nebula 版本:3.2.0
部署方式:分布式 :3台节点:graph,storage,meta *3
安装方式:RPM
是否为线上版本:Y
硬件信息
磁盘:SSD
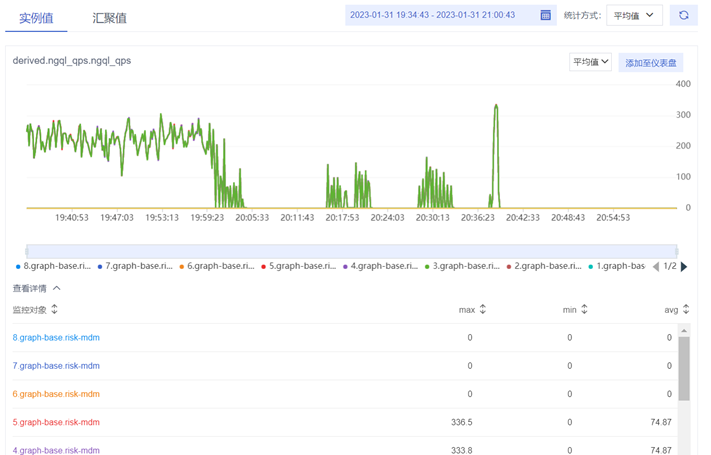
如上图,使用多进程对图服务进行压测,当图库的QPS保持稳定之后,执行SST文件入库。
然后发现QPS下降了,开始不断震荡,最后所有进程都被阻塞,图库QPS降至0。
接着我重启了压测进程,开始有了QPS,但进程还是过一段时间被阻塞了。直至整个SST入库阶段(持续40分钟)结束后,压测进程才正常。
以上是我执行大图入库的情况,小图以SST方式入库没有影响。
请问这是什么原因?
之前使用drop space 的时候也产生过进程阻塞的情况,已经有大佬解答了是锁竞争的影响。执行SST文件入库的时候也会产生锁竞争吗?
1 个赞
请问SST文件入库具体是怎么操作的呢?但通常情况下,写入数据是会影响到读的性能。这里面CPU,内存,存储资源都有可能存在竞争。但是可以通过控制写的并发数,降低rocksdb compaction的线程数来降低写的影响。当然具体还需要你提供更多的信息,比如graphd和storaged配置信息,怎么导入SST的,机器配置等。
1 个赞
可以问一下QPS为0的时候,磁盘IO情况,内存和cpu占用率分别多少?
就目前来说,使用exchange导入,可能会由于存在大量key range重复的sst,导致数据都被加到了rocksdb的L0。这时候可以看一下storaged的LOG,是不是存在很多compaction。compaction是会消耗cpu,内存和磁盘资源,也会挤占read。
1 个赞
磁盘IO挺高的,每秒写入平均20wKB左右。CPU占用率是30%。看日志是存在很多的compaction。
日志为以下内容:
I20230131 19:55:18.139950 134141 EventListener.h:21] Rocksdb start compaction column family: default because of LevelL0FilesNum, status: OK, compacted 5 files into 0, base level is 0, output level is 1
I20230131 19:55:18.140004 134141 CompactionFilter.h:92] Do default minor compaction!
I20230131 19:55:18.846747 204353 IngestTask.cpp:38] Ingest files: 9
I20230131 19:55:22.446081 204353 IngestTask.cpp:38] Ingest files: 9
I20230131 19:55:25.980226 204353 IngestTask.cpp:38] Ingest files: 9
I20230131 19:55:27.778008 134141 EventListener.h:35] Rocksdb compaction completed column family: default because of LevelL0FilesNum, status: OK, compacted 5 files into 6, base level is 0, output level is 1
我入库小份的图时也会触发comapaction,但是不会阻塞查询。入大图的时候就会阻塞了。这种情况怎么避免…
@Tsukiwan 为避免上述问题,你在用exchange生成sst文件时,可以把repartitionWithNebula配置设置为true,这样生成的sst文件之间就不存在key range的重叠了。
大佬。我可以理解为key range重叠会导致compaction,进而影响到read。避免大量compaction的方法就是设置repartitionWithNebula这个重分区参数对吧,
是的,但不能完全避免。下面举两个极端情况:
当你的space是空的,你配置repartitionWithNebula为true,此时生成的sst文件被ingest后可以直接落到rocksdb的L6(最底层),就不需要执行compaction了。
当你的space有数据,且L0有sst文件,且exchange生成的sst文件的key range与L0已有的sst文件有重叠,那么 exchange生成的sst文件被ingest后就会落到rocksdb的L0,compaction操作就比较重了
1 个赞
哦哦。所以说比如创建一个新图,第一次入全量数据的时候可以避免。但是以后入增量数据时,就很难避免compaction了对吧。
如果以后都是通过exchange生成sst来写增量数据,可能第二次sst文件ingest后就落到L1,第三次落到L2。。。。
XDH
11
我们使用client模式入库就不会出现这种大量compaction影响query的情况,请问这是为什么呢
system
关闭
13
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。