nebula graph版本:3.3.0
nebula studio版本:3.5.0
spark版本:2.4
部署方式:分布式
硬盘:机械硬盘
是否为线上版本:N
===========================================================
我在使用python连接nebula的时候,执行如下代码:
from nebula3.gclient.net import ConnectionPool
from nebula3.Config import Config
import pandas as pd
from typing import Dict
from nebula3.data.ResultSet import ResultSet
def result_to_df(result: ResultSet) -> pd.DataFrame:
"""
build list for each column, and transform to dataframe
"""
assert result.is_succeeded()
columns = result.keys()
d: Dict[str, list] = {}
for col_num in range(result.col_size()):
col_name = columns[col_num]
col_list = result.column_values(col_name)
d[col_name] = [x.cast() for x in col_list]
return pd.DataFrame.from_dict(d)
# define a config
config = Config()
# init connection pool
connection_pool = ConnectionPool()
ok = connection_pool.init([('192.168.200.101', 9669),('192.168.200.100',9669),('192.168.200.111',9669),('192.168.200.112',9669),('192.168.200.114',9669)], config)
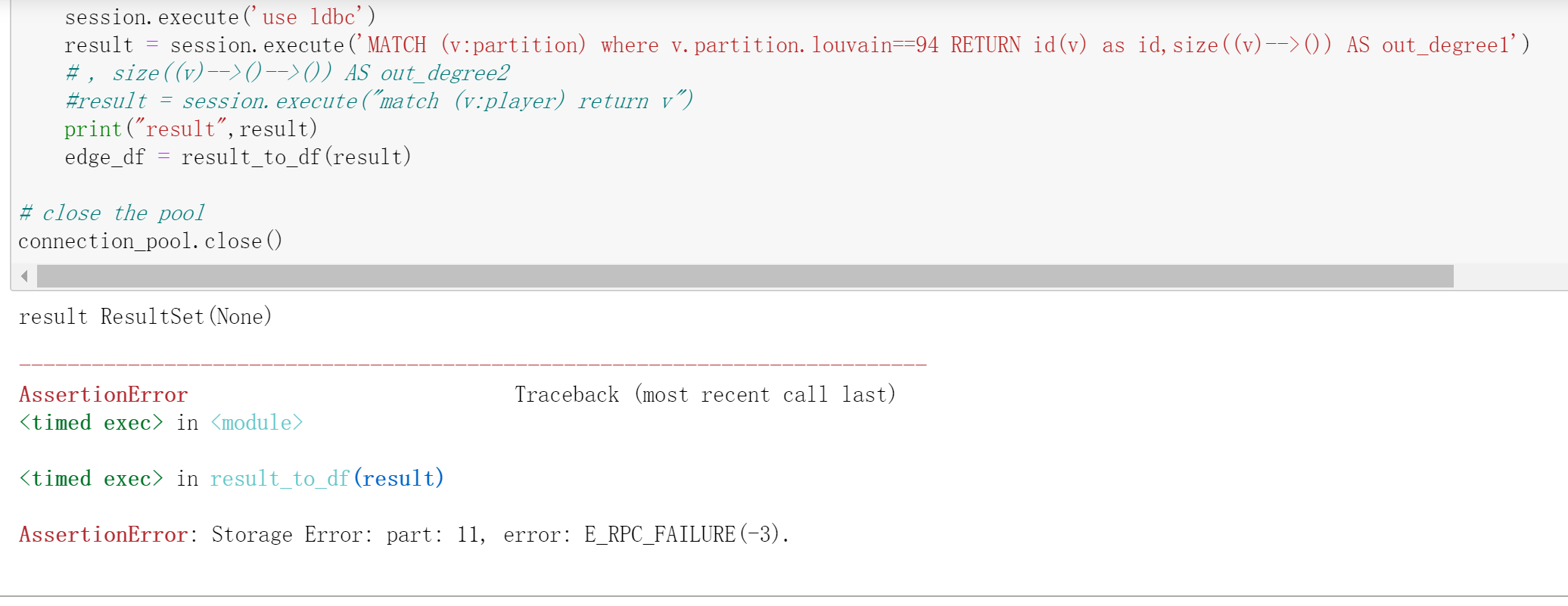
with connection_pool.session_context('root', 'nebula') as session:
session.execute('use ldbc')
result = session.execute('MATCH (v:partition)-[e:LIKES]-(v2) where v.partition.louvain==94 RETURN id(v) as id,size((v)-->()) AS out_degree1, size((v)-->()-->()) AS out_degree2')
print("result",result)
edge_df = result_to_df(result)
# close the pool
connection_pool.close()
出现错误:

这是获取不到数据吗? 我在basketballplayer数据集上验证这个语句是可以执行的,是不是因为ldbc数据量大的原因?如何解决这个问题呢?