
2022 年是 NebulaGraph 采用火车模型发版本的第一个自然年。按照火车发布的节奏,在每个版本发布之前,提前约 1 个月时间,不再进入规划中的功能性 pr。在发布之前整个 NebulaGraph 的重点便是测试,全方位测试代码和功能的稳定性。
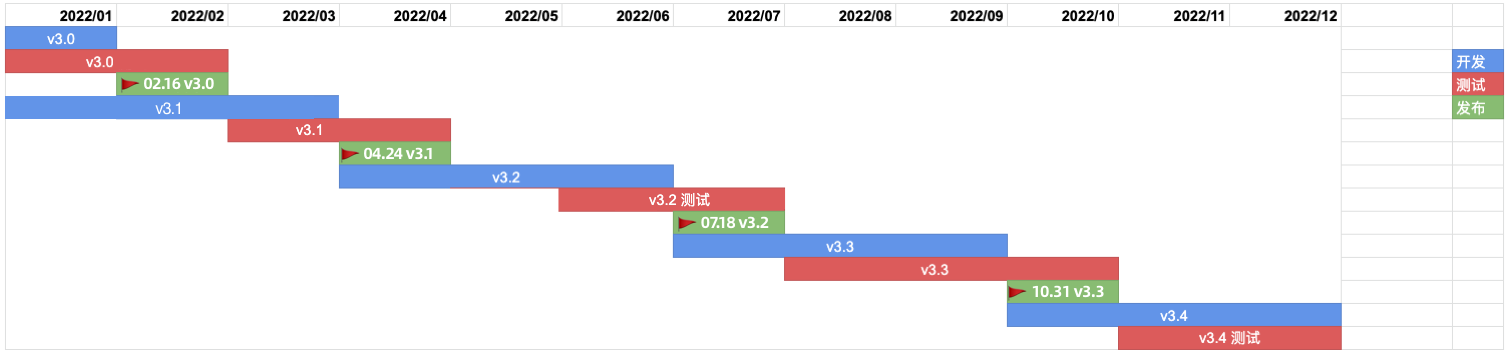
在过去一年,每个季度都一个中版本(x.y.z 的 y 值变化)同大家见面,看过上图的大家想必也知道,下一个版本 v3.4 正在紧密锣鼓地测试中,大家过好一个年就能见到它的样子了。那么这 4 个中版本中,有什么你不能错过的特性呢?
2022 年内核 Top10 特性
新增
- 新增备份与恢复工具 BR,参见:#3469、#1、#22
- 支持 openCypher 多 MATCH 查询,参见:#3519、#3318
- 新增存算合并版,参见:#3310
- 新增参数化查询,参见 #3379
- 使用
DROP SPACE之后图空间将进行物理删除,参见:#3913 - 新增不指定 VID 的查询,通过
LIMIT子句限制输出结果,参见:#3320、#3329、#3262 - 支持用
CLEAR SPACE清除图空间数据并保留 Schema 信息,参见:#3989 - 支持 extract() 函数
- 新增
KILL QUERY权限检查。当启用身份验证时,具有 GOD 角色的用户可以终止所有查询,而具有其他角色的用户只能终止自己的查询,参见:#3896 - 新增 distcc、sccache 等编译方式的支持,参见:#3896
优化
- 删除 meta 服务中的读锁以减少读写锁的副作用,参见:#3256
- 优化
GET SUBGRAPH和FIND PATH从而提高性能,参见:#3871、#4095 - 优化存储启动时的等待机制,保证与 Meta 服务及时连接,参见:#3971
-
GET SUBGRAPH支持点、边过滤,参见:#4357 - 存储层将写操作(
INSERT VERTEX或者INSERT EDGE)的并发控制,从报错并要求客户端重试,改为内部排队,以便客户端更简单适配,参见:#3926 - 优化路径以减少冗余路径和时间复杂度,参见:#4126
- 优化获取属性的方式进而优化
MATCH语句的性能,参见:#3750 -
MATCH裁剪优化,参见:#4523 - 增加优化规则,优化点、边过滤的下推,参见:#4270、#4260
- 优化了 k-hop 查询性能,
MATCH、GO、GET SUBGRAPH、FIND PATH等子句性能提升多倍,参见:#4560、#4736、#4566、#4582、#4558、#4556、#4555、#4516、#4531、#4522、#4754、#4762 - 使用 Arena Allocator 优化内存分配,参见:#4239
如果你对各个 NebulaGraph 版本的具体的 release note 有兴趣,可以前往 GitHub 页面阅读各个版本的信息:https://github.com/vesoft-inc/nebula/releases
2022 年 NebulaGraph Cloud
上面说到了 2022 年 NebulaGraph 内核变化,但 NebulaGraph 2022 年最大的产品动态当属云上 NebulaGraph——NebulaGraph Cloud,这是它今年的旅程:
- 2022.08 同阿里云计算巢合作,至此,国内的小伙伴可以不用再花资源费、“白嫖”30 天的图数据库,这里可以体验下免部署的图数据库的便利:我要试用 NebulaGraph
- 2022.09 开启 AWS AWS quick start 模式,海外小伙伴有了第一朵 NebulaGraph 云;同期,上线阿里云市场。
- 2022.11 上线 Azure 市场,为海外的小伙伴提供了更多的可选云服务厂商,点击用上 Azure。
- 2022.12 对接 GCP,提供 NebulaGraph 部署到 GCP 的能力。
由于篇幅的缘故,产品相关的 2022 年的精彩瞬间就此落下帷幕。想知道今年 NebulaGraph GitHub 提交了多少行代码?有多少新晋 commit 和 pr?社区数据将在下周的 NebulaGraph 社区 2022 年总篇里公布。