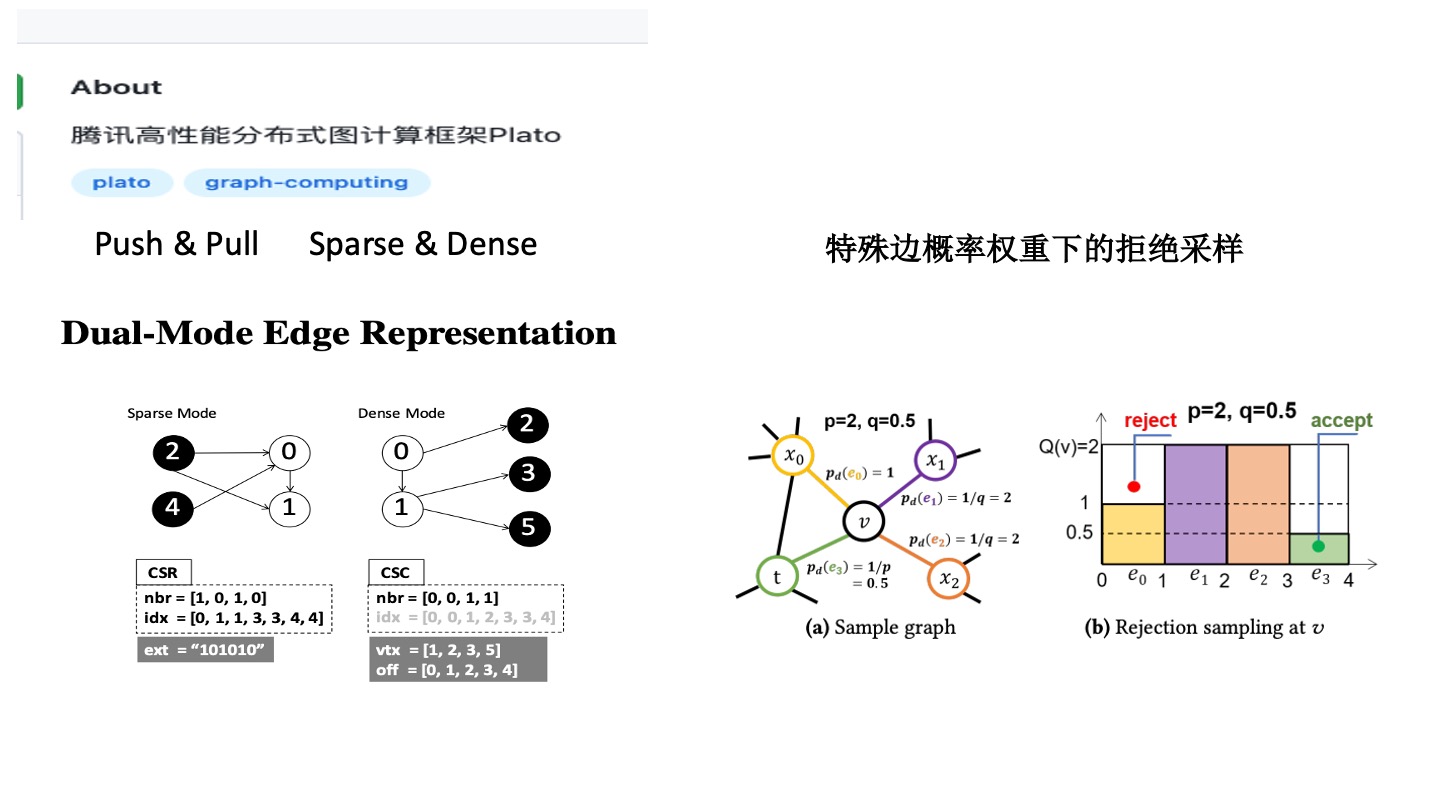
柏拉图是对于图论的算法以及 Degree 的分布做了优化。目前大部分框架并没有很强耦合,没有要求图的算法或分布要满足一定条件,更像是一种通用的分布式的产品。
首先 Message Passing 有凝聚点的过程(push)和 Pull 过程(Push & Pull)。在这个过程中,大部分的算法有 Sparse 和 Dense 的演化过程。比如有些图只有很少的点,如微信好友圈有些点只有很少的度,少部分点有很多的度,Push 阶段这些点都是很稀疏的,接收的时候是很稠密的。
Sparse 和 Dense 双引擎类似 CSR 和 CSC 倾向于列和行不同的压缩模式。大部分 Message Passing 算法,只有小部分的点会经过很多轮的迭代才会收敛,大部分的点几轮就会收敛。它是基于这种假设去设计的系统。
有时可能感觉它并没有达到那么好的效果,这其实与算法有关系。比如经典的 PageRank,早期谷歌在优化 PageRank 的时候,请了矩阵计算的大牛去完成优化。核心的优化点就是观察到大部分的点经历了几步以后就已经收敛了,只有少部分的点要很多轮。基于这个洞察,让一些点停止,不再跟周围的点进行更新。这只有利用到 Sparse 和 Dense 特性才可以实现。使用该系统的时候,如果不去深入研究系统原理,最终效果可能都不太理想,这个还和图结构有关系。QQ 的图与微信的图是不一样的。不同的算法在不同的图上,不同的目的,它的 Sparse 和 Dense 的表现也是不一样的。这需要算法去了解底层框架。
这个系统还有一个亮点,实现了特殊偏概率权重下的拒绝采样。
拒绝采样是动态的,如 Node2Vec 的算法,P 和 Q 的参数是来调整节点更倾向于深搜还是广搜。它使用了一种抽样方法去实现,比较适合 Node2Vec 算法。Node2Vec 每个边概率的权重是有上限的,P 和 Q 的权重决定了面积的大小,那么它就适合。此时做蒙特卡洛随机采样的时候,确实是能够看到效果的提升。但如果使用动态权重的话,就会出现一些凝聚点和高峰。比如走到一个热点(明星点),会有一些高峰诞生,周围的点就很塌。此时会发现拒绝采样要多走好多轮才可能会落到 R 中,效果反而不好。针对 Node2Vec 这种每个偏概率权重有上限的情况,确实是能够很好地优化,对于通用的情况可能就会出现很差的效果。这时候需要算法同学选择合适的框架去做,也需要算法同学非常了解应用算法和系统算法的原理,做到上下贯通。
腾讯 Angel 图计算框架
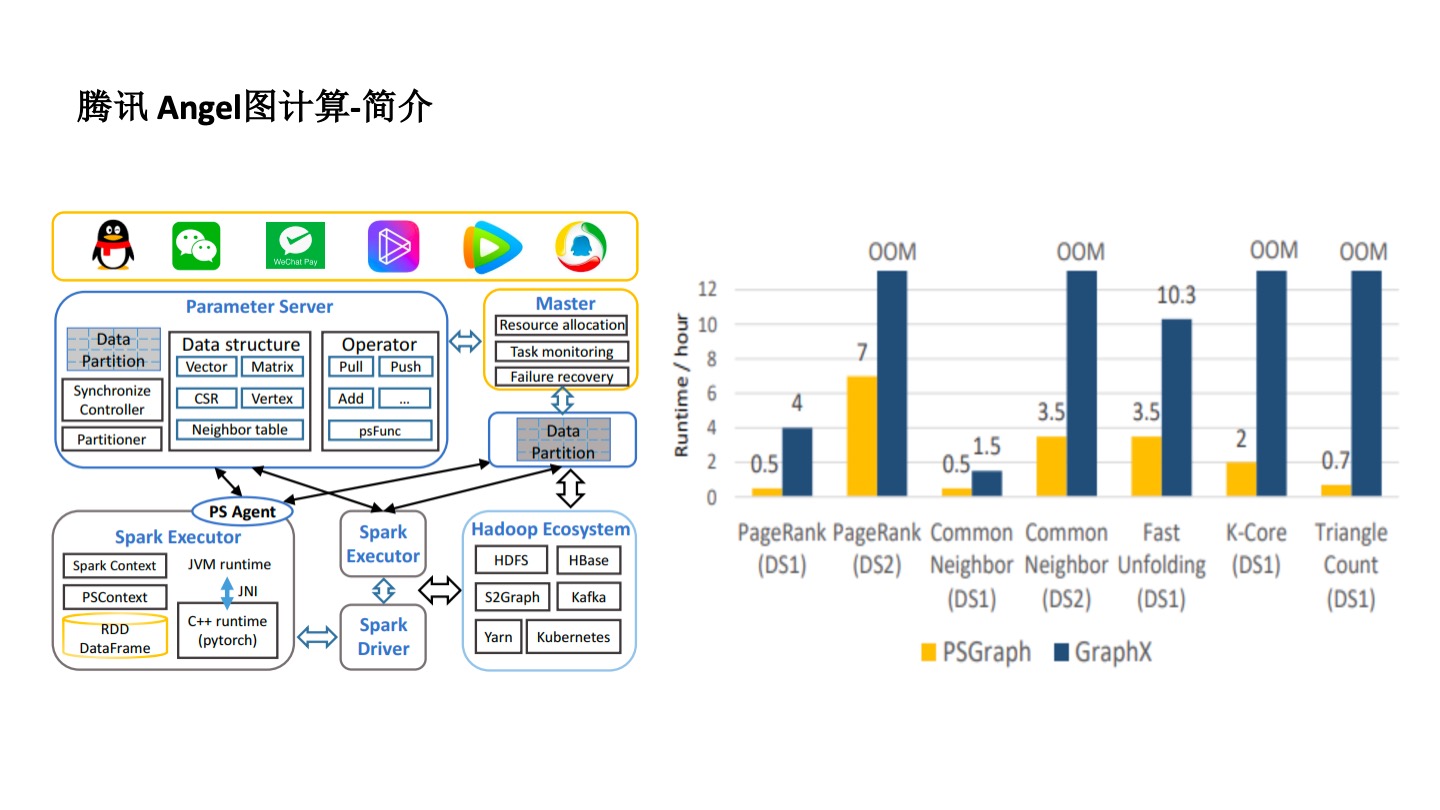
腾讯 Angle 图计算平台在有些地方很好用,但也存在一些瓶颈。
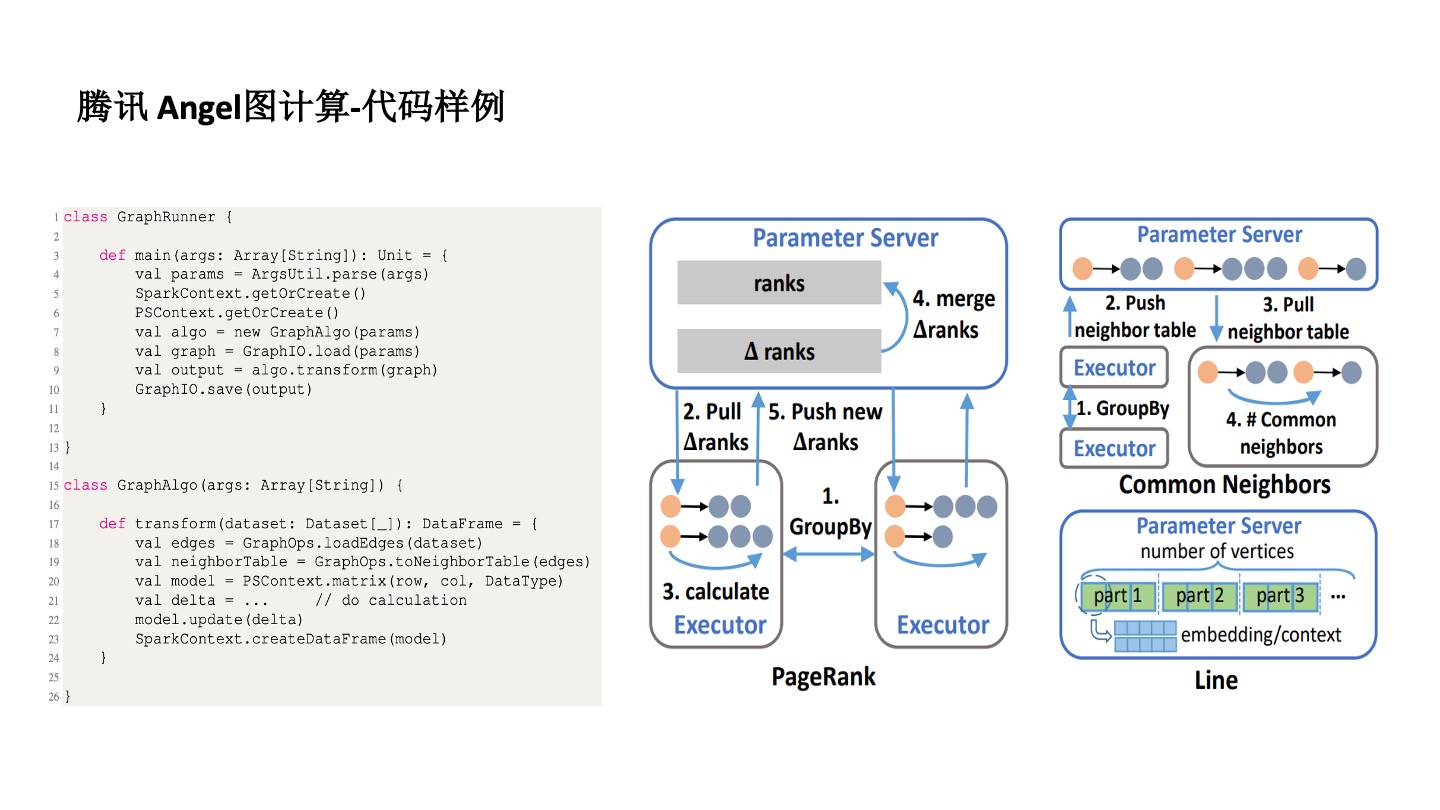
首先,图很难实现分布式及分布式管理。为了解决这个问题,Angel 用了 Parameter Server 框架去实现。对于不同的算法,比如 PageRank 要把每个点的向量作为参数存起来,然后再进行分布式计算。在分布式计算的时候,采用了 Spark 计算的原理,一个 Spark 程序有很多的 Executor 来实现分布式计算。也从某种程度上解决了算法同学编程难的问题。
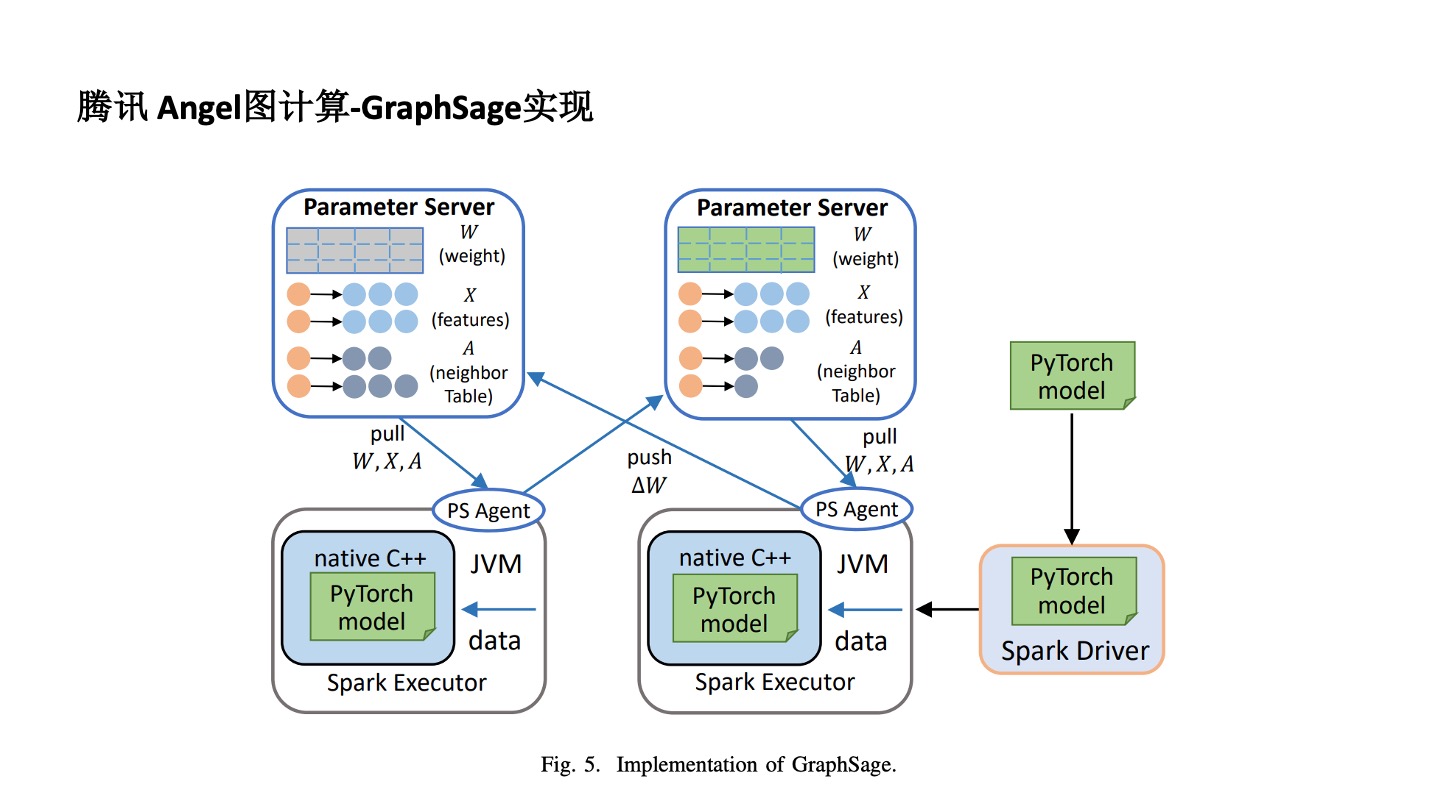
Angel 针对 GraphSAGE 改一下是能够实现的。比如通过把连接节点放在 Parameter Survey 中实现分布式,再通过 C++& PyTorch 的 Model JVM 技术,使用 Spark Execute 方式实现分布式。这是一个更通用的计算平台,不同的图算法,不管是图神经网络还是特定图模式的发现都可以实现。
开源图数据库——NebulaGraph
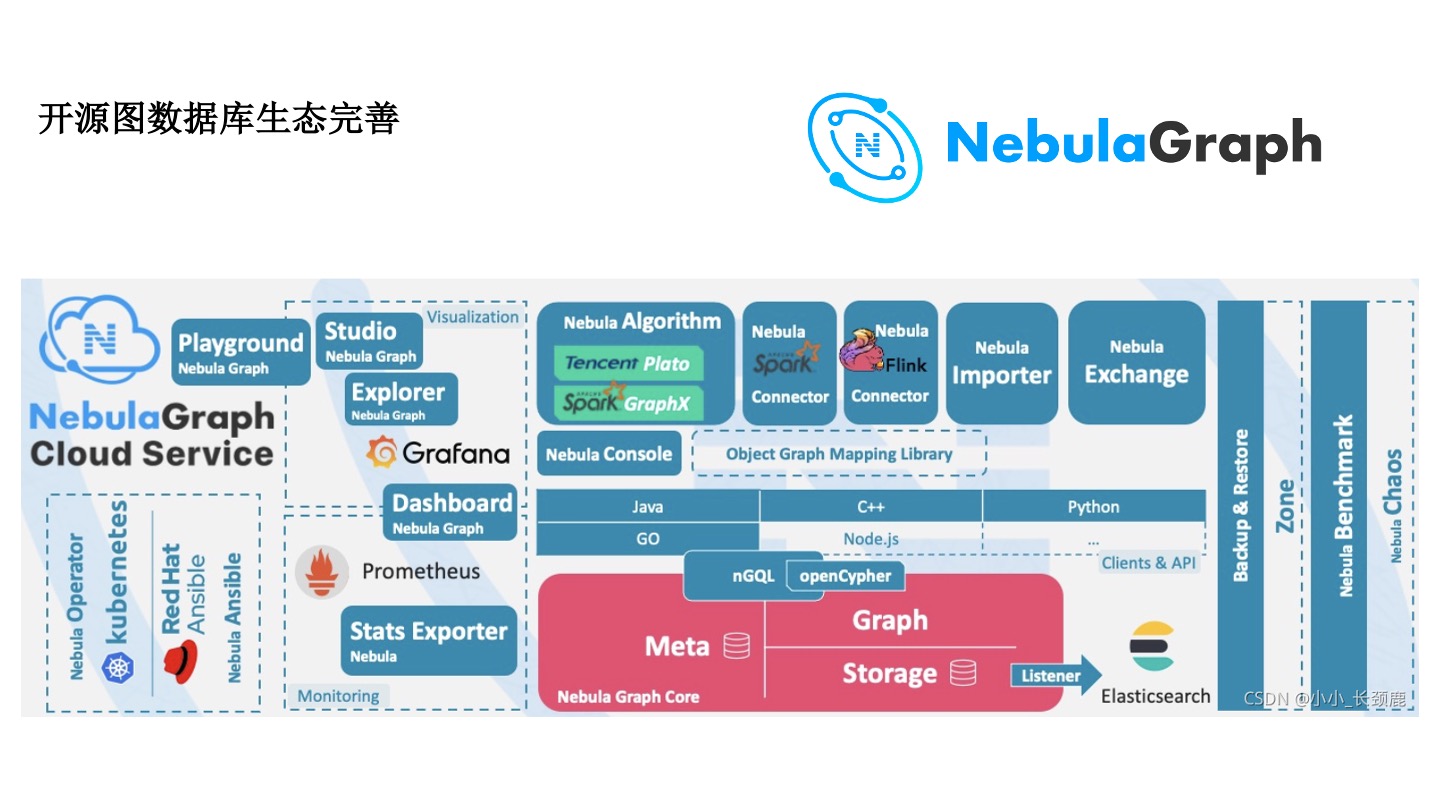
近几年,开源图数据库生态正在日益完善,NebulaGraph 的开源图数据库在社区中已经有很多的文章。早期算法同学需要自己实在 Flink 框架实现数据同步,NebulaGraph 提供了 Connector 组件可以去实现。风控要做大量的案件和观点的分析,有这种可视化的平台很方便。但是,从工程的角度,还有很多运维的事情。不管是在数据链路,跟流数据 Flink 还是离线数据 Spark 的打通上,跟图算法的打通,以及可视化分析,在运维上都已经有比较成熟的解决方案。
线上实时模型查询推理系统

金融支付防范实时风险可以用大厂的开源工具去实现。比如使用 DGL 实现模型实时推理;离线模型使用社区、交易数据训练,产生模型文件。
线上实时推理时,NebulaGraph 拿到实时文件去获得子图。Amazon SageMaker 这样的 Online 的 Inference 还是很好用的。自己去写一些脚本, query 图、解析图、导入图,再打通变成风控上的 UDF。随着 DGL 的进步和 NebulaGraph 的进步,一般独角兽公司 SageMaker 肯定是够用的。
从算法出发,反而能给到工程和设计更多帮助。比如要问 SageMaker 留一个脚本的口子的好处是什么,是要写死还是留给算法同学,可能需要不同类型的人去参与到图平台和框架的建设中去。如果不能成为风控、推荐中的一个特征或者因子,平台再好也没有多少价值,不会有更多的资源投入,也不会真正在工业界发挥作用。
DGL-Message Passing 角度优化
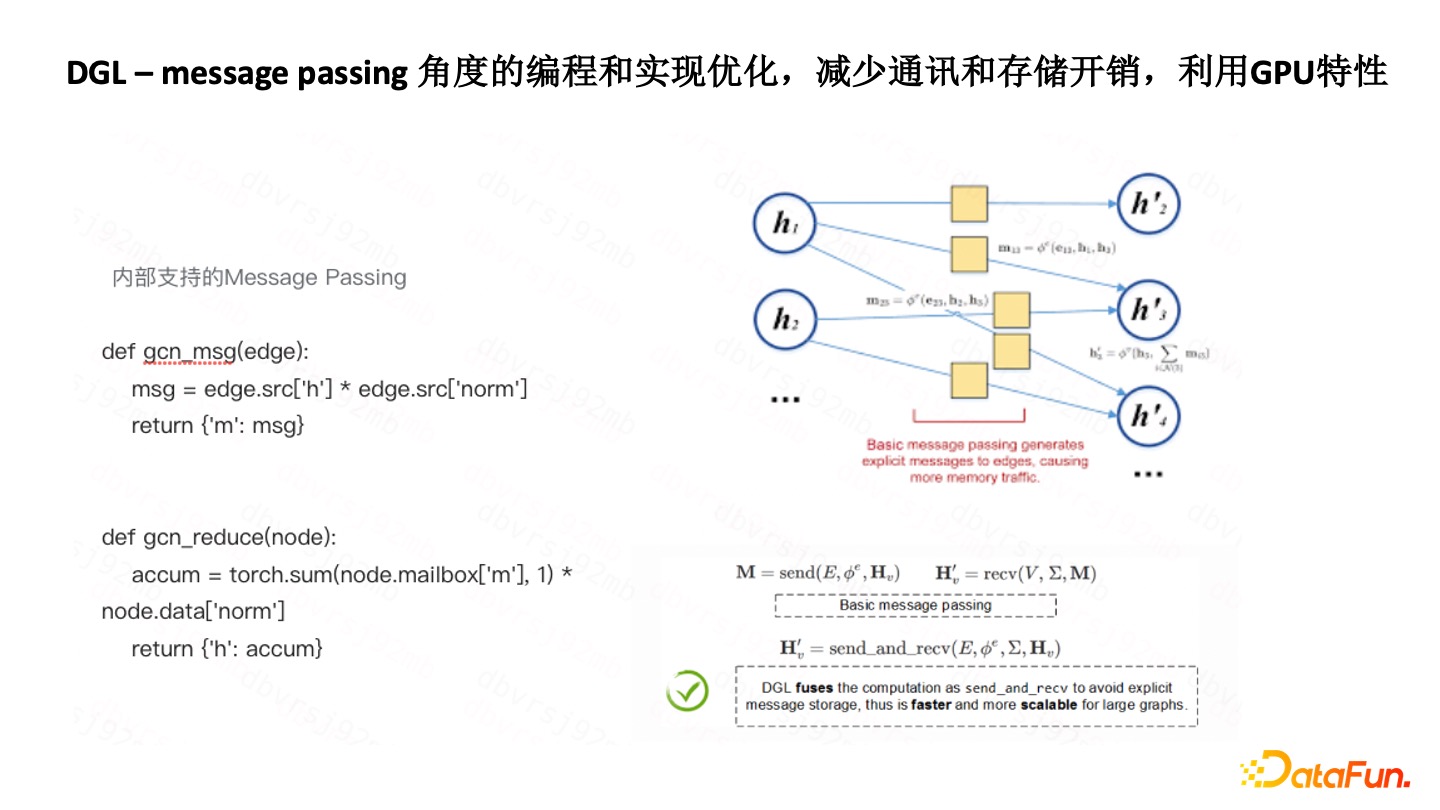
DGL 的 Message Passing 的封装做得比较好。比如用 DGL 去开发标签传播,比用 ODPS Graph 去开发,速度快了很多,效率很高,因为它把 Message Passing 函数、聚合函数都做了封装,能够快速实现各种各样的标签传播算法。
DGL 的底层也做了一些优化。因为基于 Spark,有一个问题就是 Aggregate 到 Send 过程会有很多额外的通讯和存储的开销。优化的方式是把该过程变成了矩阵的计算,然后再用到 GPU 优化的特性去完成,所以编程难度有所降低,效率上有很大的提高。

另外,有时图本身并不复杂,GPU 很长时间在等待。现在的做法是,把更多的计算放到 GPU 中。去年黄仁勋在英伟达大会中也谈了 GPU 对 DGL 的推动。当然在工业界,与敏捷有一些差别。敏捷是更往下走,希望能封装成更底层的一些神经网络的算子,而我们是希望往上封装,提高对一线算法同学的易用性。

我们自己做了一个 DGL-Adapter,以突破内存限制,用少量的通信成本的牺牲,换取更大的图数据规模的训练能力。这是一个分布式的框架,有 Client和 Server 去获取图数据,再把不同的 Batch 分发给不同的 Worker ,不同的 Worker 有了反馈结果,采样的结果再返回过来进行计算。
展望未来
最后展望一下未来。长期的趋势是要从算法层面、平台层面、系统层面去改进。
图算法和图神经网络算法的融合
现在很多团队在谈 GNN,但有时并不能说清 GNN 到底学到了什么东西,解释能力有多强。图的传统算法也不能放,因为不同的互联网公司、社区等等,都有不同的网络结构。我们要基于这些网络结构有一些洞察。比如是否需要和图神经网络,和 Data Mining 结合。在风控的特定场景下,还要对图的特定 Pattern 去进行挖掘。比如 Angel 支持在 Parameter Server 框架的基础上加 Spark,DGL 又开了一个 Message Parsing 的口子,只要是能够变成 Message Parsing 框架的图算法,就都是可以实现的。首先,算法同学在一线要知道如何融合,才能跟中台团队框架团队去合作。
图神经网络算法学习能力的攻克
学习能力的攻克,包括基本算子的不断突破非常重要,否则光是四则混合运算,再怎么组合其本身学习能力就不够。
图神经网络算法鲁棒性
风控很多时候是对抗,并不知道会有什么样的攻击方式,因此要提高算法鲁棒性。
图神经网络算法可解释性
无论是推荐还是风控,现实中制约落地的很多时候是一个可解释性的问题。
平台易用性和整合性
平台易用,用起来流程快,才能更快地实现各种算法的迭代。
应用算法和系统算法上下融合贯通和统筹
在建设图计算平台的时候,要真的懂业务和应用算法,实际用户也要懂系统算法层面,整体上需要上下打通和统筹。
一线算法、平台算法和中台等各个团队需要加强合作,也需要学术界和工业界一起努力。
问答环节
Q1:风控场景中,它有这种事前事中和事后这种图模型。在这些三种不同的场景的话,它的图模型分别是如何来应用的?
A1:可能以前我们对算法和系统的发展没有那么好的时候,会分得比较清楚,事前事中事后,但是现在发展得更快,尤其我前面说的那个框架,就图数据库的完善,DGL 以及类似 SageMaker 完善了以后,实时模型也不像以前那么难了,所以它在应用的时候更多的还是从数据和特征角度一方面要去考虑。在事前事中事后拿到的数据不一样是可以容忍的,计算量是不一样的。可能在事前算法不会那么复杂。比如一个新用户的数据本身是有限的,那这时候去做事后就可以上一些更加复杂的算法。一个人比如说今天来了就要判断他是坏人还是他在这里表现了 30 天是坏人?两者难度是不一样的,在算法的复杂度特征上是会不一样的。
Q2:在风控场景中有遇到图模型的可解释性问题吗?怎么解决?
A2:这个其实是很有意思的问题。图模型的解释性,其实说句实话比其他模型要容易的。为什么?因为图算法在风控为什么用得那么好?它有个强大的图的可视化能力。把不同的团伙可视化出来,一目了然。通过可视化来展示你的算法,主要就发现几种模式,一看就知道是批量注册。也可以通过动态图的演化,有一伙人在迁移。这方面大家可以多用一些图可视化的技术去形象化地把你发现东西总结出来。这是最快的。你也可以尝试着去实现一个 GNN Explain。这里可能有些坑,因为 GNN 本身是一个优化问题,一般的机器学习都是无约束的,优化之后怎么去处理?可以弄一个近似 GNN Explainer 就大概知道到底学到了什么。不知道你学到了什么东西,其实也很难去进一步调整图神经网络,然后可能还要用一些观察。个人建议大家可以找一些学术合作伙伴,对于明天的方法,后天的方法也可以让学术界的朋友来看一看,就是说如何能够定量地去对 GNN Explainer 做一些突破,这些都可以。
Q3:图算法的鲁棒性,有哪些方法去度量?
A3:这个分一种学术上或者技术上严格意义的。这个度量是指改变了点和边的一些特性以后,其结果的变化,那就是一些面子上的或者是最基本的。在风控场景下的所谓鲁棒性的攻击,我总结下来就可能,点是真的,边是假的或者点是假的,边是真的。比如说今天别人伪造 IP 随便输了个 IP 来脚本攻击,那 IP 可能是真的,但边是假的?那有可能今天伪造了一个东西,这个点就是假的,所以有几种可能性。作为风控来说,可以尝试这几种不同的可能性去对你的模型进行攻击。因为现在对于风控来说比较缺的就是领域内的 Cost 和 Attacks。Attacks 有时候是未知的,黑产有时候用你不知道的方法,但是 Cost 可能是知道。在 Cost 和 Attacks 部分知道的情况下怎么去定义模型的鲁棒性,我觉得这个可能是对风控来说比较有价值的一个研究方向。
今天的分享就到这里,谢谢大家。
分享嘉宾
汪浩然,互联网行业资深风控和图计算专家。英国硕士,曾在蚂蚁金服,阿里巴巴,腾讯等公司主要从事风控算法,社交计算和图计算等工作,横跨金融,支付,电商,供应链,社区,社交等场景。率先工业界落地过诸多图上挖掘和机器学习算法,有算法百晓生和扫地僧之称。
谢谢你读完本文 (///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 → GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呀~