- nebula 版本:2.6.2
- 部署方式:单机
- 安装方式:利用tar包安装
- 是否为线上版本:N
- 硬件信息
- 磁盘( 推荐使用 SSD)
200T - CPU、内存信息
CPU:64核intel处理器,Intel(R) Xeon(R) Gold 6346 CPU @ 3.10GHz
内存 :MemTotal: 230231724 kB
- 磁盘( 推荐使用 SSD)
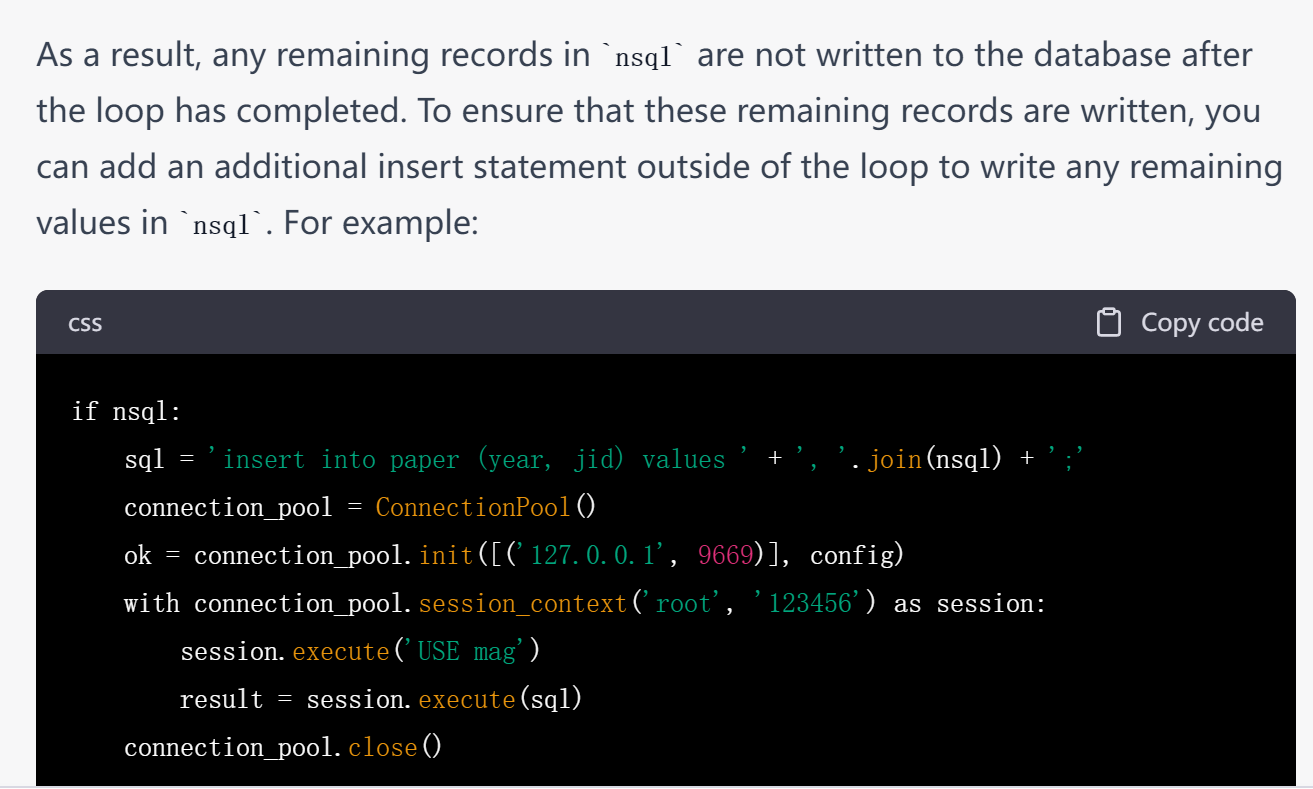
在学校的CENTOS8服务器上使用nebula2-python包(nebula2.6.2)。在小数据集上的测试一切都没有问题。当试图导入一个大概4千万个点的数据,发现当导入到10万个点后,后台统计值始终停留在10万,不再接受新的值传入。
python代码如下
config = Config()
config.max_connection_pool_size = 30
n=0
nsql=[]
with open('./unique_data/Papers_unique_journal.txt','r')as f:
for line in f:
tmp = line.strip('\n').split('\t')
n+=1
flash_print(n)
doi = tmp[2] if tmp[2].strip() else 'NA'
nsql+=['%s:(%s,%s,)'%(tmp[0],tmp[11],tmp[7])]
if n%10**6==0:
sql='insert vertex paper(jid, year,) values '+','.join(nsql)+';'
connection_pool = ConnectionPool()
ok = connection_pool.init([('127.0.0.1', 9669)], config)
# option 2 with session_context, session will be released automatically
with connection_pool.session_context('root', '123456') as session:
session.execute('USE mag')
result = session.execute(sql)
# close the pool
connection_pool.close()