user82
1
老师您好!
我在spark环境下,按照 PageRankExample.scala 的示例,尝试调用Louvain算法,结果发生报错。
整体思路是按照下面:
import com.vesoft.nebula.algorithm.config.{Configs, PRConfig, SparkConfig}
import org.apache.spark.sql.{DataFrame, SparkSession}
import com.facebook.thrift.protocol.TCompactProtocol
import com.vesoft.nebula.algorithm.config.{LPAConfig, LouvainConfig}
import com.vesoft.nebula.algorithm.lib.{LabelPropagationAlgo, LouvainAlgo}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
val spark = SparkSession.builder().master("local").getOrCreate()
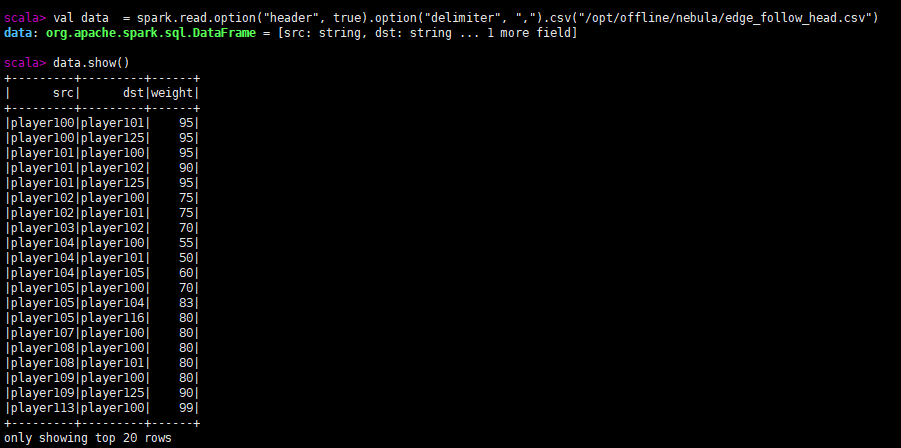
spark.read.option("header", true).option("delimiter", ",").csv("/opt/offline/nebula/edge_follow_head.csv")
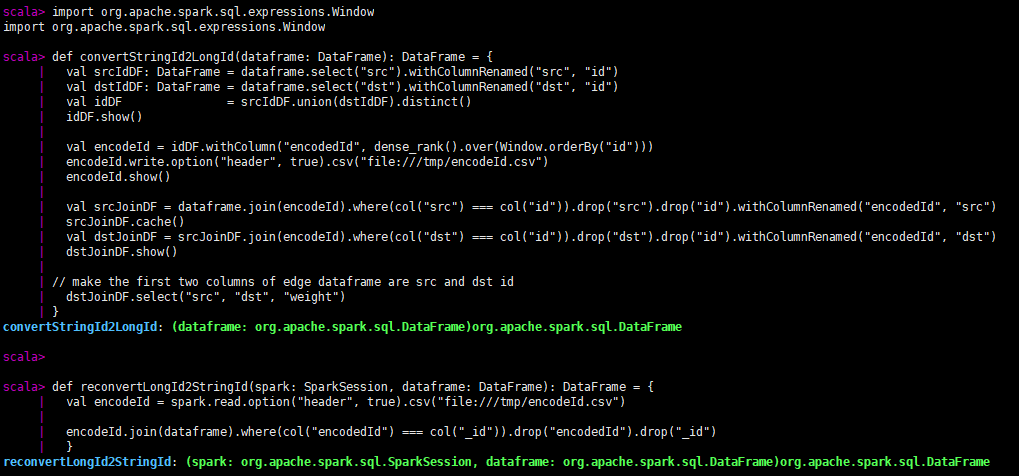
def louvain(spark: SparkSession, df: DataFrame): Unit = {
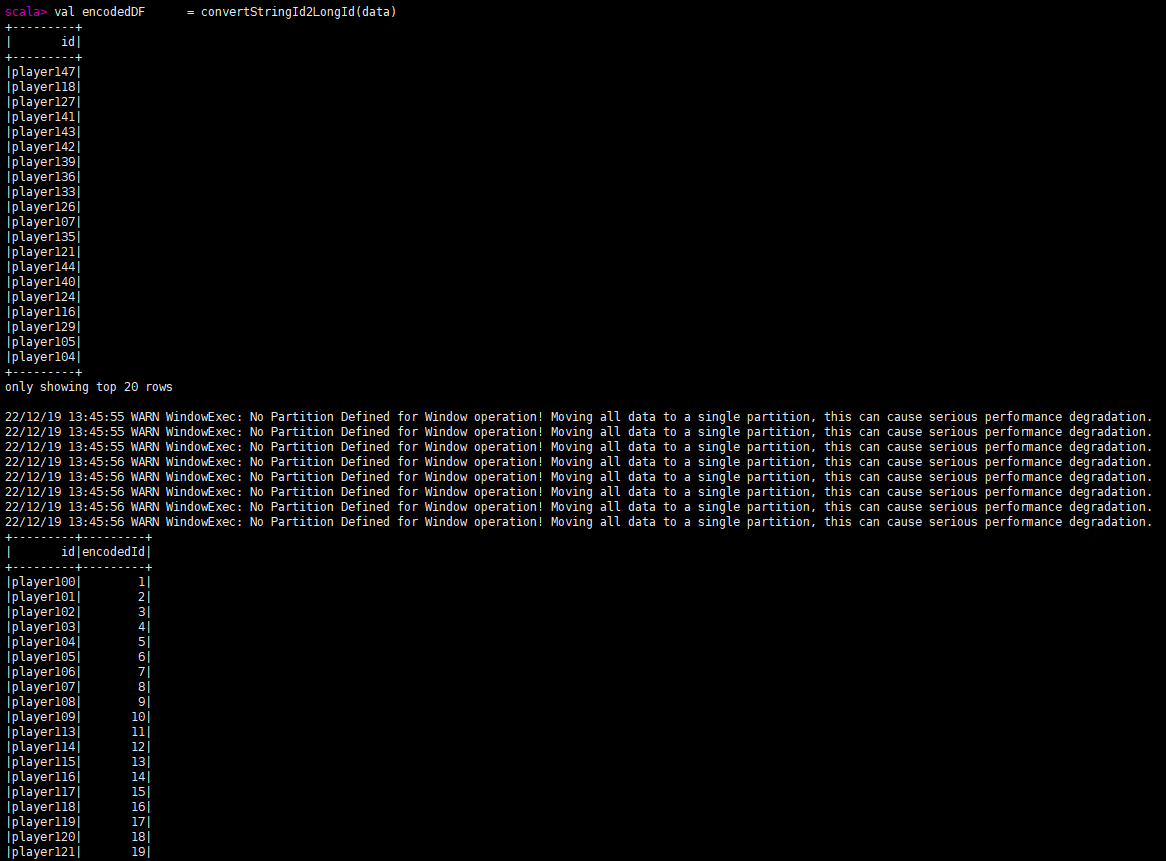
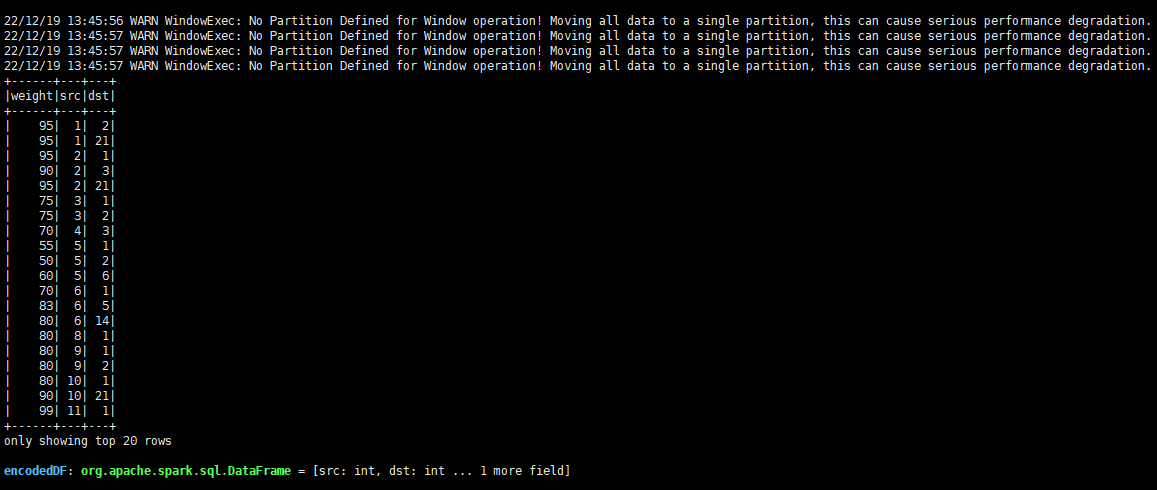
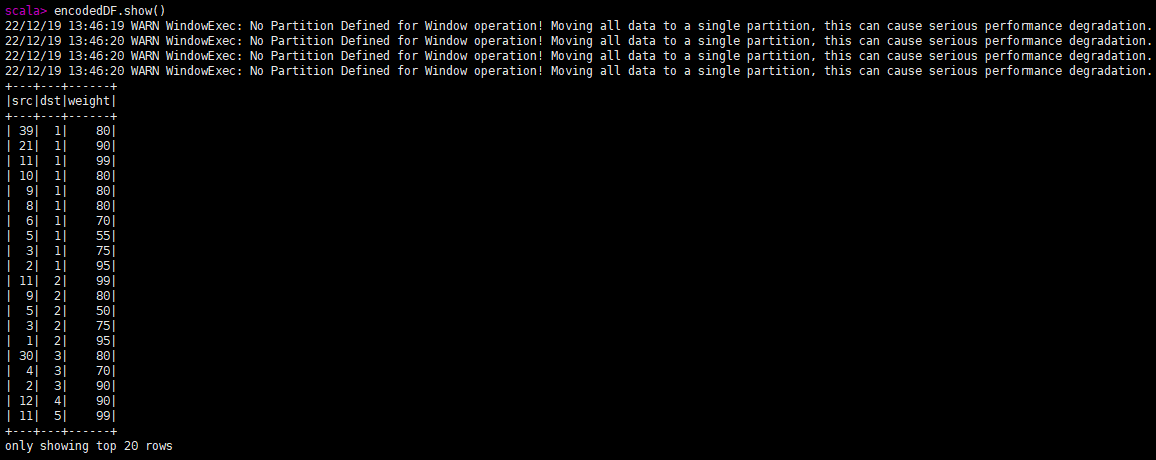
val encodedDF = convertStringId2LongId(df)
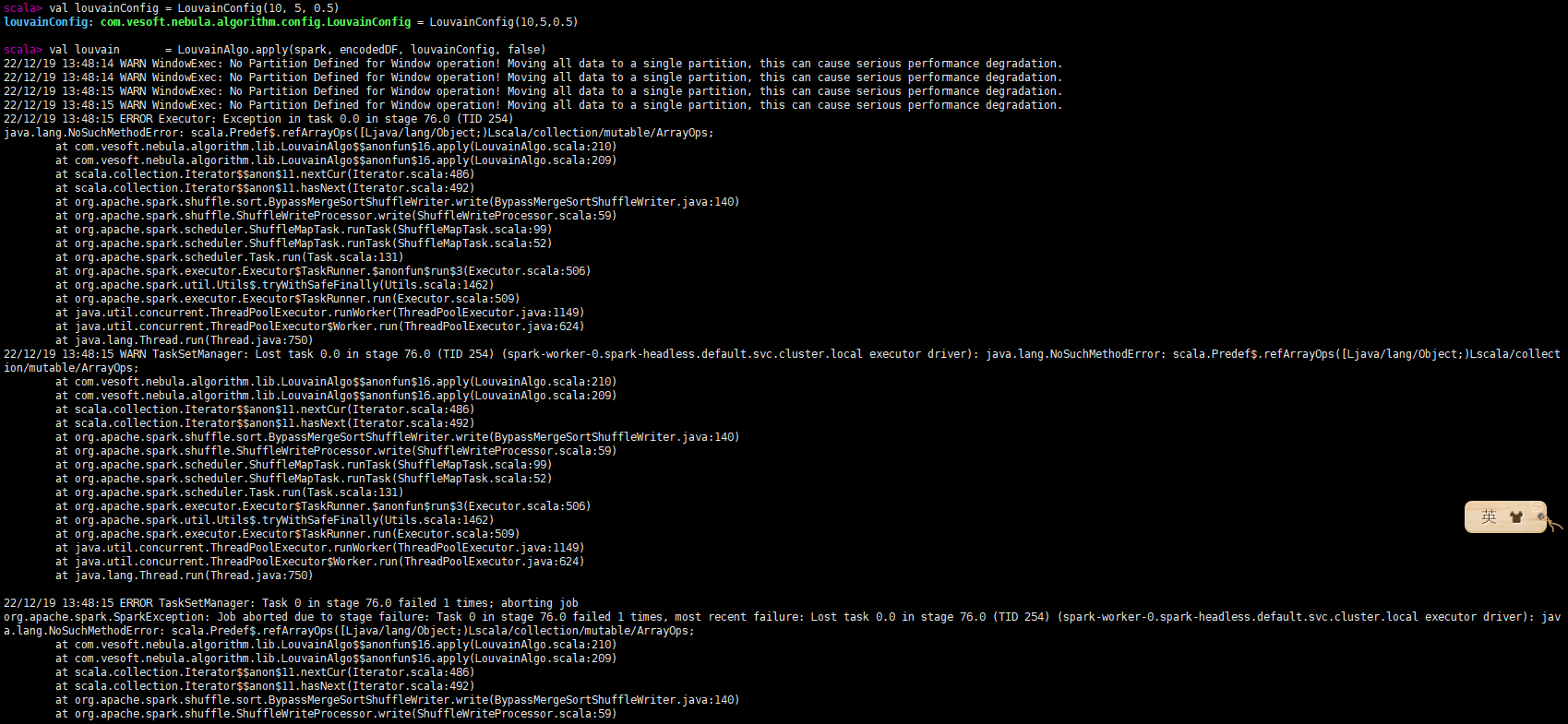
val louvainConfig = LouvainConfig(10, 5, 0.5)
val louvain = LouvainAlgo.apply(spark, encodedDF, louvainConfig, false)
val decodedPr = reconvertLongId2StringId(spark, pr)
decodedPr.show()
以下是大致截图:
- 读取数据
- 定义字符串转整型数据、整型转字符串数据
- 转换类型
查看转换后的结果:
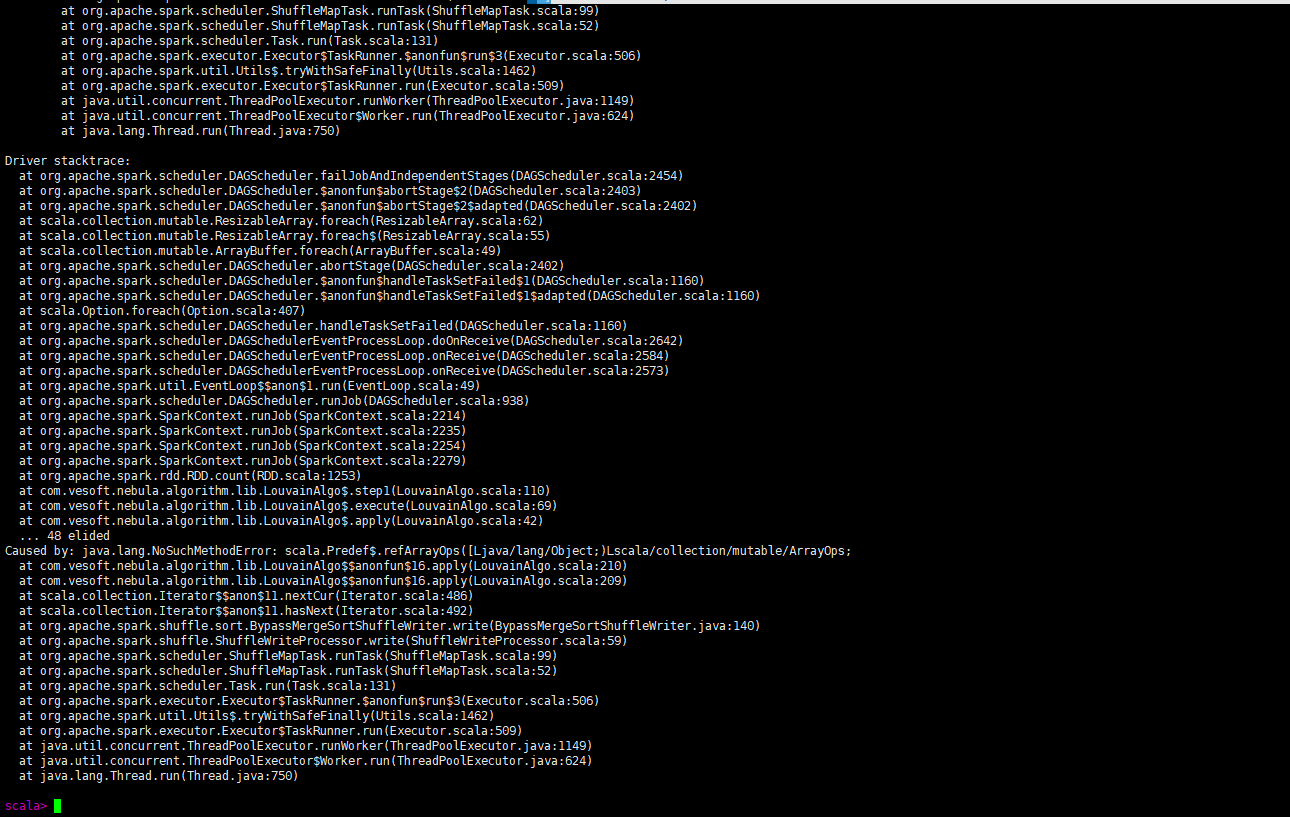
- 调用louvain算法(报错)
请问各位老师,这个错误是什么原因呢?调用pagerank算法好像可以跑通。
steam
2
所以你的 spark 版本号多少,用的 nebula-algorithm 什么版本?
user82
3
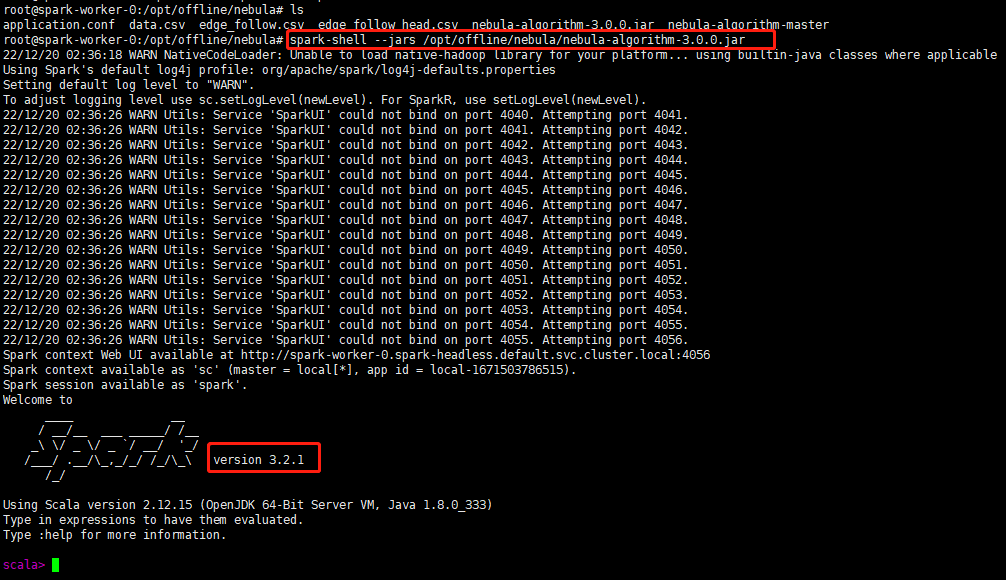
spark版本是3.2.1,nebula-algorithm是3.0.0版本,另外我是通过下面命令进入spark-shell
spark-shell --jars /opt/offline/nebula/nebula-algorithm-3.0.0.jar
nicole
4
spark版本不兼容,algorithm只支持spark2.4
user82
5
哦哦 好的 我改下版本试试 谢谢!
另外还想多问一下,1. 如果调用louvain算法进行社区划分后,如何将结果应用回图库呢?
2. 是给每个节点加一个类似cluster_id的属性吗?(我前几天用python中的igraph和louvain模块,是这么做的)
3. 是否能将节点的社区划分可视化呢?
nicole
6
1和2: 是的,算法结果你需要写回图数据库的话是写到节点属性上的,所以要求tag 有对应的属性名,louvain算法要求属性名是 louvain
3. 你写回图数据库后,可以通过studio进行节点展示,根据你的louvain属性值进行着色
user82
7
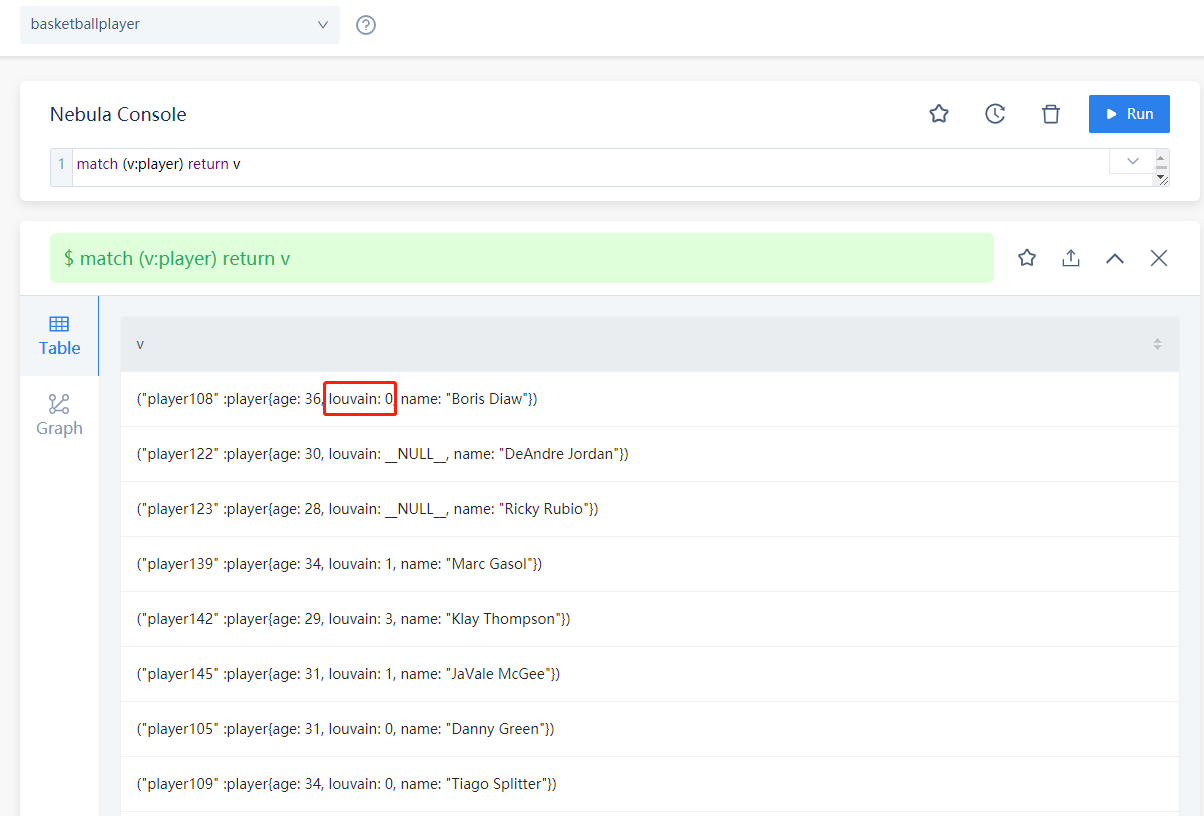
我将tag增加了louvain属性,并插入了不同的值:
请问接下来我该如何进行着色显示呢?
user82
9
老师 您好!我将spark版本改为2.4之后,可以跑通,特别感谢!
我还想问两个问题:
val louvainConfig = LouvainConfig(10, 5, 0.5),这三个参数分别指maxIter,internalIter和tol吗?我看了LouvainAlgo.scala中的源码,还是不太明白这三个参数分别代表什么含义呢?- 针对跑出的结果
louvain这一列是指所被划分的社区编号吗?为什么数值不连续呢?
感谢老师解答!
user82
11
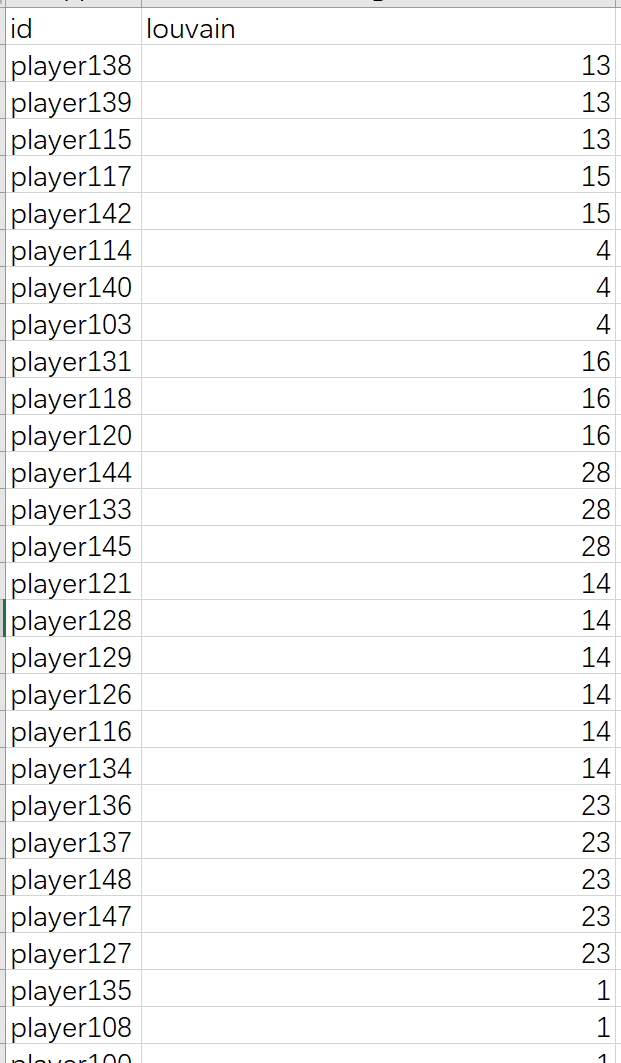
也就是说louvain这一列是指社区编号吧?我之前用python做的时候,结果是下面这样:
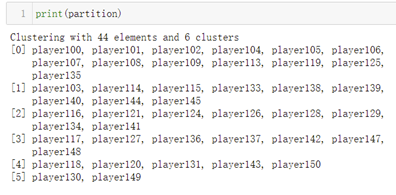
我理解0 1 2 3 4 是不同的簇。
那louvain这一列的不同值也是代表不同簇吧?
nicole
15
因为算法内部是采用 当前社区内节点的最小id作为该社区的编号,不同社区内最小的节点id通常不连续的
1 个赞
user82
17
老师您好! 我又有个问题:
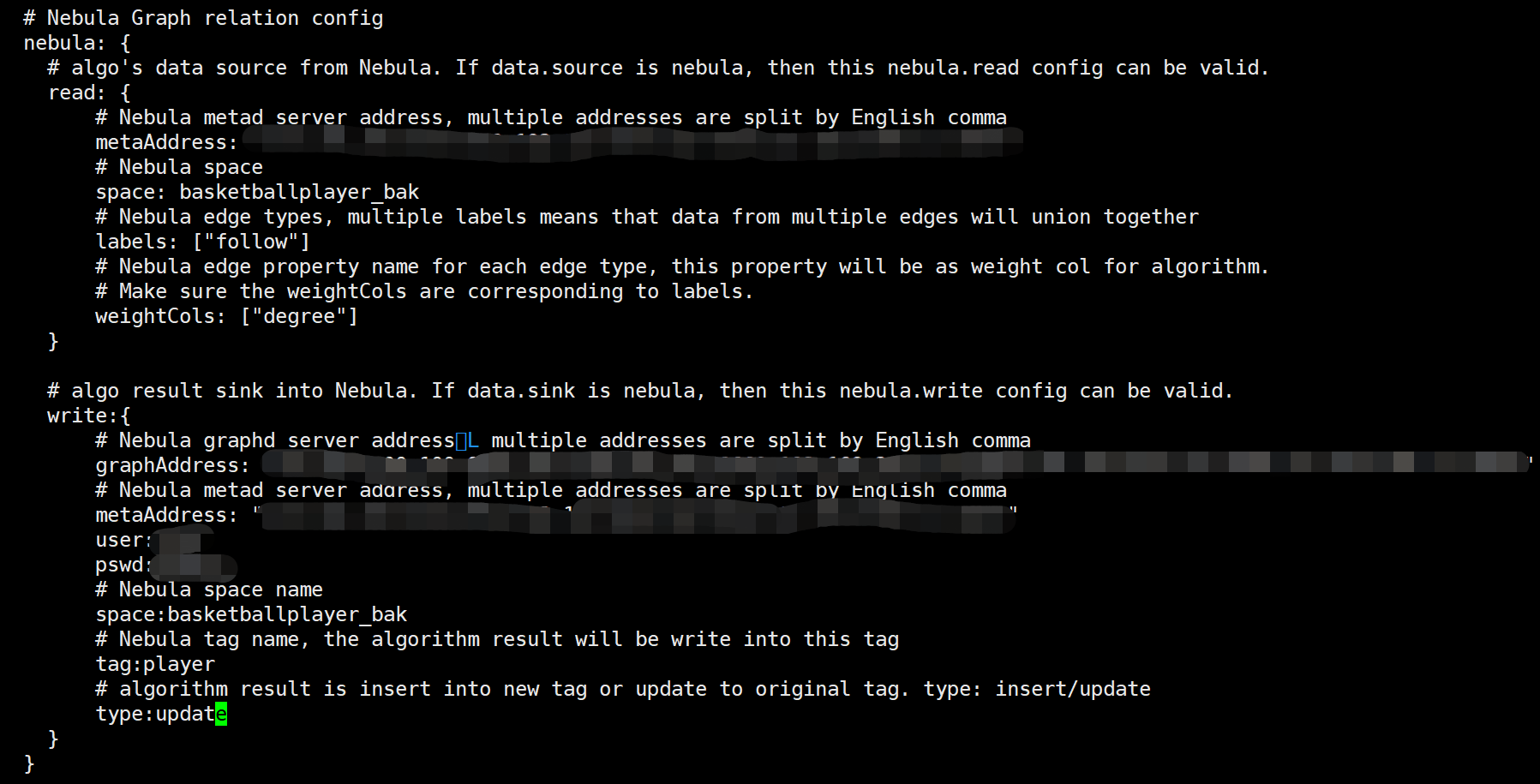
我采用提交algorithm算法包的方式跑louvain算法,将application.conf中的data source和data sink都设置为nebula,nebula write中的type改为“update”。
然后运行,发生如下错误:
这个是怎么回事呢?
user82
19
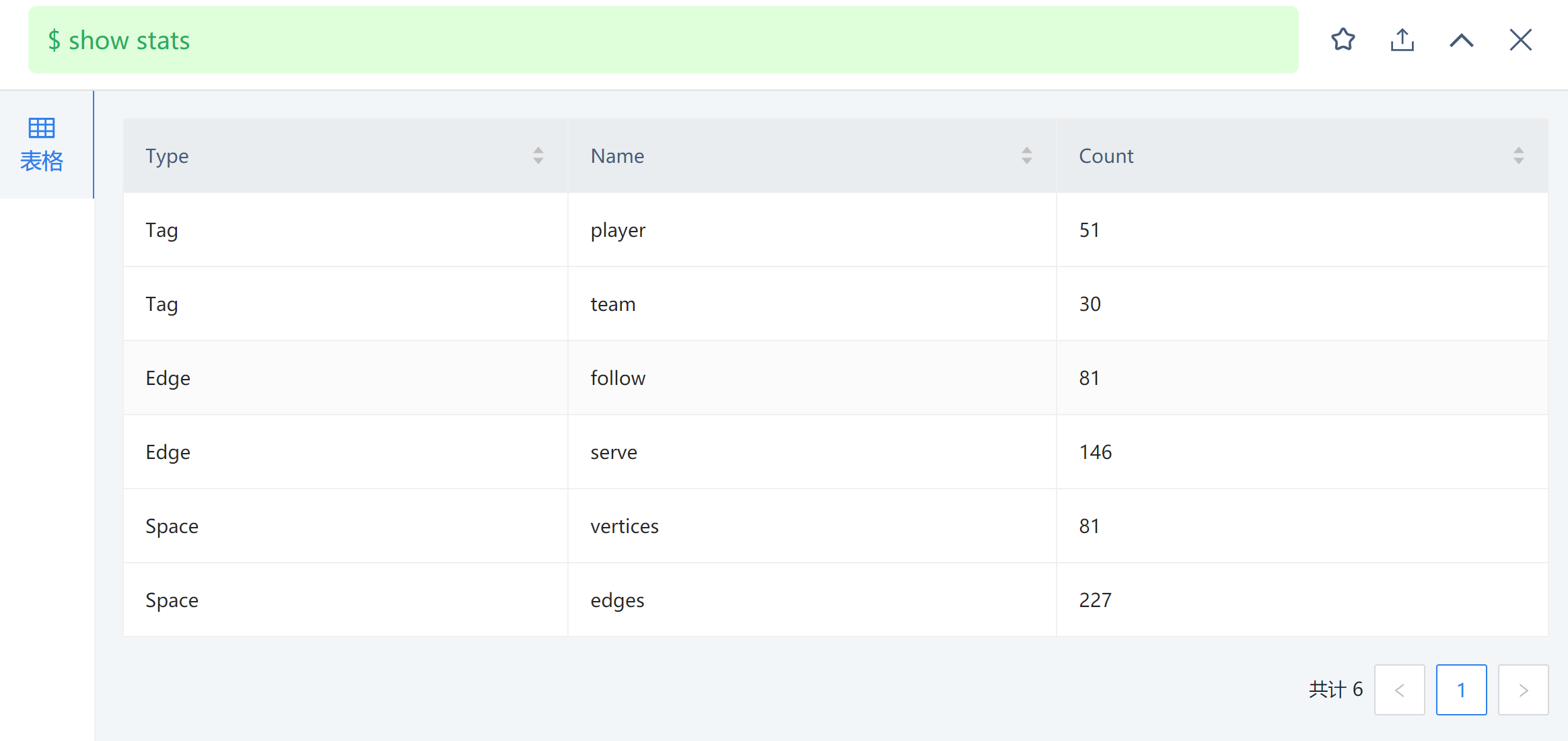
目前的数据量是:
我如果将application.conf配置文件中的nebula-write type 改为“inset”,就不会出现这个错误,但是那样会将其他属性值(比如name,age)变为NULL。
nicole
20
这个assert是spark connector在更新数据的时候做的校验,algorithm里面给出的默认batch是1000,这个该应改小一些,我提个pr 你可以用最新的algorithm包