- nebula 版本:2.6.2
- 部署方式:分布式
- 安装方式:RPM
- 是否为线上版本:Y
- 硬件信息
- 磁盘:8x12T HDD
-CPU:40核
-内存:192G
- 磁盘:8x12T HDD
- 问题的具体描述
背景:在使用Nebula Spark Connector读取某些tag和edge时,数量会少于通过java客户端读取的数据量。spark在读取数据时会有什么限制吗? - 相关的 meta / storage / graph info 日志信息(尽量使用文本形式方便检索)
Java客户端代码
Spark客户端代码
结果:

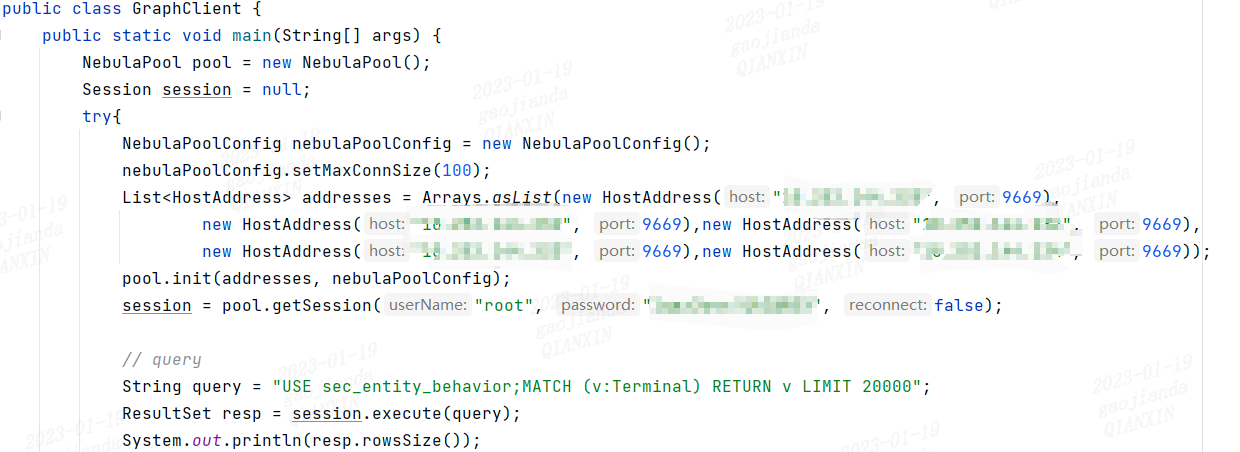
看代码截图,两者本质上都是用 graphclient(spark 并没有用存储接口),应该没有区别的,你使用 console 重复这个 match query 会得到不同值么?两者只是运行过一次么?还是稳定复现这两个不同的结果

spark每次读都会比java的少,但是spark每次读的数量是一样的。这个只针对某些tag或edge,不清楚是否数据中存在特殊字符啥的会不会影响spark的读
1 个赞
有意思,请问 show stats 的数据呢,Terminal 是 9139?
@steam 得麻烦请出存储小伙伴才行了![]()
![]() 想象不出来怎么能存储扫了缺点,spark 上指定了单个 meta,难道可能从非 leader 的 meta 获取的 storage leader 分布可能是过期的,然后非 leader storage part 里有缺的数据被扫了?
想象不出来怎么能存储扫了缺点,spark 上指定了单个 meta,难道可能从非 leader 的 meta 获取的 storage leader 分布可能是过期的,然后非 leader storage part 里有缺的数据被扫了?
2 个赞
Java客户端和show stats的数量一样,是正确的总数9139。这两类应该是同一类扫描机制。但spark对某些tag和edge的扫描就会出现数量少的情况,本例就是9117。这两个的扫描机制底层逻辑应该不一样吧。
是的,spark 是 stroage client ,query 是 graph
最后在storaged端调用的函数都是scanVertices。所以@wey的猜测是合理的。能否换一个meta试试呢?
1 个赞
![]()
换meta节点确实读的数据不一样,但还是少。
说明不同meta节点之间数据确实存在不一样。注意“ withMetaAddress” 需要包含所有meta节点。
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。