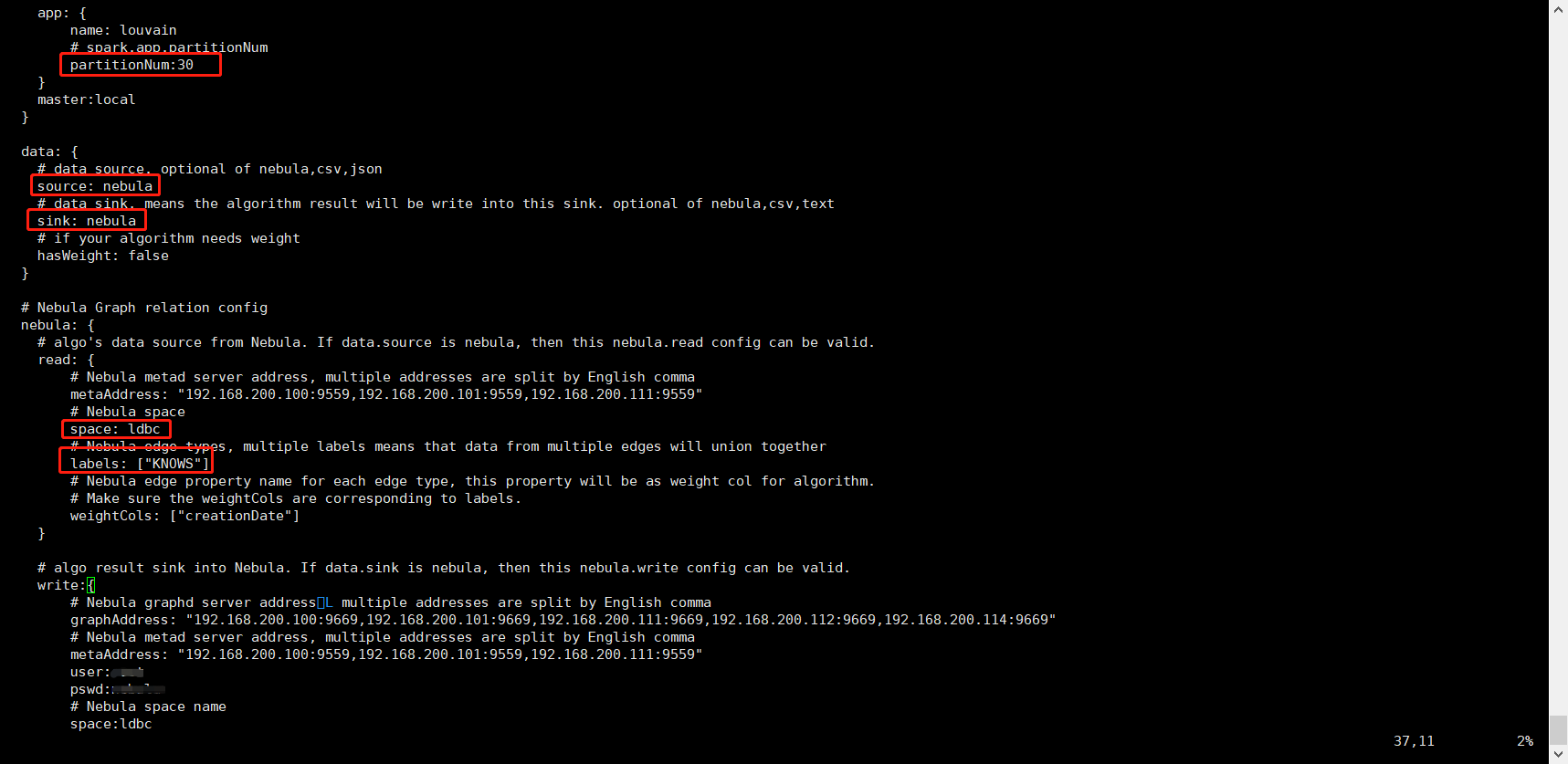
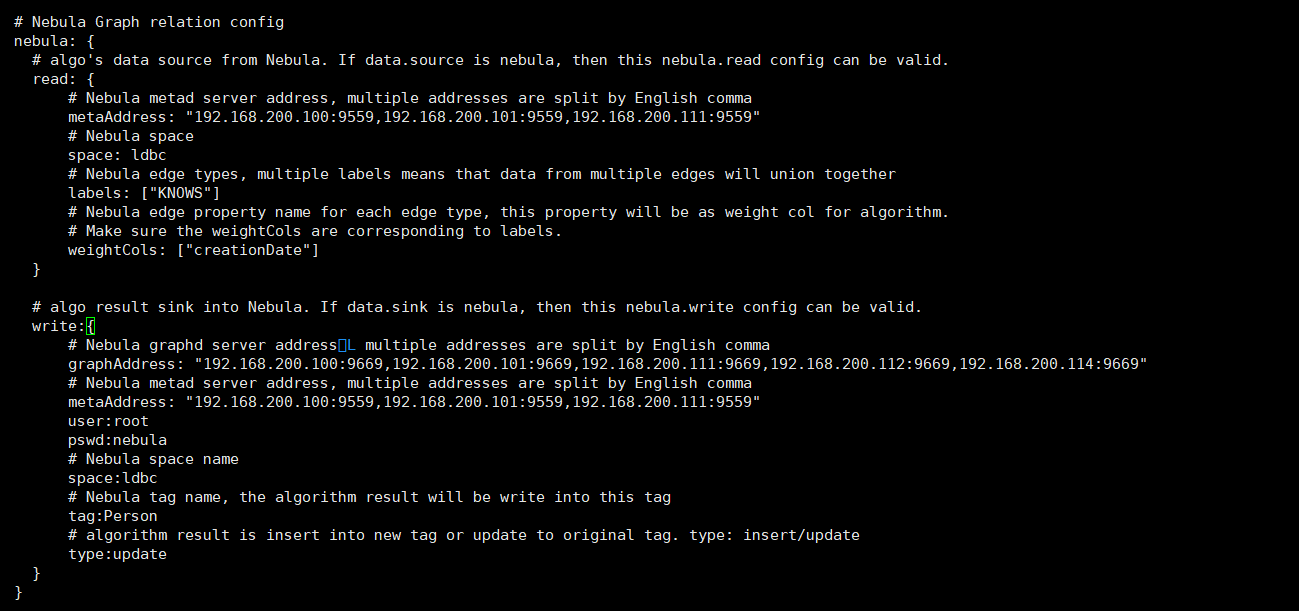
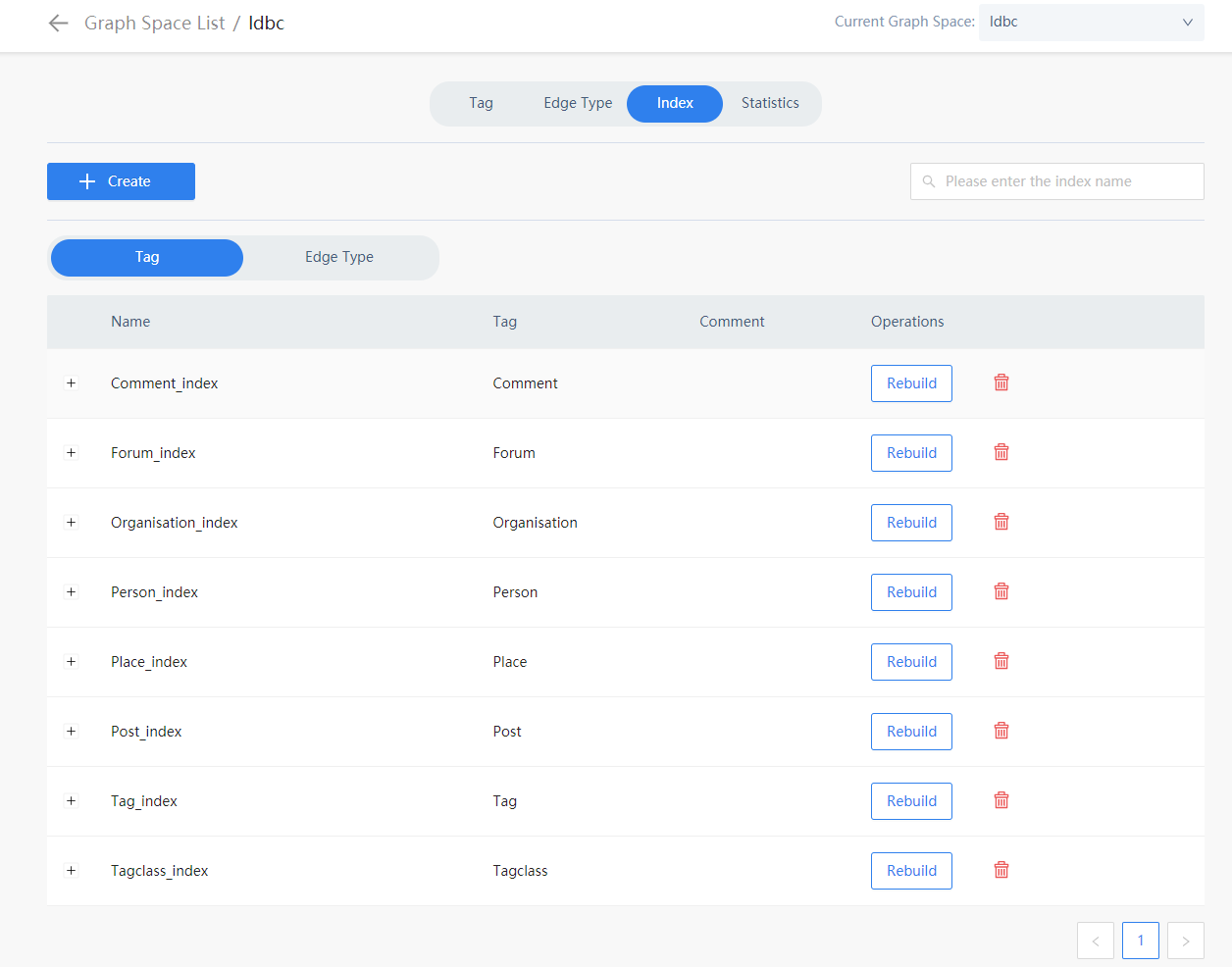
老师好,我在部署的nebula studio中,导入了ldbc数据。数据统计如下:
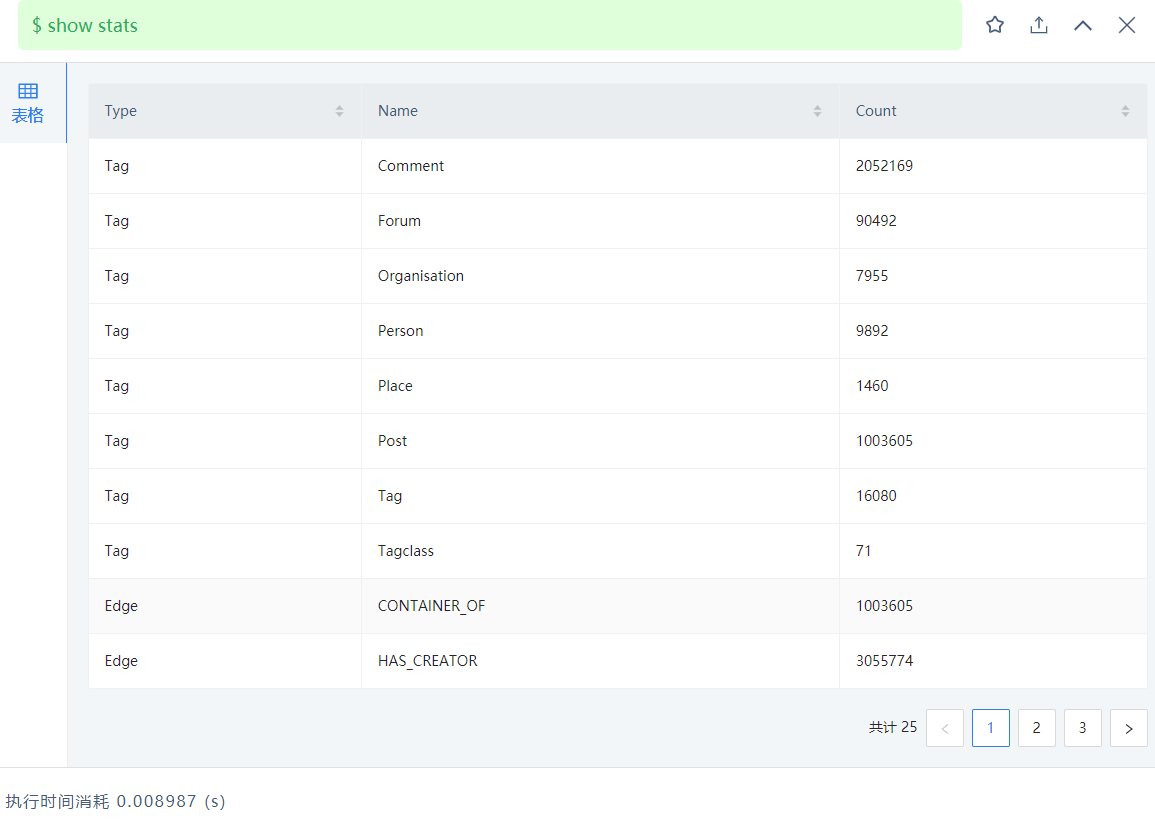
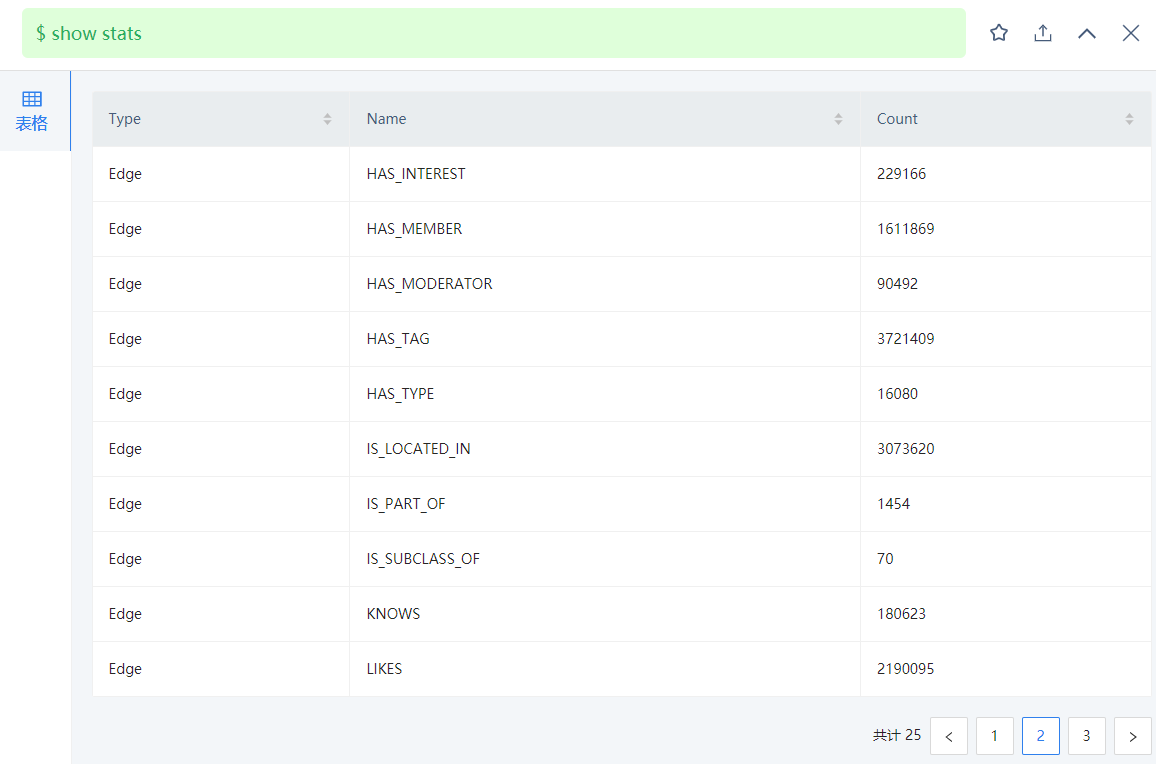
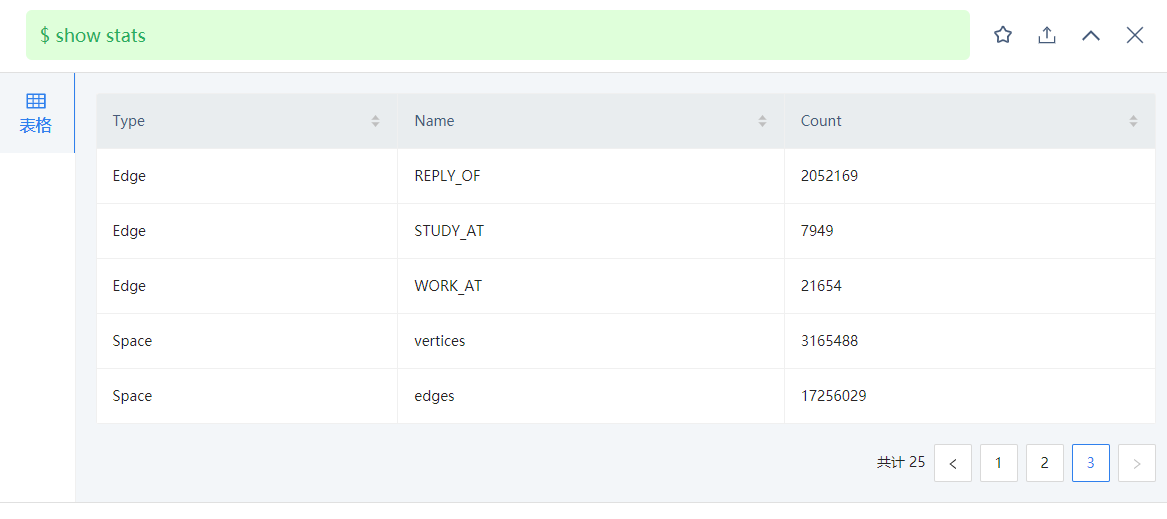
我一开始用match语句查询的时候,虽然慢,但是可以查处结果,后来再查就报错了:
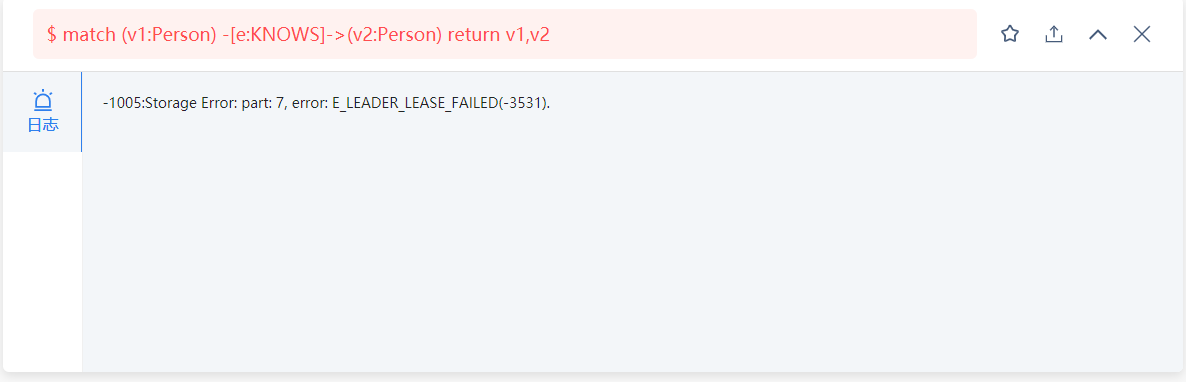
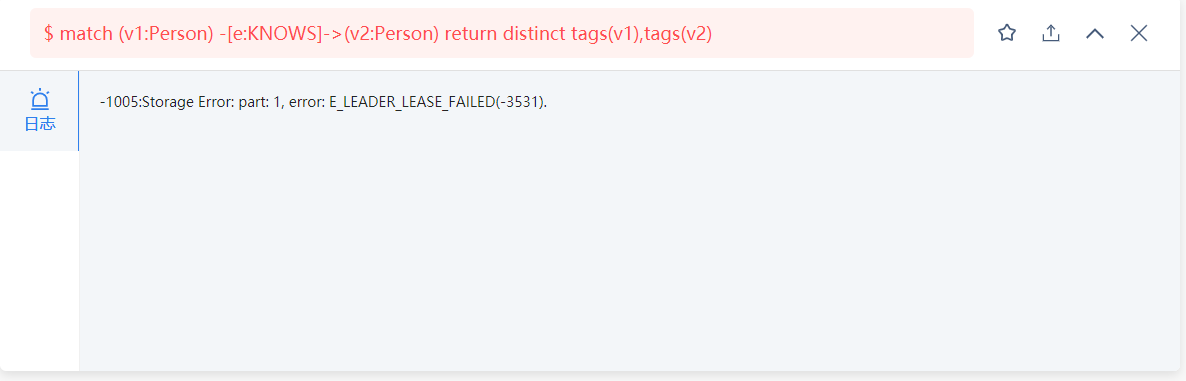
这是怎么回事呢?
同学你好,麻烦按照模版补充下 NebulaGraph 的版本号和 Studio 的版本号,都提了 4 个问题了,希望下次不要再提醒你补充版本了 ![]()
好的 不好意思
NebulaGraph版本为3.2版本
Studio 版本为v3.4.0。
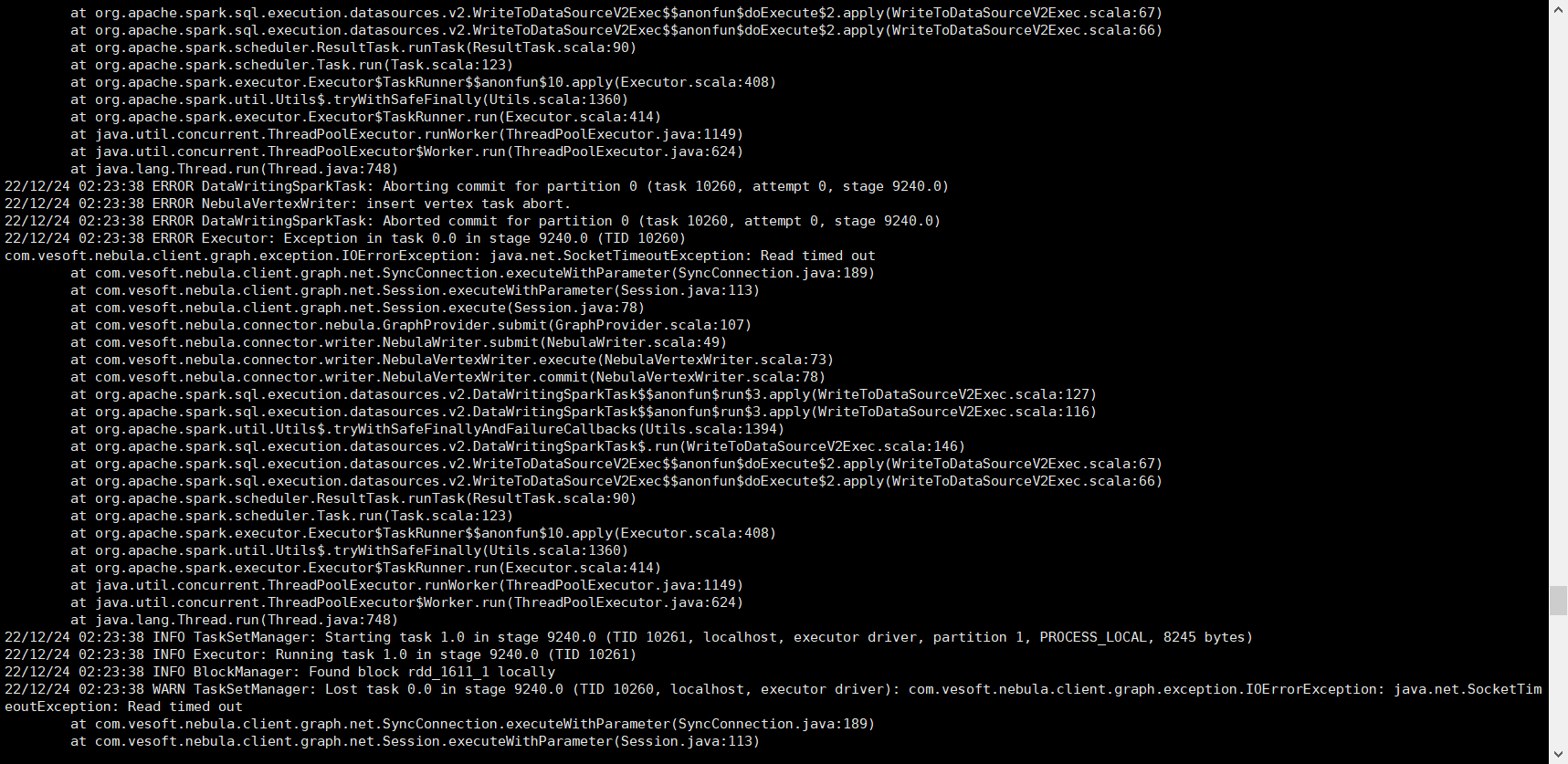
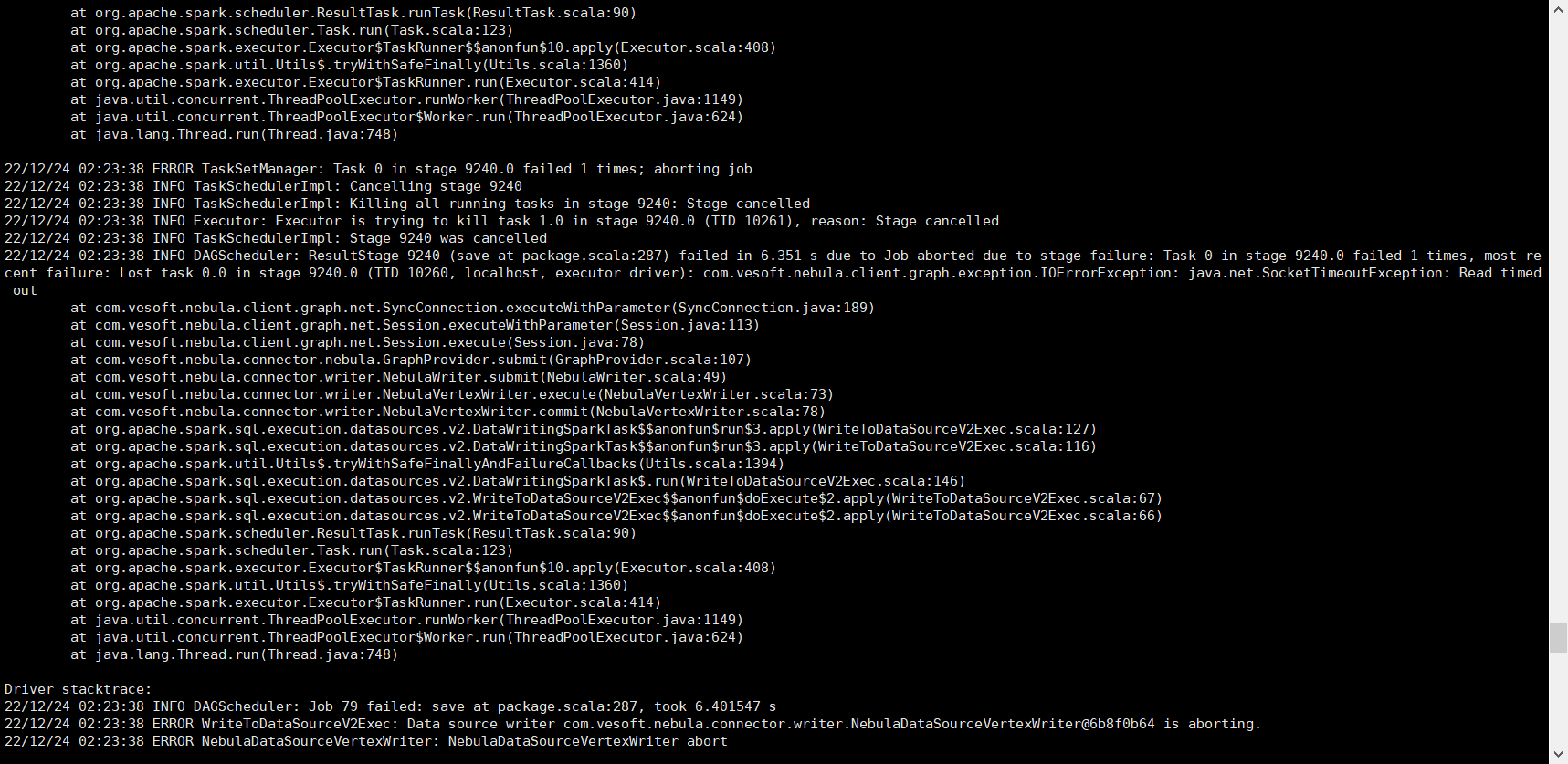
除了上述在studio中查询出现的问题,我通过提交算法包跑louvain算法,换成ldbc数据源,application.conf配置如下:
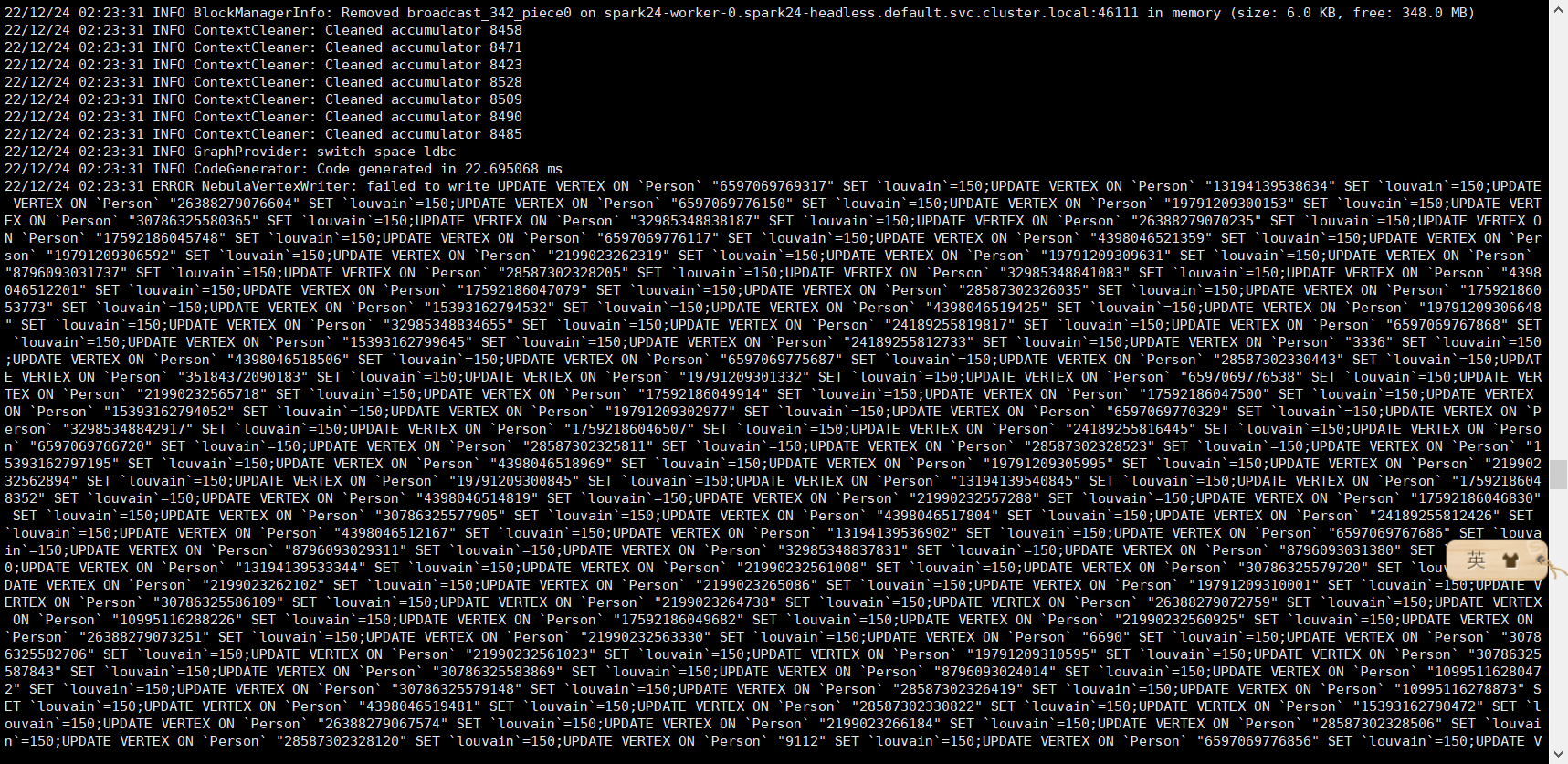
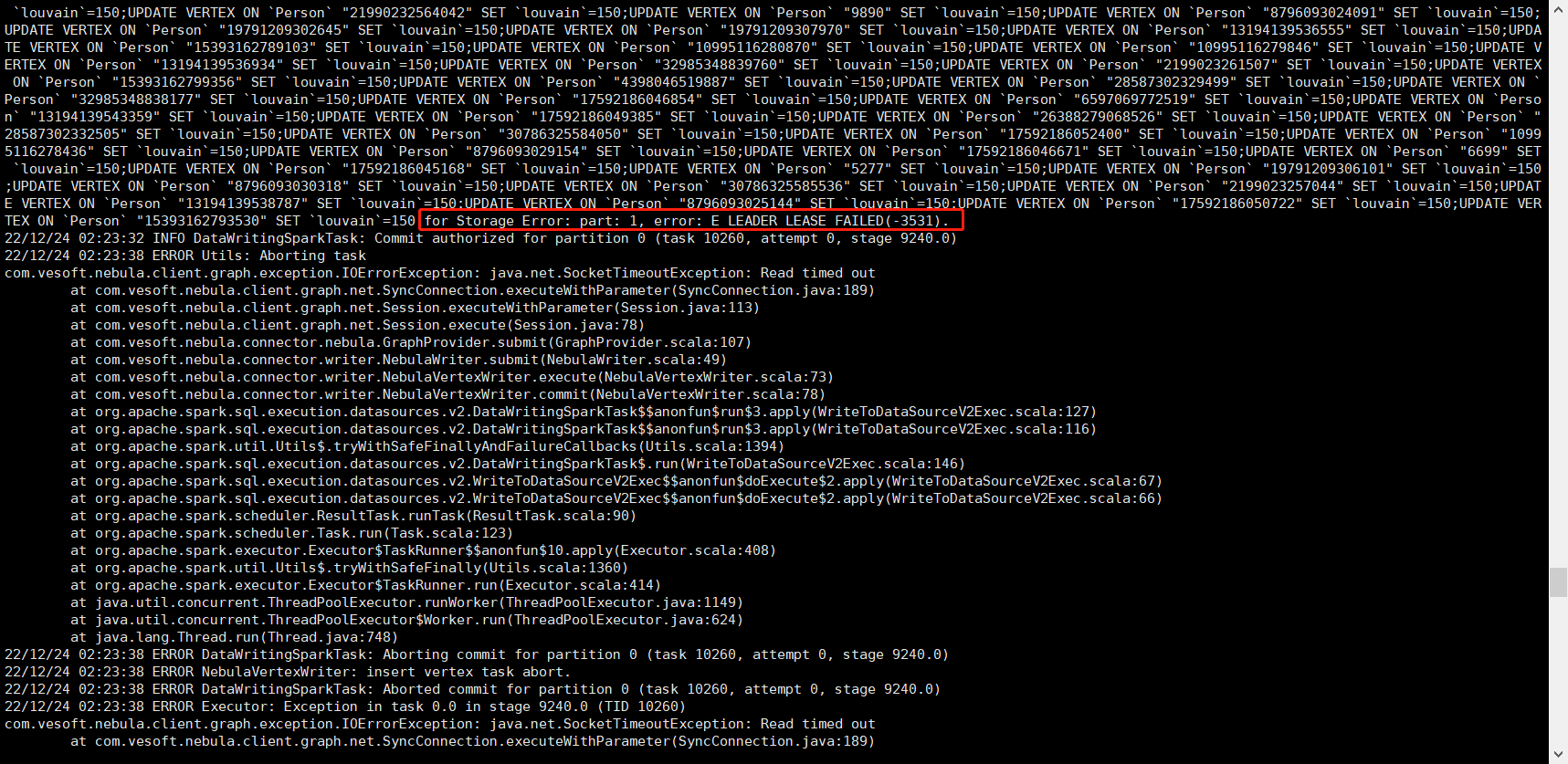
跑了15分钟后报错:
nebula-stroaged.INFO 和 nebula-metad.INFO 的日志能贴一下吗?在安装目录 logs 文件夹里
然后回归问题,以下是日志的路径:
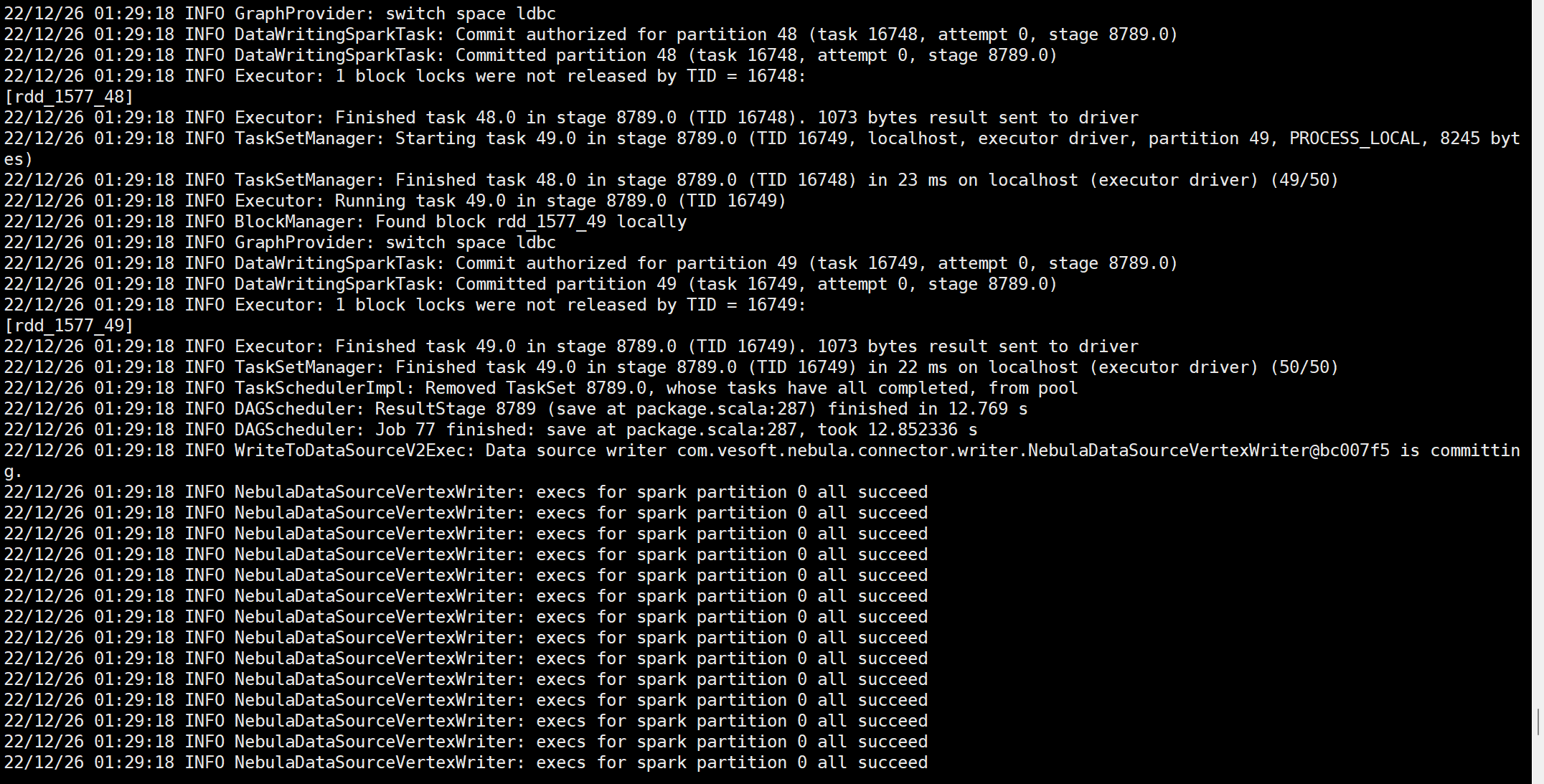
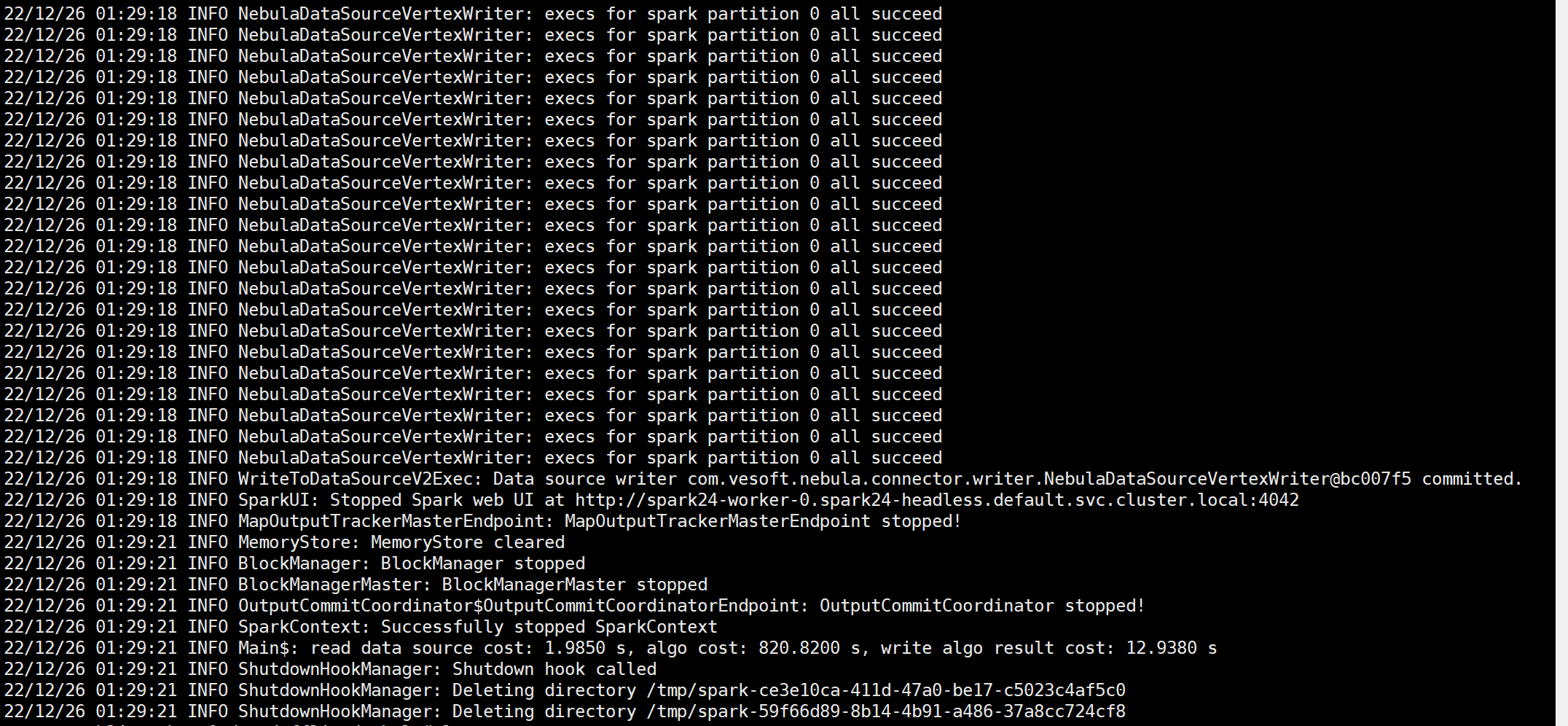
另外,我是12月24日和25日跑的时候,都出现了“insert vertex task abort”的错误,今天早上跑的时候没有出现。
猜测是数据量大 OOM 了;请问下建立过索引吗?
OOM了,内存不够了。加钱
好的 谢谢
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。