nebula graph版本:3.3.0
===========================================================
我想在ldbc数据集上做隐藏关系挖掘,看了思为老师的一边文章后,了解到需要用jaccard算法,计算节点之间的相似性。
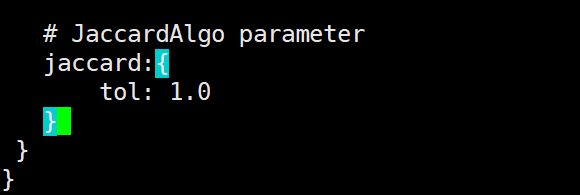
我尝试在application.conf中增加jaccard算法参数IDS1,结果还是一样。
1 个赞
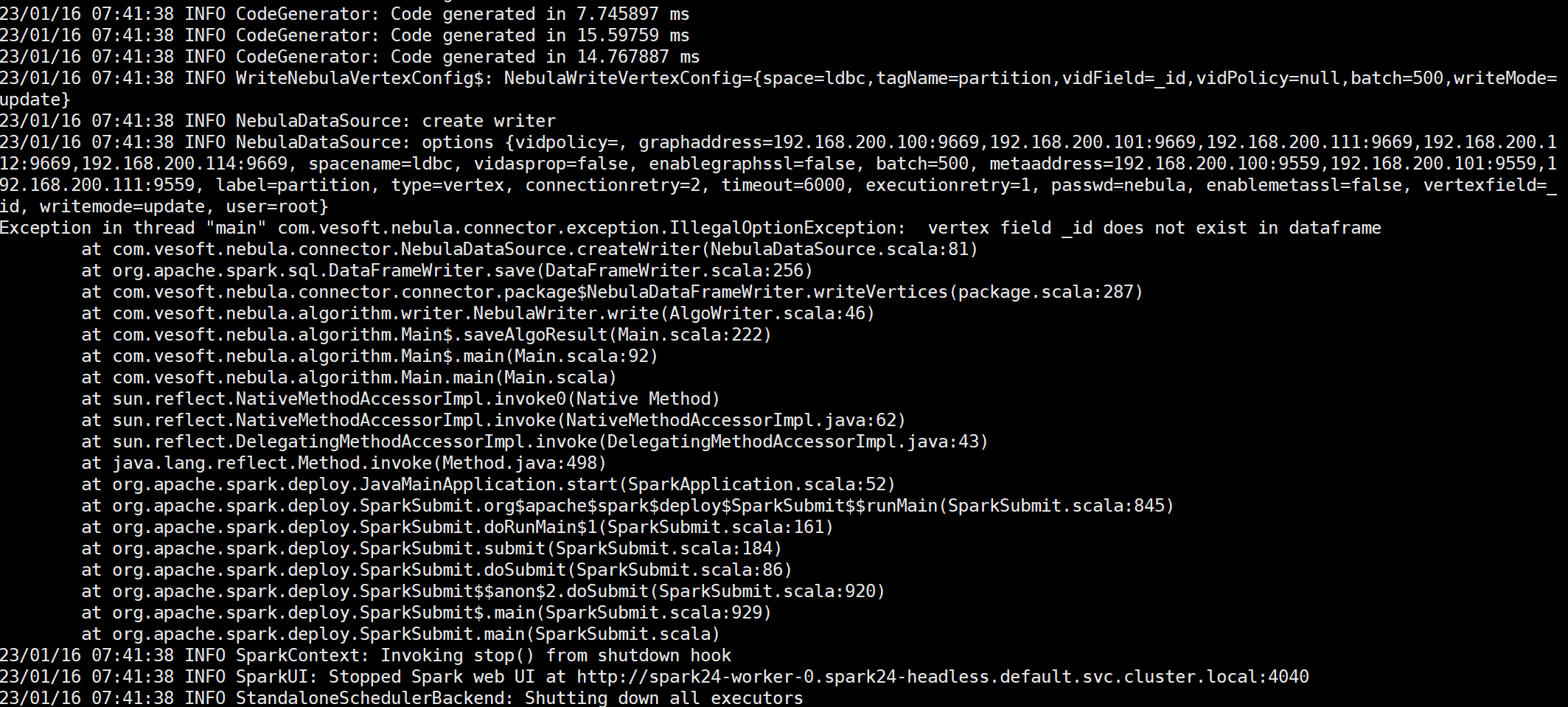
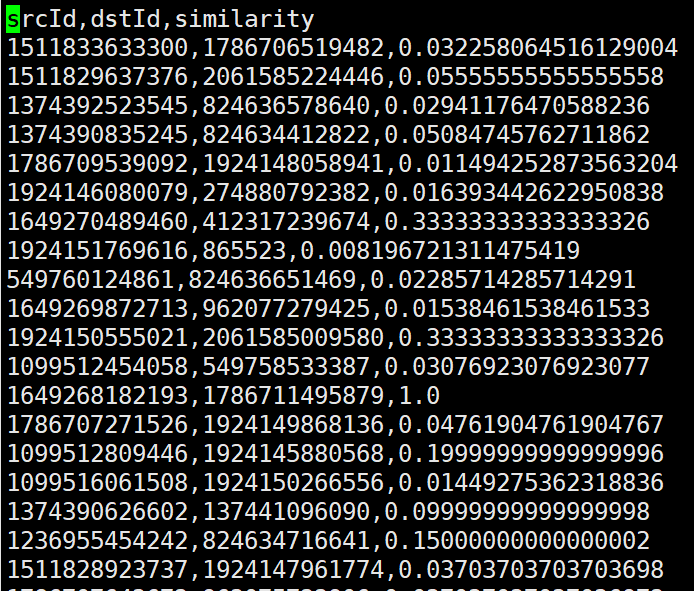
jaccard算法结果与其他算法不同,不是点id, 算法值的形式
所以该结果需要存入文件,不能直接存到nebula的tag中
好的 明白了!谢谢!
所以,想再问两个问题:
结果中 相似度有0.01的,也有1的,配置文件中jaccard参数tol设置的是1,我纳闷为什么不是只将相似值等于1的输出出来呢?tol的含义不是过滤掉小于tol的值吗?
如何让输出结果整合为一个csv,而不是多个呢?
2. algorithm没有暴露将结果进行repartition的配置,输出结果是按照结果dataframe的partition数来输出的,你如果是通过自己写代码调用lib算法的方式可以在输出结果前执行以下repartition(1)
1 个赞
system
2023 年2 月 13 日 03:08
7
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。